Modern Application Delivery Lifecycle
Armon Dadgar explains how HashiCorp applies a set of infrastructure management principles to the application delivery lifecycle including provisioning, securing, running, and connecting applications.
Hi. My name is Armon Dadgar, and today I want to talk about application delivery with HashiCorp. So when we talk about what our mission is at HashiCorp, what we're always talking about is the full process of delivering an application.
And what we mean by that is from the time we write our last line of code to the entire journey of taking that source code and delivering into a production environment.
One of the things you'll see over and over again when we talk about our tools is really a focus on what are the core fundamental workflows in the process of delivering an application. And not the specifics of the technology. And this is something that's really near and dear to us, is that focus on workflow orientation and not technology focus.
And you'll see what I mean as I talk about this. So when we talk about application delivery, what we do is we think about it in terms of what are the steps that we must necessarily do to deliver an application?
So, so far we haven't found a way around it, we have to write our application. Ideally, we should be testing that application. Then at some point, we start leaving the realm of development, and we have to package it. This is where the rubber really meets the road. And here we start going from just the source code that we had earlier to know to bring in things like configuration management, bringing in various security controls or compliance controls that we might have. And what we're hoping to do is to take all of these and transform them into something that is a production worthy image.
So, this might be running and staging, might be running and production but we're kind of leaving now the environment of Dev-Test.
The next challenge we have once we've packaged our application, is how do we do provisioning? And so when we think about provisioning, there area really two different challenges here. There is day one when we have nothing running, and we need to go from nothing to something. And then we have day two plus. So now that we have infrastructure running in production, let's say, how do we continue to evolve that?
Because our view is that infrastructure is almost like an application. It's a living breathing thing that you're evolving day over day, week over week. And so in many ways this day two challenge is actually much more important and much more challenging because now we're actually in production. So, this is what we think about in provisioning. Then as we go further along, our next challenge in deployment. So, how do we take an application that we have packaged and map it onto a set of compute that we have provisioned?
Depending on the way we deliver our application, provisioning and deployment might be one in the same. So, if we're baking our application in, and potentially into an application Amazon Machine Image (AMI), or a cloud image or maybe VMDK, then the act of provisioning that VM might be the same as deploying. But, if what we're provisioning is a stem cell machine, a blank VM running Linux and then we're using configuration management to specialize it as a web server or we're containerizing out applications and deploying it using a scheduler or other orchestration tooling, we might think about the deployment process as being distinct from the provisioning process.
But, in either case, whether deployment is part of provisioning or its own step, it's a fundamental step in delivering the application. Once we've done the deployment, then we need to monitor it. So, now that our app is running how do we make sure it stays up and running? And so when we talk about monitoring, this is its own universe of tooling. This is everything from logging to telemetry to tracing to health checking and alerting.
And really the goal here is two-fold. It's once our application is in production, we want to know will we be notified if something goes wrong? There's a service outage, customers can't reach the site, something bad is happening, and it's impacting user-facing services so we'd really like to be alerted.
The next thing is really realizing that on a large enough scale any production system is a black box. We can't possibly understand how the whole thing works. So, what we really care about is, do we have enough observability, the ability to have enough probes and hooks into the system to understand what's done wrong once we get alerted.
So, we get an alert and then we want to make sure we have enough of this observability data to figure out what do we need to do to remediate it and get the system on-line again?
The last part of this whole thing is secure. So, traditionally this might have been sort of the final bolt on step at the end of our pipeline. Now that we're in production how do we harden this thing?
But, what we found over time is that this assumption is changing because the implication of staying secure as our last step is that every step before it was not secure. And really security has a tendency to flow like water. It finds the path of least resistant. So, if we bolt it on and said, "This is our hardened front door." Then as an attacker, I'm going to go to one of these other parts of the pipeline which are inherently insecure.
So, what we really have to do is think about security throughout this entire pipeline and make sure that we're conscious about it and ensuring that we don't have the weakest link problem here.
