The HCP Vision & HCP Packer
HashiCorp Co-founder and CTO Armon Dadgar unveils a new service for the HashiCorp Cloud Platform: HCP Packer.
Speakers: Armon Dadgar, Megan Marsh
HCP Packer is machine image management as a service. Learn more from lead Packer engineer Megan Marsh and Armon Dadgar, who will also take a look at the state of our other HCP offerings including HCP Consul and HCP Vault.
»Transcript
Armon Dadgar:
Thank you so much to our hosts for the warm welcome. And welcome everybody to Day Two of HashiConf Europe. Yesterday's keynote was all about Terraform and provisioning. Today's keynote is going to be all about Cloud.
»Cloud Delivery is the Future
I feel like I'm preaching to the choir here — given the HashiConf audience — when we talk about Cloud delivery as being the future. I think going all the way back to the beginning and the mission for HashiCorp, we've always been focused on enabling Cloud infrastructure and automation around it.
All of our tools have been designed for: how do we build modern applications in a Cloud setting and do it in a way that's automated? At the same time, I think the disconnect here is that we've traditionally been a desktop software vendor. People have downloaded our tools, installed them on their laptop, run them locally. For our runtime software, they've downloaded and self-managed it themselves. So increasingly, we've been asked by our users and by our customers to make that transition into being a Cloud vendor ourselves. They want to consume this and consume HashiCorp applications as fully managed versions — as SaaS apps.
We've been on that journey for a few years. We started this with Terraform Cloud, and we spent a lot of time talking about this yesterday. But we're very excited around the adoption and growth of Terraform Cloud. Today it counts over 120,000 users. It adds over 5,000 new users a month, and we do well over 30,000 Terraform runs a day. Super excited to see the adoption, growth, and traction around Terraform Cloud. That was our first stop.
From there, it was a transition into the actual runtime products, and here's where we partnered closely with Microsoft and Azure. We announced in September of 2019 the HCS service on Azure. That service went generally available in the middle of last year. This was dipping our toes into the water of providing a fully managed service around Consul and around a runtime product.
»The HashiCorp Cloud Platform
Now, the feedback we got from HCS is that we loved that managed experience, but what about all the other environments we operate in? This ultimately led to our development of the HashiCorp Cloud Platform. We announced the HCP platform this time last year at the same conference. The idea behind HCP is that it would be a fully managed platform to automate infrastructure across any cloud. The goal is that this becomes the common layer for us for delivering all of our products as a managed service.
The feedback on this has already been great — as we've shared it with people, and people have experimented with it. It's exactly what we want to hear, which is: HashiCorp created the easy button. It's everything from, "Great. Now I don't have to learn how to stand this up and manage this," to — for small engineering teams — "This is a godsend we don't have to deal with having dedicated staff — dedicated to thinking about standing this up and operating it at scale." It's really about eliminating that overhead. Making it easier to get started. Making it easier to adopt these tools. Ultimately, we want people to feel spoiled by the experience. That's sort of the goal here.
»Push-Button Deployment
If we take a step back and say, what were the goals for us? The first is that push-button deployment. We want you to easily be able to come in, click a button, and a few clear choices later, have running infrastructure that you can start adopting right away. That push button’s really important.
»Fully Managed Infrastructure
The second part of it that's critical is that it's fully managed. This is not meant to be a quick start to get it stood up and then the lifecycle is your problem. This should include everything from how do we do backups? How do we do upgrades? How do we do restores if needed? How do we manage outages, give you visibility, telemetry, etc? It's a truly, end-to-end fully managed infrastructure.
»One Multi-Cloud Workflow
Then lastly, it's thinking about: how does this become the way we deliver a consistent multi-cloud workflow? Whether you're running Vault in one Cloud or a different Cloud or all of the Clouds at the same time, how can we give you a consistent way to do that? Really thinking around what that experience is across these environments.
While HCP is designed to be this chassis — this mechanism by which we deliver the products – it's also meant to be an enabler of this— I'll call it — one plus one equals three. As we add new capabilities to the core platform, all of the products on top inherit that. It's not just about the products themselves. It's about extending the platform’s core capabilities. And that comes and flows down to the products so that this should be the best place to operate HashiCorp software.
