Vault Advisor: Preventing Security Incidents By Automating Policy Optimization
HashiCorp Research gives its first look at Vault Advisor, an upcoming utility that gives operators intelligent, automated suggestions for safer access policies.
The NIST Cybersecurity Framework says security teams should try to protect before they detect. This means reducing your attack surface by looking at your access control lists (ACLs) and ensuring that they're not too permissive. Optimizing your ACLs and policies can be a lot of work though, and you certainly don't want to revoke privileges that are necessary.
Jon Currey and Robbie McKinstry of the HashiCorp research team will unveil some work they've been doing on a new utility for Vault called "Vault Advisor." This 'clippy for Vault' is intended to help operators optimize access policies and configurations by giving them intelligent, automated suggestions.
Speakers
 Jon CurreyDirector of Research, HashiCorp
Jon CurreyDirector of Research, HashiCorp Robbie MckinstryResearch Engineer, HashiCorp
Robbie MckinstryResearch Engineer, HashiCorp


Transcript
Jon Currey: Thanks for coming and sticking through to the latter half of the session. Very excited to talk to you today about Vault Advisor, this is something that we've been working on in HashiCorp research for over a year and it's great to finally be able to share it with the world.
I'm Jon Currey, the director of research at HashiCorp. I joined a little bit over 2 years ago. You might have seen some of the other work we've been doing on Lifeguard, fixing up problems with the SWIM protocol that underlies Consul. But this is the first completely from-scratch piece of research that we're sharing with the world.
Robbie McKinstry will be coming out for the 2nd half of the talk. I'm going to set up why we wanted to solve this problem and frame it in terms of the terminology and everything, and then Robbie's going to be the one to take you through the challenges that we had to solve, and give you a brief demo because it's still just a prototype. Robbie will have tweeted the links when we show a paper. Don't rush to scroll down through the information about the paper. You can get that from Robbie's Twitter feed.
Any security tool is only as good as its configuration
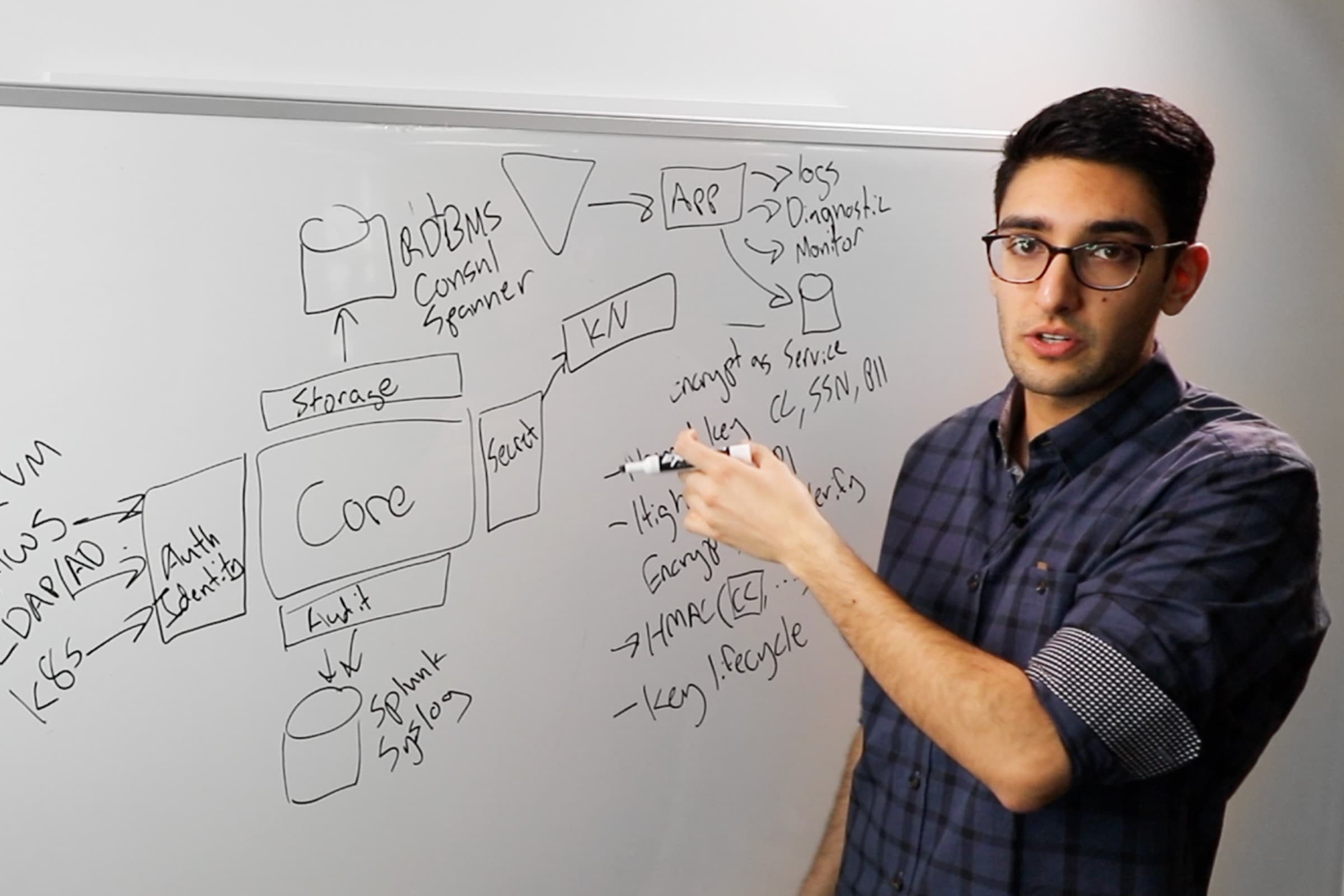
As Armon pointed out in the keynote yesterday, we have great security tools these days, but any security tool is only as good as its configuration. You can have a completely bug-free firewall and that's awesome, but if it's misconfigured, the traffic is going to breeze right through when you don't want it to. Of course, Vault is no exception. We've concentrated a lot of security power into Vault and it's super critical that you configure Vault the right way.
Extra complication for Vault is, you might be the admin or the SecOps team, but you probably have some amount of self-service or delegation. You have different classes of users who are also getting in there and modifying the configuration or the things that are being configured, or both, so it's very much a relevant issue for Vault.