So, these end up being the essential workflow steps. So, as we think about delivery an application, it's clear why removing one of these things all of a sudden makes it less sensible. It doesn't make sense to deliver an application and remove one of these steps. At the same time, these might not be the only steps. So we realize some organizations might have static code analysis that they do after testing. Or they might have a package management system over here. Or they might use a CNDB to keep track of all of their inventory.
There are these other steps that might get added to delivering an application specific to each organization, but you can see that they're not fundamental. I can deliver an application without using static code analysis. It's much stranger to delivering an application without ever provisioning infrastructure.
And so this is how we see it as being the seven pieces we must have. And one thing, you'll notice that I haven't talked about technology at all. This is not specific to Windows or Linux or Java or C Sharp or Docker or Monoliths. This is in general required for any application.
And so you'll see over time, HashiCorp. has the strong focus on the workflow over any particular technology. Our view is that all of these tools should be adaptable and flexible enough to bring whatever technology makes sense for you. So, as we think about tools now, this is then how we think about what each of our tools is focused on. HashiCorp. has very much a tight UNIX philosophy. So, we believe in the notion of doing one thing and do it well. And so, this UNIX philosophy ends up showing up as a whole collection of tools.
So here is where we would put Vagrant. So, Vagrant sits at the right in the test phase. And what we're really trying to do is provide a developer environment. So either a local VM or Dockerized environment that gives us something that looks like production.
So we have sort of Dev-Test parody with what our production environment looks like and this is to avoid the scenario of, I developed it on Windows on my laptop, deployed into Linux in production and now whoops it doesn't work.
How do we get as close to this as possible? And the way we do this is by codifying this in a Vagrant file. So, using a Vagrant file, we describe everything needed to build that developer environment. So when I join the company or switch onto this team, I check out that repo, I run Vagrant up and boom I have a development environment that's ready to go and looks like production.
As we sort of sweep across this is where our Packer tools fit. So the goal of Packer is to consume all of these inputs, source code, config management, the different controls that we want to bake in, and then allow us to specify via a packer file what we want as our outputs.
So these outputs might be cloud images like AMIs, they might be container images like Docker. If we're on-premise we might be building VMDKs for VMware. The list goes on.
The goal here is that we're solving a consistent workflow problem, which is I have this raw input, source code, config management, and what I want at the other side of this is a packaged artifact suitable for these different environments. Whether that environment is AWS or Azure or Dockerized or on Prentice, it's the same workflow problem.
That's what packer lets us do, is capture this in a codified way and have a single pipeline for building these images. So what you'll start to see over and over again, is another one of our core philosophies. It's this notion of infrastructure as code.
And the goal is, how do we capture in a codified way, all of the processes to build a development environment? All of the processes to build one of these images? And this gives us two important benefits.
One, we can version it. So, we can check in these files, inter-version control, see how they've evolved over time and understand incrementally who's changed what.
The other thing it lets us do is to automate it. So instead of a developer joining and spending two weeks on a Wiki to set up an environment or manually pointing and clicking to build one of these golden images, we can automate that process and do it much more efficiently but also without introducing human error.
So as we come over here and talk about the provisioning challenge it's a similar approach. You'll see the same pattern applied again and again. And this time the tool is Terraform. So, Terraform is again focused on this provisioning challenge. Day one, when nothing is running and day two when we have existing infrastructure and we want to evolve it.
The form this takes is very similar. We capture on a set of Terraform configuration files what we want the infrastructure to look like. So, at the end of the day Terraform models this graphically. We think about it as a graph of infrastructure.
So what I mean is, maybe I have a core VPC which defines my networking, then on top of that, I'm defining a set of security groups and virtual machines and last thing I'm fronting this with a load balancer.
And so there's a natural set of dependencies here, which is we must bring up the network first so that we can define what the virtual machines are deploying into.
And so we capture all of this in a codified way that looks like text. So, this is something our human operators are writing and reading. It's meant to be very friendly and we just declare what we want the world to look like.
So, we just say we want these four resources to existing and on day one when nothing is running, Terraform will look at the world and say, "Great, there is nothing running. These are the four things you want." And so it will go out and provision these four things.
