

We are pleased to announce the release of HashiCorp Nomad 0.8.
Nomad is an easy-to-use and flexible cluster scheduler that can run a diverse workload of micro-service, batch, containerized and non-containerized applications. Nomad is easy to operate and scale, and integrates seamlessly with HashiCorp Consul for service discovery and HashiCorp Vault for secrets management.
Version 0.8 enhances Nomad's cluster management features and reliability, helping to ensure a seamless operational experience as a growing number of enterprises adopt Nomad, move into production, and scale out. The major new features in Nomad 0.8 include:- Rescheduling: Nomad will automatically reschedule failed allocations according to a new reschedule stanza.
- Advanced Node Draining: Enhanced controls are now available to operators when transitioning workloads to a new set of nodes.
- Driver Health Checking: Nomad can now detect the health of a driver and restrict task placement accordingly (starting initially with Docker).
- Server-side Access to Client APIs: Nomad servers can now service client HTTP endpoints. This enables a fully functional CLI and Web UI when Nomad clients are not directly accessible over the network.
- Autopilot: Autopilot capabilities that allow automatic, operator-friendly management of the Nomad servers are now available in the open source and enterprise versions of Nomad. This mirrors the Autopilot feature that is currently available in Consul.
This release also includes a number of improvements to the Web UI, the CLI, the Docker driver, and other Nomad components. The CHANGELOG provides a full list of Nomad 0.8 features, enhancements, and bug fixes.
»Rescheduling
Ensuring the health and availability of running services is critical for any cluster management system. Prior to the 0.8 release, Nomad's self-healing capabilities included:
- Automatically rescheduling all allocations when a node fails.
- Automatically restarting a task in-place if it fails.
- Automatically restarting a task in-place if one of its health checks fails.
Nomad 0.8 adds coverage for an important edge case:
- Automatically rescheduling an allocation that has exceeded its in-place restarts to another node.
This condition can surface due to host specific issues, such as failing hardware, network partitioning, or driver failures (see Driver Health Checking: below). As of Nomad 0.8, an application owner can customize the rescheduling strategy for a job using the new reschedule stanza:
reschedule {
delay = "30s"
delay_function = "exponential"
max_delay = "5m"
unlimited = true
}
The parameters available allow the application owner to express how frequently reschedule attempts should occur. See the reschedule stanza documentation for more examples and a detailed description of all parameters and default values.
»Advanced Node Draining
Note: Our Advanced Node Draining blog post has a thorough overview and recorded demonstration of this feature.
Migrating tasks from an existing set of nodes to a new set of nodes is commonly used for node maintenance or to upgrade the base infrastructure. However, migrations need to be carefully orchestrated to prevent service outages. Prior to 0.8, Nomad's node-drain CLI command could be used to migrate workloads off of a given node, but the controls that were available to operators were limited. Nomad 0.8 introduces advanced node draining capabilities that enable an operator to perform migrations with the following benefits:
- Cascading migrations can be avoided (migrating allocations to nodes that also need to be drained).
- Service disruptions that can result from stopping every instance of a service before replacements are running elsewhere can be avoided.
- Batch processing tasks can be allowed to complete.
- System jobs responsible for logging or monitoring can be drained last.
- Draining is no longer asynchronous, eliminating the need for manual intervention or scripting to determine completion.
Nomad 0.8 enables both the application owner and the cluster operator to control how migrations occur, since the cluster operators alone may not be aware of the availability requirements for a given service. Application owners can use the new migrate stanza to define draining behavior for their jobs. The migrate stanza in the example below instructs Nomad to limit parallel migrations to a single allocation and requires an allocation to have been healthy for ten seconds to proceed with the next migration:
migrate {
max_parallel = 1
health_check = "checks"
min_healthy_time = "10s"
healthy_deadline = "5m"
}
The parameters available allow the application owner to dictate the rate at which allocations are migrated and how task health is established. Migrate stanza parameters mirror the parameters available in the update stanza. See the migrate stanza documentation for a complete overview.
The node drain CLI command adds several new flags for operators:
-
deadline: This allows operators to set a deadline when draining a node. Batch jobs will continue to run on a draining node until the deadline. When the deadline is reached, all remaining allocations will be force removed from the node.
-
force: Draining a node no longer stops all allocations immediately (see the migrate stanza section above). The
-forceflag can be used to emulate the old drain behavior. -
detach: The enhanced
node draincommand will now monitor the status of the drain operation, blocking until the drain completes and all allocations on the draining node have stopped. The-detachflag can be used to trigger a drain but not monitor it.