Addressing the problem of unnecessary authorization
The way that this manifests, the big problem we're trying to address here is unnecessary authorization. We're going to look at a lot of these matrix or table forms today and what we've got going on here is, each row corresponds to some entity in Vault terms, a service or something that is using Vault. Each column here is a credential which would be represented by a secret, so now we have this authorization matrix, and in this case, all 9 of the boxes are checked. That means all 3 services on the 3 rows are authorized for all 3 of the credentials in the 3 columns. But the white check mark here is denoting that not only are they authorized, they're using that particular credential, so this is a necessary and appropriate authorization.
Unnecessary authorization leads to unnecessary risk
But in this particular scenario, for some reason, some of these services are being authorized for credentials that they are not using. That unnecessary authorization translates directly into unnecessary risk. If one of these accounts got compromised, this is an increase in the attack surface of your organization. You have got credentials here that could potentially be used, chained together to traverse the organization in an exploit, so you absolutely would be safer if you did not have these authorizations that are not being used.
The principle of least privilege
This maps back onto the principle of least privilege, which I'm sure you're all familiar with. We wanted to make sure we didn't miss anything important here, so in 1974 Jerome Saltzer at MIT, he was one of the architects of Multics which inspired Unix somewhat. Unix was a little bit of a reaction against some of the Multics stuff, but they borrowed a huge amount of stuff from Multics. This is the paper where the principle of least privilege is first called out, and it's a straightforward thing. It corresponds to what you would read on Wikipedia: Programs and privileged users of the system should ideally only operate using the least amount of privilege that they need to complete their job, the thing that you want them to do.
That's very straightforward. Really nice paper. If you were going to read just one paper from this era though, I would encourage you to read the paper that Saltzer and his student, Mike Schroeder, wrote the following year. This is right before Mike Schroeder co-invented the Needham-Schroeder protocol, which underlies Kerberos. Mike has gone on to be a big name in systems and security.
In this follow-up paper, they've identified 10 different security/design principles. This is 1975, each of these is as relevant today as it was in 1975. I encourage you to read this paper. Having got time to dive in here, of course, the principle of least privilege is there, but I'm also going to draw your attention to psychological acceptability. This is saying, if the way you have to interact with the security system is too burdensome, people are going to be disinclined to use it and it's going to be a much harder ride. People have to be able to understand and grok what's going on security-wise.