Day two, what might happen is like I said, infrastructure is a living, breathing thing. So you might come in and realize this load balancer should actually have a DNS record in front of it. And in front of that DNS record, we're going to deploy the content delivery network, maybe Akamai, maybe Fastly.
And so day two what Terraform will do is look at the delta. It will understand what's changed between our day one implementation when we launched the first four resources and day two when we've added these things. And it will tell us as an operator, "I plan to add a DNS record and a CDN to bring you into compliance with what you want the world to look like." And then when we apply it, this is what our universe will look like.
And so as an operator what it lets us focus on is what we want the world to look like and now focus on the details of how do we get from where we are today to where we want to be. And we do this again, following an infrastructure as code mentality.
So then as we sweep across to deploy, this is where our Nomad tool sits. So Nomad is our application scheduler.
And the challenge we frequently see here is there's typically a single application running on top of a single operating system within a VM. So this is a classic deployment architecture we see. And if what we have is a set of developers who care about the top of this problem, they care about their application lifecycle. They want to scale up, they want to scale down, they want to deploy new versions. But they really care about the application and not the underlying infrastructure.
And then we have a set of operators, who care about the opposite. They care about the operating system. They want to make sure it's patched, it's running the latest version, that if there are any security issues we can respond to it. They're not necessarily overly concerned with the application lifecycle.
The challenge is they're running on a single VM, which means we must coordinate between these two groups. The developers often times are filing tickets against the operators saying, "Deploy the new version. Scale up. Scale down. Change the application's life cycle in some way."
So our goal is how do we dis-intermediate this? Well this is where Nomad sits. So the goal of Nomad is to sit in between these two layers and dis-intermediate their concern. So as an operator I'm concerned with the base layer, the operating system and Nomad and my goal is to provide a fleet of capacity 100 machines, 500 machines to my developers, that they can then consume.
As a developer, I capture in a job file what I want to run. So, inside my job file I might say, "Here's my web server. I want to run version six and I want to run three instances of it."
And I provide this job file, which again follows an infrastructure as code practice. It's a file reversion control and check-in. And I provide this file to Nomad's API and then Nomad ensures at any given time three instances of this web server running.
Now at any time the developer may decide to scale up or scale down. They could change their job definition, say I want to have 10 instances now. And Nomad will look and say, "You already have three running, I'll do find somewhere to run seven additional ones." And we'll do this without involving an operator.
If I decide to deploy a new version, great. I can change my job definition, go from version six to version seven. And then Nomad a variety of roll-out strategies. So it might do a blue-green deployment, it could do a canary deployment. There are other sort of strategies we might use in terms of time staggering and all this will be managed through our job file.
Again, as a developer, you own this lifecycle yourself. Now as operators we're still free to deal with the things we care about. So if there's a new version of Red Hat we need to upgrade to, we can deploy the new fleet running the newest version and then tell Nomad "Drain all the work running on the existing fleet and move off of the old version of [inaudible 00:13:56]."
And we can do that because Nomad will ensure we're keeping this contract with our developers. So, if the developer asked for 10 instances always to be running, as we migrate work to the new fleet Nomad will keep those jobs running and move them one at a time to avoid disruption to the service.
In this way, the goal is, how do we decouple the workflow of the developer from the workflow of the operator? The secondary level benefit is, how do we improve our resource utilization? So in a traditional one app, one operating system per VM, we see on average less than one percent hardware utilization.
And this is because modern hardware, we might have eight cores and 16 gigs of RAM, but we're servicing 1,000 requests a day. And so this is effectively IOM modern hardware.
By virtue of letting Nomad coordinate what applications are running on the machine, Nomad is free to pack additional applications per machine. So you don't just run one app per operating system, Nomad might put five, ten, twenty applications as room allows on the same hardware.
So this allows us to go from a place where we're using less than one percent capacity to maybe 20% or 30%. Depending on the structure of our applications and the density, we might be able to get higher, but really even considering going from one percent to 10% allows us to reduce our fleet size by 90%. So there's a diminishing return as we increase the density, but starting at a very low point means there's huge return at even just getting to a single digit or low double-digit percentage of density.