The node drain command output below illustrates the controlled draining of allocations that is now possible with the node draining improvements that have been introduced in Nomad 0.8:
$ nomad node drain -enable -yes bd74
2018-04-11T00:00:42Z: Ctrl-C to stop monitoring: will not cancel the node drain
2018-04-11T00:00:42Z: Node "bd7422ca-2dc3-46c3-7c40-ee3c0fde00cc" drain strategy set
2018-04-11T00:00:43Z: Alloc "1037f2cf-40e3-477d-edc5-388ec19a3b8f" marked for migration
2018-04-11T00:00:43Z: Alloc "1037f2cf-40e3-477d-edc5-388ec19a3b8f" draining
2018-04-11T00:00:43Z: Alloc "1037f2cf-40e3-477d-edc5-388ec19a3b8f" status running -> complete
2018-04-11T00:01:41Z: Alloc "28171457-fbc8-bc86-6548-1b2843237544" marked for migration
2018-04-11T00:01:41Z: Alloc "28171457-fbc8-bc86-6548-1b2843237544" draining
2018-04-11T00:01:41Z: Alloc "28171457-fbc8-bc86-6548-1b2843237544" status running -> complete
2018-04-11T00:03:14Z: Alloc "41e7e81d-893b-4f89-9506-e0c5b4632e64" marked for migration
2018-04-11T00:03:14Z: Alloc "41e7e81d-893b-4f89-9506-e0c5b4632e64" draining
2018-04-11T00:03:15Z: Alloc "41e7e81d-893b-4f89-9506-e0c5b4632e64" status running -> complete
2018-04-11T00:03:50Z: Alloc "98955a58-024e-1796-0d18-bec519f5de44" marked for migration
2018-04-11T00:03:50Z: Alloc "98955a58-024e-1796-0d18-bec519f5de44" draining
2018-04-11T00:03:50Z: Node "bd7422ca-2dc3-46c3-7c40-ee3c0fde00cc" drain complete
2018-04-11T00:03:50Z: Alloc "98955a58-024e-1796-0d18-bec519f5de44" status running -> complete
2018-04-11T00:03:50Z: All allocations on node "bd7422ca-2dc3-46c3-7c40-ee3c0fde00cc" have stopped.
See the node drain command documentation for more information.
Advanced node draining in Nomad 0.8 also introduces the concept of node eligibility. When draining a node, Nomad will automatically mark the node as ineligible for new placements. The node eligibility CLI command can be used to disable scheduling for any node independent of the node draining process.
See the node eligibility command documentation for the more details.
»Driver Health Checking
Nomad’s task drivers are responsible for running the tasks in an allocation. When a driver becomes unhealthy on a node, it can be problematic for operators if Nomad continues to place new allocations on the node that depend on the driver. Driver health checking capabilities in Nomad 0.8 reduce this burden by enabling the scheduler to limit placement of allocations based on driver health status and by surfacing driver health status to operators.
In the node-status command output below, the Driver Status field and the Node Events block reflect the change in status for the Docker driver after stopping the service:
$ sudo systemctl stop docker.service
$ nomad node-status 393d4ac8
ID = 393d4ac8
Name = ip-172-31-16-110
Class = <none>
DC = dc1
Drain = false
Eligibility = eligible
Status = ready
Uptime = 13m3s
Driver Status = rkt, docker (unhealthy), exec, raw_exec, java, qemu
Node Events
Time Subsystem Message
2018-04-11T17:50:29Z Driver: docker Driver docker is detected: false
2018-04-11T17:39:52Z Cluster Node Registered
...
»Server-side Access to Client APIs
Nomad clients directly host the HTTP endpoints that are used to service requests for allocation statistics, log streaming and file exploration. In prior versions of Nomad, this required network "line-of-sight" to the clients in order to use the relevant CLI and Web UI features. Nomad 0.8 enables the servers to handle client HTTP endpoint requests, forwarding to the relevant clients under the hood via newly added server-to-client RPC capabilities (RPC was previously limited to client-to-server). This in turn enables fully functional interfaces without compromising on client-side network security.
»Autopilot (Enterprise)
Nomad 0.8 introduces Autopilot capabilities which leverage version 3 of the Raft protocol to enable automatic operator-friendly management of the servers.
Autopilot features in the open source version of Nomad include:
- Automatic dead server cleanup: Dead servers will be automatically removed from the Raft peer set upon introduction of a new server.
- Built-in server health checking: An internal health check runs on the leader to track the stability of servers.
- Stable server introduction: Newly added servers must be healthy and stable for a waiting period before being promoted to a full, voting member.
Nomad Enterprise Autopilot features include:
- Server read scaling: Additional non-voting servers can be added to scale read and scheduling throughput. Non-voters receive the replication stream but do not impact quorum.
- Redundancy zones: Redundancy zones enable hot server failover on a per availability zone basis.
- Upgrade migrations: Autopilot enables fully automated server upgrades for Nomad Enterprise operators.
See the Nomad Autopilot Guide for a comprehensive overview.
»Web UI Improvements
Nomad 0.8 adds several new features and improvements to the Web UI:
-
Allocation stats and log requests are now routed through the servers (as needed) to enable a fully functional Web UI even when the browser cannot directly access the client.
-
All views now use long-polling via blocking queries and will automatically update in real time as data on the page changes.
-
Specialized job detail pages now exist for every job type (system, service, batch, periodic, parameterized).