Configuration risk vs. complexity
Applying that to Vault, it turns out that psychological acceptability is also a factor in the management of your Vault configuration. You may be over here on the left-hand side. You might have a simpler configuration to make it psychologically acceptable. Makes it easier to manage. But there's higher risk there. What we'd like to do is move to the right of this diagram. We could go all in, we could go to the other end and lower that risk by eliminating all of the unnecessary privileges, but that is typically going to make the configuration more complex. Because typically if you want to have more fine-grain access control, you're going to need more policies and/or more path rules within those policies.
We want to try and find a balance here. What we want is some sweet spot, Armon talked about a Goldilocks configuration that's just right. That's going to depend on the constraints of your organization and might even be different on a case-by-case basis. The different things within your organization. Something's more sensitive, you may accept more complexity, to lower the risk. Other things that are not so sensitive, maybe you need people to be able to move fast and so there are nuances to this, but this is the general framework that we're working in here. And we're trying to help admins and operators in general.
Service refactor without policy refactor
We go back to that basic scenario and we said, "Okay, everybody's authorized for everything. Some of these unnecessary authorizations, why is this going on? This is crummy. Who would let this happen?" What if there was 1 service and it needed these 3 credentials and then at some point, very good practice, team is growing, responsibilities are growing, that thing got decomposed. You went and did a nice microservice refactor. You split that service out into 3 services.
By the way, we're going to be using the color. It will get more interesting when they're multiple policies, but the bottom here, this is the policy for this App One that got refactored. The simplest thing you could do is secret/* or, "Hey, let's narrow it to secret/creds/*." This is the wide-open let's-not-make-people's-jobs-too-difficult way of default configuration. Early, immature, organizational way of using Vault.
Why didn't they refactor this? It turns out they probably made, in one sense, an optimal decision. If they had gone and refactored this thing not knowing whether the other microservice was already online and who's doing this and that, there's a coordination issue. Why would you go and refactor this? There's a risk to the operational stability of the organization.
"Move fast and don't break things"
If people are just trying to keep moving faster, want to keep up the velocity and not break things (turns out not everybody in the world subscribes to "Move faster and break things") then you would think, this is a reasonable decision down on the ground. Unfortunately, it's a locally optimal solution and long-term, there's a security debt that's being incurred here by not doing this. But you can't fault the developers on the day for doing this. They did something that was not a bad approach.
Refactor: policy per service
At some point we want to come along and we want to refactor this, so here's a possible refactoring. Using the colors here, this is 1 new policy. We're replacing that 1 secret/cred/star policy with 3 different policies. In this approach, there's a different policy per service. That's horizontal, 1 per row. This is nice. We've locked it down. There's no more exclamation points here. There's no unnecessary risk. Each of the services has got exactly the privileges that it needs.
Policy per credential
There are other ways that you could do this. You could also do a column-based approach here. You could say, "Well, I'm going to manage each of these credentials." A given service would be assigned whichever policies, and multiple policies, that it needs. But this is a matrix mix-in approach to managing access to the credentials. There are multiple ways to do things.
Goldilocks configuration?
This Goldilocks configuration. The previous two were optimal from a risk perspective. There were no unnecessary, unused privileges authorized. The exclamation mark in the middle, we've relaxed this a little bit. We've introduced one little bit of unnecessary risk. In return, we've gone from 3 policies down to 2 policies. We're trading the risk and the complexity a little bit.
Configuration comparison
I've shown you 4 configurations. There's the current, initial configuration, I showed how we could do that service or row-based refactor. The column or capability-based refactor, and then we could explore other things where we try to find something in between, a Goldilocks configuration. How are we going to compare these things? How are we going to measure them?
Configuration metrics
We should try to change this from a qualitative thing ("That's a great policy. I love that policy."). No, let's put some numbers on this. For ourselves, if you're going to do a considered analytical way of looking at the problem, but also because we're going to try and automate this and build some algorithms that are going to reason about the soundness and the relative benefit of different configurations, so we need numbers. We can do things like assigning a score to a possible proposal or a proposed configuration change. We can even measure the distance between proposals potentially in this multidimensional space of different metrics.
Two key metrics that we've alighted on, not surprisingly, we've been talking about the unnecessary risk, how should we quantify an unnecessary risk? One way is to just sum up those exclamation marks in that grid. In the previous example, the unnecessary risk count was 1, because it had 1 authorization that was not necessary.
Complexity is a little bit more complex it turns out when you look at a bunch of policies. You can count how many policies there are. But also, how complex is each proposal, how many different path rules does it have, for example. These are, by no means, the be-all and end-all. This is an active area of research. We're even thinking about how you could learn the complexity measure and the risk measure.