Now as we sweep up to monitoring, this is where our Consul tool lives. And so Consul's a bit odd because it's not actually a monitoring tool. The reason we put Consul over here, is what it really is, is it's a tool for building service-oriented or micro-service applications.
So, as we think about starting with a Monolithic application that has different sub-systems to moving to a world where we're exploding these out into different services, we're moving from these things calling each other in memory. This is simply a function call, to now they need to talk to each other over the network. So the first level concern we have to solve is, how do they discover each other? How does service A know where to talk to service B over the network? This was easy in our Monolithic world because it was an in-memory function call. Now we're going over the network and we probably don't have a single instance B, we probably have many of them, both for scaling out and to ensure if one instance dies the whole service doesn't go down.
So, we have an issue of load balancing across these instances of B if one of them dies, we need to be resilient to failure and we're operating in a cloud environment were IPs are ephemeral. So we don't want to hardcode addresses.
So, one challenge Consul helps solve for us is doing this sort of discovery. So, Consul will act as the registry of what's running where and allow service A to discover service B, load balance across the instances and automatically routing around any failures that occur.
The other kind of challenge that occurs is configuration. So if we want to have a flag that puts service A into maintenance mode, where do we define this flag and when we change it from false to true, how do we efficiently tell all the instances of A, whether it's one, ten or a thousand instances, that they should go to maintenance mode?
So, Consul exposes this as a key-value store and allows us to efficiently push triggers and push updates to the applications.
The last one is, how do we building highly resilient services? So as we think about building these services, how do we do things like leader election? Automatic health checking? Failover? So that, we give developers a toolkit to build services that are going to be reliable when they're running in cloud environments.
And so all of these are sort of part of Consul's goal of really enabling the service-oriented architecture and doing this integrated health check and to enable all of this.
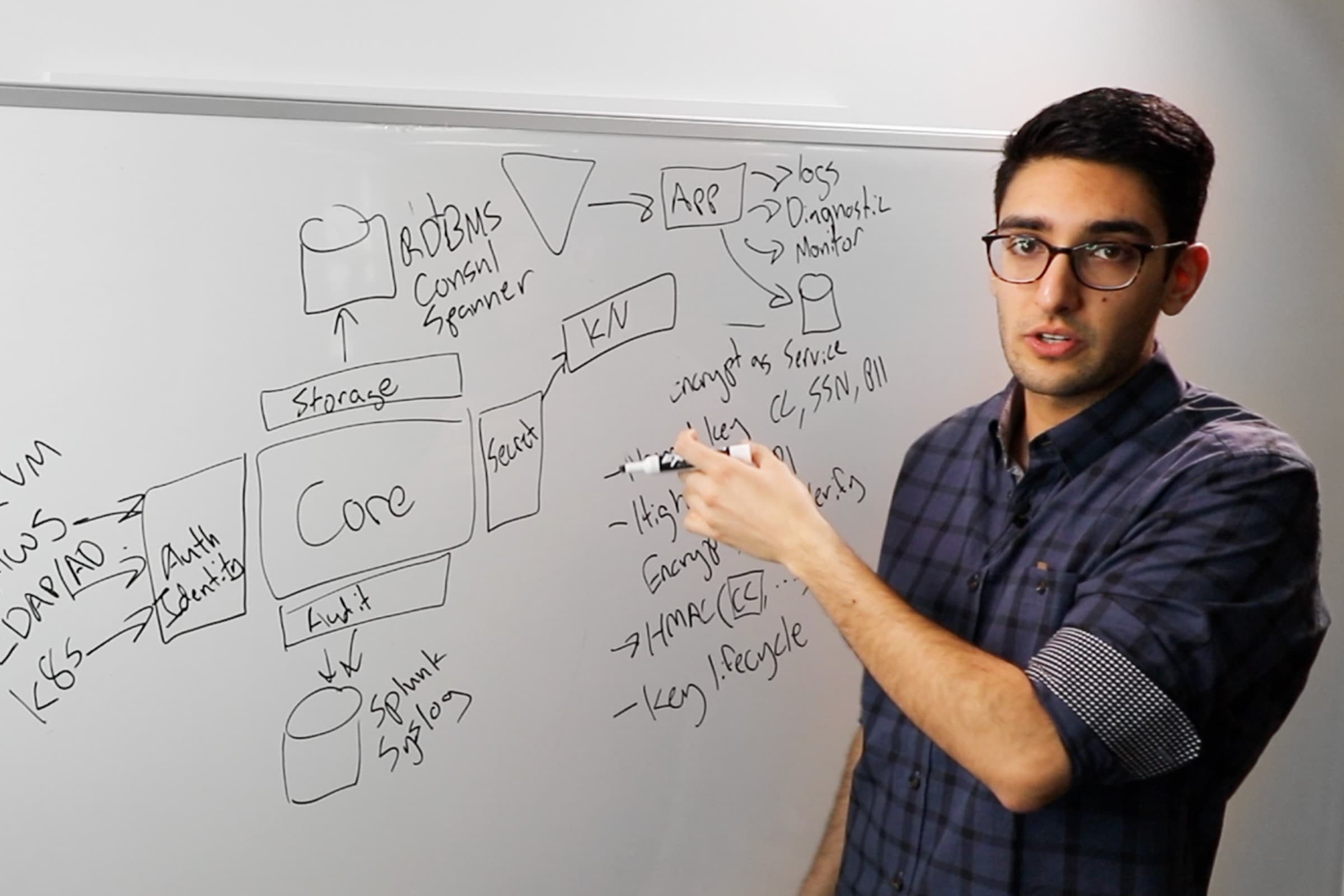
The last piece of this puzzle is Vault. What Vault focuses on is recognizing that every one of these different components needs access to secret material. Whether we need cloud credentials, or we need API keys, or our applications need database credentials and TLS certificates, we have this challenge of secrets existing everywhere. And so traditionally what we see, is a world of secrets sprawled. These secrets are in plain text and are configuration. They're in plain text and config management. They're in plain text and aversion control systems. And so we really have no good understanding of who has access to what. No real audit trail and all of these things are in plain text.