»User Experience
There are a number of areas where we invested around core HCP. One of these is user experience. Early on with HCP Consul — once we'd launched it — the user feedback was that there was too many steps. It was too difficult to get started. Even though it was push-button, there were too many buttons to push.
We were able to work with user research, figure out what users really cared about, and simplify that down to a quick start that was a few steps rather than a dozen choices. This is the experience we want to be able to drive — and having that HCP platform lets us do this.
»Operational Excellence
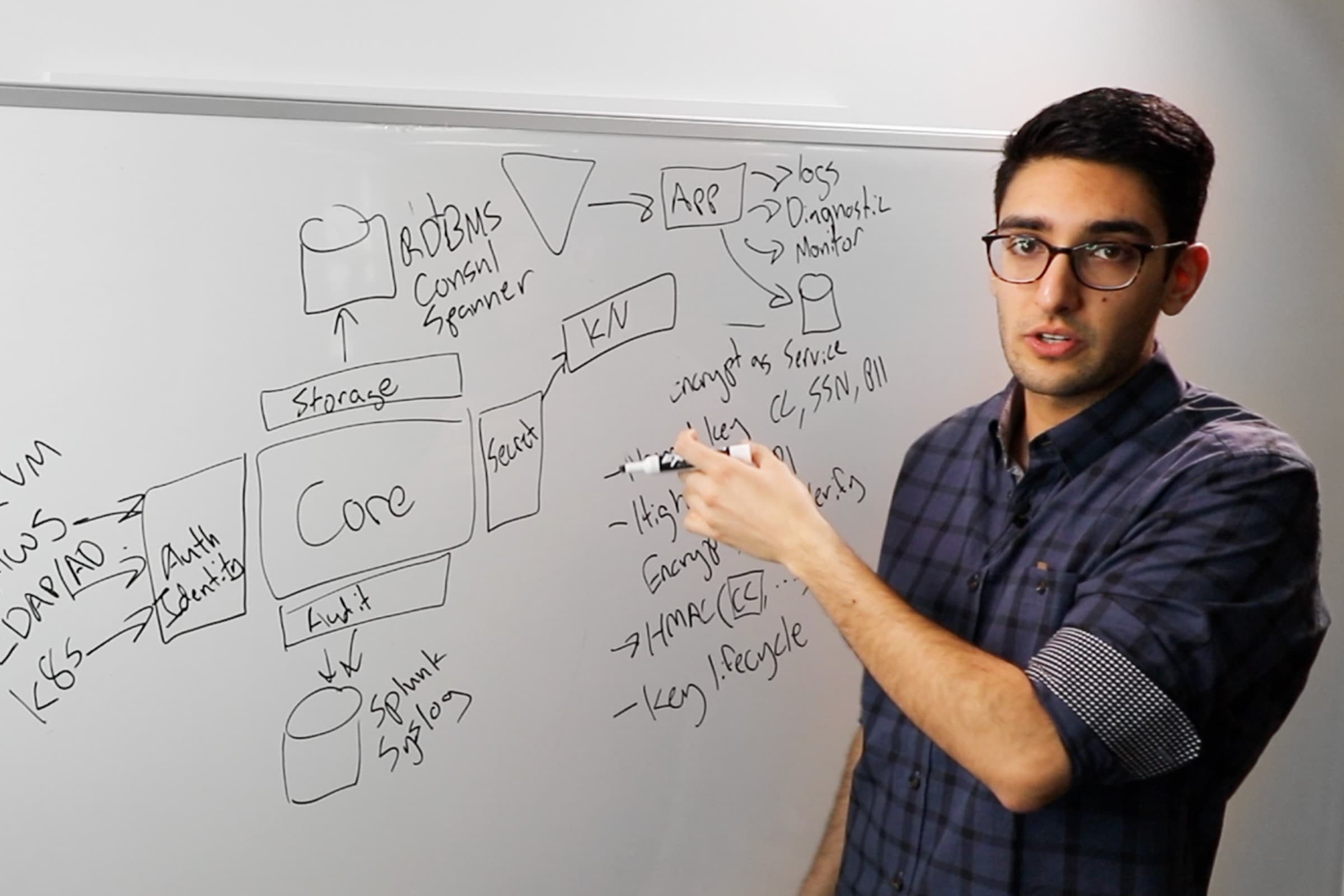
We realize that this software is tier-one. These are the services that underpin the rest of your infrastructure — the rest of your applications — so they have to be highly reliable and highly available. We're focused a lot on the operational excellence of the platform, but going one level deeper: How do we expose detailed audit logs for our users so they can understand how the tools are being used? How do we give better visibility through clear metering and clear billing data?