There's prior work to do that kind of adaptation. As a starting point, for the prototype right now, we say, split the difference. Both the number of policies and the number of path rules that contribute to the complexity of the configuration, let's just sum them up. It's a stake in the ground. Not saying that this is the be-all and end-all, but let's see what we can do with this approach.
Unnecessary risk is 1 in this configuration, in that Goldilocks configuration I showed you before because there was 1 authorized but unused capability. By this measure of the complexity, there are 2 policies, but there are a total of 3 path rules. Sum those up, we end up with the complexity of 5, so now we've gotten all analytical here and we can compare the relative merits of these different proposals.
We've got 2 that drove down, eliminated the unnecessary risks. By the way, there's still risk. Anyone who has a credential could be compromised. Obviously, you can't take it away because they need that credential, so we can't get rid of the necessary risks. We can only get rid of the unnecessary risk. We want to drive that to 0. The Goldilocks configuration, it's introduced a little bit of risk. It's reduced the complexity a little bit. Was it enough in this particular case? That's an organizational decision possibly based on the sensitivity of the particular credentials, secrets under management, but we're getting into analytical method here.
Real-world complexity
Of course, that was a simple, contrived example just to motivate the components of the problem. In the real world, there are different capabilities on each secret. There are humans and apps in the mix operating on the same credentials. Humans have a whole bunch of interesting factors that apps tend not to have, like working in teams. You could group your apps together as well, but there are admins and users. You can have delegation, change your role. Some people even go on vacation, so all sorts of human craziness.
For this configuration, how many different ways are there that we could refactor this? Both in the pure method with the unnecessary risk and the relaxations. It turns out there are a bunch and it turns out that when you get past 2 or 3, the cognitive load, the psychological acceptability, we need to have a way to reason about the tradeoff between the risk here on the y-axis and the complexity on the x-axis.
These are the metrics that I set up, and what's cool is, you see this curve, and if you're coming in with a typical configuration, you are low on complexity because you made it manageable so that people could feel confident that they weren't breaking the organization. But as a result, you are suffering a lot of unnecessary risk.
We can zip all the way to the bottom right and eliminate all of that unnecessary risk, but you might not like what you get in terms of complexity. You may end up with 50 policies instead of 1 policy. That's not a lot of fun. The Goldilocks region is all these policies in between and we would like to give you a way to reason about this. So we arrive at the requirements that we got into for building Advisor.
Solution requirements for building Advisor
We want to automatically discover this range on the points on that curve. We want to find a range of good configuration choices. There's more metrics by the way, those are the two key metrics, but we have other metrics of goodness for a proposal, for a configuration. We want to see 0 unnecessary risks, the bottom right of the curve, but we want to see that tradeoff and backing off from that, so that you can choose as an organization or an individual the sweet spot for you. Crucially, we're choosing to keep this as a human-decision-support function. AI is not there yet. Read: machine learning. This is complex and mission-critical stuff and no one should be under any illusion that you're going to hand off responsibility of this to an algorithm anytime soon.
You need to be the decision maker, but this is intelligence augmentation. This is empowering you to have more confidence that these proposals, none of these will break based on the recent usage and the audit logs, none of this will break my organization and I can now quantitatively examine these. You compare these different alternatives, so because it's talking to the human, we need a manageable number of proposals to compare and we need each of those proposals to be explainable. This is the background, this is the reasoning and that's how we got to Vault Advisor. Now please welcome Robbie McKinstry who is going to walk you through how we are tackling this challenge.
Robbie McKinstry: Wow. I get music. Look at that. All right, I'm Robbie McKinstry. As Jon pointed out, I'm going to be talking about Vault Advisor, which is our solution to the problems that Jon introduced with refactoring policies. Jon didn't introduce the problems, I should. These are problems that operators tend to face.
The Advisor approach
Okay, s mentioned in Armon's keynote, he described the Vault Advisor workflow. You start with a Vault cluster and Advisor will ingest your audit logs, which is what we use to determine how much unnecessary risk you have.
After that, we will generate out a series of proposals or new configurations, and then we'll show those new configurations to an operator who will then, as Jon noted -- the operator is in the loop) -- look at the new configurations, identify the tradeoffs, which proposals they might want to accept and then apply that new configuration to Vault, at which point we can trail the audit logs again, generate some new proposals and rinse and repeat. Ultimately we try and get your system into a state in which you have produced sane Vault policies while at the same time reduced your risk.