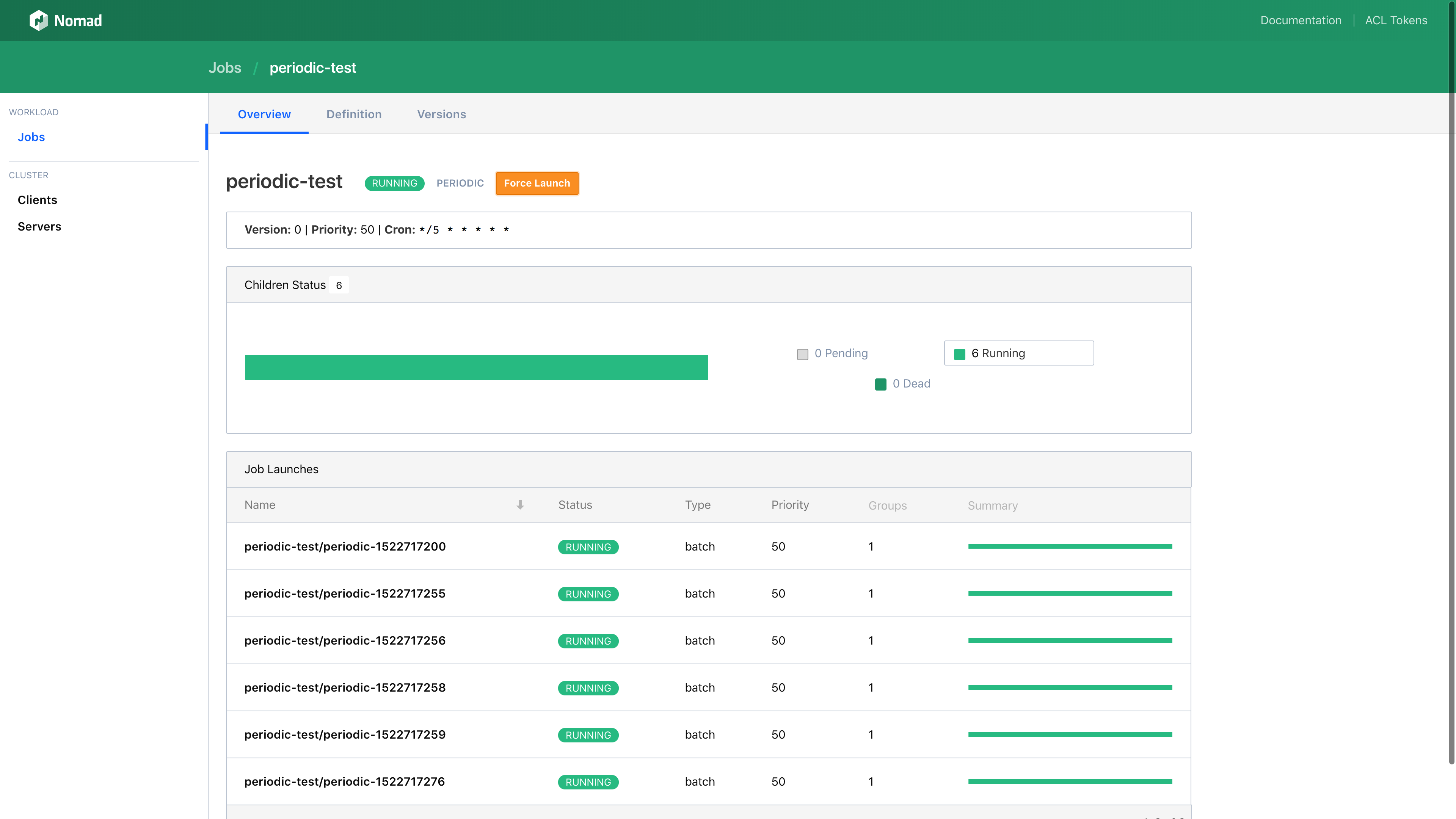
»Additional Features in Nomad 0.8
- Docker Improvements
- Hard CPU limits are now supported.
- Advertising IPv6 addresses is now supported.
- Overriding the image ENTRYPOINT is now supported.
- Adding or dropping capabilities is now supported.
- Mounting the root filesystem as read-only is now supported.
- CLI Improvements
- Common commands are now highlighted.
- All commands are now grouped by subsystem.
- DataDog tags are now supported for metrics.
- Upgrading/downgrading a running cluster to or from TLS is now possible via SIGHUP for both servers and clients.
- Node events are now emitted for events such as node registration and heartbeating.
»Recent Nomad Blog Posts
- Advanced Node Draining in HashiCorp Nomad
- HashiCorp Nomad and Legacy Applications
- Introducing Heron on Nomad
- Leveling Up the Terraform Provider for Nomad
- Vault Secrets Backend for Nomad
- On-demand Container Storage with HashiCorp Nomad
- Cluster Scheduling Systems for Large Scale Security Operations
»Nomad is Trusted By

To learn more about Nomad visit https://www.hashicorp.com/products/nomad.