Then, how do we go all the way down to control plane and data plane to give you visibility through integrated metrics and telemetry? So, as you think about running this tier one software, it's not just that it should be available, it's that you understand it, you're able to debug it, and you have confidence in the way it's being operated.
»Security and Governance
Then lastly, is really thinking about the security and governance challenges. Our customers expect to run this mission-critical software in mission-critical settings. So they're subject to a high bar of security and regulatory and governance requirements. So, we want to make sure that this works for those users who have these challenging requirements.
This is why we're working with partners like Okta and Azure ID to support single sign-on and multi-factor authentication. That's why we're working on things like SOC 2 certifications. And we'll work through adding more and more of those validated, certified environments so that you can use this in the most stringent of environments.
»HCP Consul
We've focused on making HCP a fantastic platform — a fantastic place to run things – but that's just to enable the products that are running on top. The first product we launched was HCP Consul. It went generally available this February. At the time, we included an hourly SKU for development, as well as a single production standard SKU.
When we talk about operational excellence, we extend it beyond the platform. It's about the products themselves, as well. Consul is a great example of where we focused here. We did a benchmark earlier this year that we called the Consul Global Scale Benchmark.
We stress-tested the system across 10,000 nodes and 170,000 services to see how quickly it could respond to changes in security policy as we add and remove services. Basically, as things change, how quickly are we able to propagate that update and keep the system up to date everywhere? We saw — even with five Consul servers running across all of these hundreds of thousands of services, tens of thousands of nodes — we were still able to reliably deliver these updates in sub-seconds at this incredible scale. We have a lot more details you can read about on this benchmark page.
»New SKU Options
You can see that things like scale are a big investment area. But where else are we focused on? Some of the feedback we got was that having the development and a single size production SKU wasn't enough, There were other needs. There were other challenges people were trying to solve. We're going to be expanding that to include additional options. There'll be a higher end plus SKU that's looking at the more advanced, larger scale configurations and deployments, as well as a more entry-level for production environments where you still want production-level guarantees and features. But you're not yet at the scale that needs a higher set of capability. It gives you an ability to grow into it over time.
»AWS Transit Gateway
What are some of these capabilities we're starting to add? One big one we've heard is that we need more than VPC peering. As we have these complex network topologies, a very common pattern is the AWS transit gateway. The idea is you can have a single point of ingress and egress and pier to all of the different systems that you need — this is something we've been focused on supporting. This will now be added — not just for HCP Consul — but integrated into the HCP platform itself so that other products will be able to benefit from the AWS transit gateway pattern, as well.
»Multi-Cluster
The other feature — and this will be available in the higher end plus SKU — is looking at the inter-region federation. You might have situations where you have multiple Consul clusters running within a single region. I might be within U.S. East and I have cluster A and B that belong to different application teams, as an example. Those things can federate with one another so that traffic and discovery can flow back and forth between them.
Now, as we go to a bigger global scale, there's a need for multi-cluster federation across geographies. This might enable a Consul cluster running on the West Coast to talk to a Consul cluster running in the UK and allow traffic and discovery once again to work across those different boundaries.
These enhancements are coming both at the underlying HCP layer to enable that linkage of the network between these different areas, as well as the application layer for the HCP Consul to expose that capability.
»Consul 1.10 Release
In addition to the updates around HCP Consul, we've been continuing to focus on Consul itself. We're very excited for the upcoming 1.10 release. This is going to bring a bunch of new enhancements. The one that I'm most excited about is the transparent proxying capability.
As users adopt service mesh, one of the challenges is having to have applications update to be mesh-aware. With transparent proxying, instead, all of the traffic flowing in or out of the application can be transparently intercepted so we can start to adopt and roll out a service mesh without the applications being aware. Hence, the name transparent proxy.
I'm very excited for what this is going to enable. We have deep integration with Kubernetes and other environments to make it a lot easier to roll out a service mesh. At the same time, there are a lot of improvements around observability and telemetry — so that for developers, they get a better sense of what's happening with their applications.