Vault tries to solve this problem by centralizing those secrets and encrypting them in transit and encrypting them at rest. And so this way we can have tight access control over who should have access to what and only distribute it to applications on as needed basis.
So this gives us strong auditing, it gives us strong access control and gives us a much better story around rotating and updating our credentials.
The second level challenge we find, is applications are often tasked with cryptography to protect their own data at rest. So instead of just letting Vault think about an encryption key as a 32-byte secret that we need to hold and then thread out to our application, instead Vault provides a first-class set of encryption as a service, primitives.
And so Vault with exposing high-level cryptographic APIs, the developers can consume without really having to know how the cryptography works or doing the key management in terms of key versioning, key rolling, key decommissioning. All of that becomes transparent and handled by Vault automatically.
The last level challenge Vault helps us with is something we call dynamic secrets. And the idea behind dynamic secrets is how do we treat credentials as a femoral and rotate them all the time? What we find is applications are actually not to be trusted with secrets. They will inevitably leak it to logs, they'll expose it to monitoring systems, they might expose it to a diagnostic page when there's an error.
And so what we really need to do is not trust the application to keep anything secret and instead provide them in a femoral credential that we're rotating automatically every day, every seven days, every 30 days and now create a moving target for attackers.
This mechanism is what Vault calls dynamic secrets, and allows us to create a just in time unique credential per client as they request it.
So zooming out, as we think about application delivery at HashiCorp. we see that there are these seven fundamental workflow problems. And there's really no way around them. We have to solve them. And fundamentally they don't change based on the technology. So, as we modernize and adopt new tools and new technologies we still have to solve these problems.
And so our goal is to really focus on how do we help solve the workflow problem of these things and then build tools that are pluggable so as you go from Java to C Sharp, C Sharp to Go, VMs to containers, that the toolchain doesn't change. Your process of delivery doesn't change, you just tweak the configuration that you're using but keep with a standardized, uniform toolchain across technologies, across different cloud environments.
This is our view of application delivery. If you're interested in learning more about any of these tools, I encourage you to check out our resources online. Thank you.