»HCP Vault
The second service that we brought was HCP Vault. This is a much newer service that only went generally available in April. And very similar to Consul — where we started with an hourly SKU — both for a developer instance, as well as a standard production SKU. Really looking at giving you those options right out of the gate.
Since then, we've seen tremendous interest in HCP Vault. Since the announcement of our beta, we've had over 2,300 live clusters launched and over a thousand signups for the service itself. Super excited to see all the momentum and community interest and people starting to use this in earnest.
HCP Vault is also a great example of what we're trying to achieve with the fully managed lifecycle management. We've already been able to update customers from Vault 1.6 to 1.7 without any downtime — without them having to be aware and involved in that upgrade process. That's exactly what we want to be able to deliver on.
I think part of the reason we're excited about HCP Vault is even from small to the biggest customers in the world there's the clear benefit to the simplicity of operations that you get. We love to get this feedback from Lufthansa. It's a customer of ours sharing that it was the simplicity of this that enabled them to get going. And it's a critical part as they're thinking about embracing a zero trust architecture for their applications.
Looking forward, we're making a number of changes to the HCP Vault SKU. Very similar to Consul. I think what we've heard loud and clear is there's a need for more flexibility. This will include a lower end starter SKU for folks that need something that's production-worthy — but doesn't have quite all the same requirements as the standard SKU — as well as our customers on the higher end who want the additional capabilities that Vault has in the advanced data protection and KMIP, and tokenization features — as well as the need to span multiple regions, multiple clusters.We'll be expanding the different SKUs that are available, so there'll be an option for everyone, regardless of what size or capability set you need. And very similar to Consul, that higher end plus SKU is going to enable the federation capability. You might have a Vault cluster in the West coast, a Vault cluster in London. Those can be linked and replicated against one another. We'll also enable things like disaster recovery scenarios. There's a bunch of capability that's going to be exposed through this federation, much like self-managed Vault clusters today.
We're super excited for what we've accomplished so far. There is a lot more yet to be done on top of HCP. That's because HCP is really the vision for the company. We're continuing to bring more and more services and more and more capabilities to HCP.
»HCP Packer
Today, I'm super excited to share the details on the upcoming HCP Packer work. This will be the first time Packer has any capability added as part of HCP — and the first piece that we're going to talk about today, and the first thing that we'll be launching, is a registry.
»Packer Registry
We talk about this registry. What challenge are we trying to solve? For folks who may be less familiar with Packer, the heart of what it's trying to do is provide a consistent workflow for building machine images or container images through an infrastructure as code-defined pipeline. This might start with raw source code, configuration management, security, and compliance controls. All those get consumed in a codified way through an infrastructure as code declaration that Packer then executes to create identical images across these different environments. This might mean creating a container image, an Amazon AMI, and VM image for on-premise environments, etc.
One of the common challenges with this is I generate all these images, but how do I manage them? I have all this metadata around, which Git commit generator or which images? How do I deal with the versioning of this? How do I know if an old image has a security vulnerability and shouldn't be used anymore? Etc.
That's exactly the set of challenges we wanted to solve by creating a registry built for Packer. This will be part of the HCP Packer offering. The service will fill in that gap. Once Packer builds those images, all of that metadata will get stored within the registry — so you can see all of your different images, the versions that have how they were built, etc. Then, you can query that in an API-driven way.
That will enable things like Terraform — and you can see this code snippet here. Or we can use a data source to directly query the artifact registry and say, "I need the latest version of this particular image." This allows you to start linking these tools together, building images with Packer in a consistent way, importing them with Terraform — and consuming them and letting the registry act as that filler in between that to manage all of the metadata on your behalf. This service is going into private beta in the coming months. If you're excited and interested and want to participate in this, I recommend signing up — and we'll let you know when it's ready for wider use.
»HCP Packer Demo
With that, I'd like to invite Megan, who's the lead engineer on HCP Packer to give us a demo. Take it away, Megan.
Megan Marsh:
Hi Armon. Thank you so much. Like Armon said, my name is Megan, , and I'm excited to talk to everyone today about what my team has been up to bringing Packer-related workflows to the HashiCorp Cloud Platform.
For those of you who don't already use Packer, it's an open source tool for creating identical machine images from a single source configuration on multiple platforms. It's a purely open source tool and it's the industry standard for automating the creation of golden VM images.
But, that's not the end of the story once you've created the image. Once created, users have to provision instances from those images, and figuring out which image to use can be deceptively complex. So last summer, my team started thinking about how we could begin to work on solving some of the pain points that our users face when they're using Packer at scale in a complex organization.
We didn't feel that sticking the Packer images themselves up into HCP was going to be a huge game changer for our customers. We wanted to focus instead on resolving common pain points that our customers feel. We decided — for now — what we want to do is focus on extra tooling that enables people to more easily source and use Packer images.
»HCP Packer Registry
Our first tool in the HCP Packer toolkit is going to be the HCP Packer registry. This registry will track your images from creation to validation, promotion, production, and then to deprecation and ultimately instance destruction. So that you know at any given time what image is being used, what image you should be using next, and whether your current image is up to date. To give you an idea of why this is valuable, I'm going to quickly step through a common factory workflow and show its gaps.
Companies build their images in layers. That means that they start with a basic security-hardened image and then they build a second image using that first one as a source. They add project-specific dependencies on top of that base. So, one project built off of the base may have Java installed and another may have Python as a requirement — and one project may be using on-premise VMware installations and another might be split equally between AWS and Google compute.
»Dealing With Branching Dependency Trees
You end up with these branching dependency trees with the secure base as a root. This can make images,and what image to use next, opaque — as an end user — when you're trying to determine which base to use, which layer to use. If there's a tertiary layer on top of that, which one of those to use? Has the base changed since you rebuilt your last layer? Has an intermediate layer changed? And which version? Which build of all of those things should you be using if you're in production versus dev?
We wanted to resolve this by adding tools that allow your Packer templates themselves to reach out and ask what version of an image it should be using. Instead of hardcoding and AMI ID or passing in an environment variable, Packer can reach out to the HCP Packer install — and the HCP Packer registry specifically — and ask what's the AMI ID that's been validated as production-stable that I should be using in the secondary image build? You'll be able to use your own image release channels — that you define — so that your builds can specifically use either development or stable — or whatever you decide — image basis.
»Creating a Complementary Terraform Data Source
We can do this using data sources, which are concepts that we borrowed from Terraform and implemented in Packer in the HCL templates that we've created. And knowing that we're using data sources for this under the hood, probably it's no great surprise to you that then we can create a complementary data source for Terraform.
This means Terraform can reach out to the Packer registry in HCP and ask for the latest version of the image that it should be using to deploy instances — not only Packer building its own images.
»Seamless Integration into Existing Workflows
It’s important that we integrate Packer and HCP Packer seamlessly into your existing workflows. In order to use the registry, you don't need to change your core template. All you need to do is tell Packer to pass the metadata up to HCP Packer. You'll do that by simply setting a couple of environment variables and Packer will handle the rest for you. Thank you so much. I hope your HashiConf Europe is amazing and Armon back to you.
Armon Dadgar:
Thanks so much, Megan, for walking us through that. As the name suggests HCP Packer will be an integrated part of our Cloud Platform. It's going to inherit all the benefits of shared identity, shared billing, and all of the Platform capabilities. As Megan said, we're now taking signups, so if you're interested in participating in the beta, go ahead and register for that.
If you want to learn more from Megan, and our plans for an upcoming Packer 2.0, check out her breakout later today as well.
As I mentioned upfront, we're continuing to invest very heavily in Cloud services. Today we have Terraform Cloud, HashiCorp Consul Service on Azure, HCP Consul, and Vault — and today we announced HCP Packer, as well.
We started this journey with HCP on AWS, but we're going to add support for Microsoft Azure and Google Cloud Platform, as well. Really going back to the idea of a single multi-cloud workflow.
If you haven't yet signed up for HashiCorp Cloud Platform, it's free to do so. Every new user gets $50 in credit. You can use that right away to start playing with the development SKUs, kick the tires on these services and get a feel for it.
These are definitely early days for the platform. We're just getting started, so we'd love to hear your feedback on what you'd like to see added or what we could be doing better. With that, thank you so much. I hope you enjoy the rest of HashiConf, Day Two.