In reality, though, when the rubber hits the road, we do have a 3rd phase in our workflow for the internals of Advisor in which we filter out from a large number of generated possible configurations to a smaller number of proposals, which are new configurations which we then show to the operator. In designing Vault Advisor, we faced some challenges of scale. Primarily, a huge number of event logs come in through a Vault cluster in a given day. If you have just 12 requests a second, you'll end up with over a million logs per day.
Realistically, as most of the operators in the room know, your Vault servers handle way more than 12 requests a second, so we're looking in some order of tens of millions of events coming into Advisor per day and we can't store all of that information. We need a way to ingest these logs, but then compressing the information into just exactly what we need in order to be able to reduce your unnecessary risk while keeping your policies not too complex.
That's the problem that we're going to face first. Next, we're going to talk about how we can generate out some number of proposals maybe in the order of hundreds or thousands, which all tend to be pretty sane. It's not like a monkey sitting at a keyboard generating out your new configurations. We want to produce somewhere around a couple of hundred proposals before we begin to filter them down in the final stage where we show the operator maybe 10 proposals that they can sort through and maybe even less than 10, like a handful or a couple of proposals of these to sort through and then pick from there which ones that they want to apply to their system, if any at all. First we're going to talk about ingestion and then we'll work our way to the next two problems.
The first problem: Ingestion
For ingestion, we looked at the shape of Vault configurations in the wild and we determined that for policies -- not necessarily at the policy level, but at the system level – the use matrices tend to be sparse. The reason for this is that a single entity in the system is never going to use all of the capabilities granted in a system. You're not gonna have access to every secret. You can have access to a subset of the secrets. The converse of that is that a single capability in the system, a single secret is not going to be accessed by all of the entities in the system, but instead the subset. What we concluded was that we can represent the use of the system sparsely. We can have a sparse representation in which we only store the things that we need to perform this computation. We don't have to have the full representation of the entire system.
The final observation with this is that we also have secret paths, or secrets in our Vault system tend to have a long shared prefix, tend to be a secret or /secret/db/whatever. That tends to be what it looks like in the wild. We can use a radix tree to compress that information represented like a trie data structure and that way we don't have to store the entire string over and over again. That is how we solve the ingestion problem. We use a sparse representation of our input. We only really care about 3 things. We only really care about storing who read what secret using what policy. We only need to store those 3 things, and that's how we arrived at the sparse representation.
The next thing we're going to talk about is how we end up looking at the search space of all possible configurations that could be produced, and then narrowing in on the ones that are interesting to us. By interesting to us, we mean that they minimize complexity and minimize unnecessary risk. There's a massive search space of all the different ways you could configure your Vault instance, but very few of those are interesting, actually useful to you. We had to come up with a way to solve that problem and generate somewhere in the order of a couple hundred or maybe even a thousand different configurations which we then filter. It turns out that this configuration generation is hard and I don't mean to say that it's difficult.
Configuration generation is hard
It is difficult, but it is also hard. By hard I mean, NP-hard. If you look at what we're doing here, we have a set of elements, the check marks. We want to cover those elements. We want to use some set of policies to cover all of those elements in the set. What I'm describing here is a set cover. Set cover is, if you may remember from college, this typical problem in algorithmic design. It's a canonical NP-hard problem. The problem of set cover is that given a list, a universe of elements, and some sets which cover those elements, find the collection of sets which will cover all of the elements.
Each of the black dots represents a check mark. We need to find some collection of policies which will give everyone the authorization they need while at the same time minimizing the number of policies that you generate, that you apply in your system. Richard Karp, in 1972 at a symposium, released the famous paper in which he reduces 21 different NP-complete problems kind of in a quine back along themselves. You reduce 1st one to the 2nd, 2nd to the 3rd, all the way back to the 1st.
This is how he showed that all of these problems, if they're NP-complete, they also are NP-hard. He won the Turing Award for this. This is a seminal work in which he demonstrated that all of these NP-complete problems are also NP-hard and that they all reduce to each other. In describing NP-hardness, he says that an algorithm is NP-hard if it can be solved by a non-deterministic Turing machine in polynomial time. A non-deterministic Turing machine is like a Turing machine, which is a tape with a pointer processing the inputs. But it has the property that when it comes to a branch in the code, it clones itself and can explore both simultaneously.
A non-deterministic algorithm is defined such that, when you have two alternatives, it creates 2 copies of itself and pursues them both equally. The key thing about this is that repeated splitting may lead to an exponentially growing number of copies. This is how we get our exponential time, this is how we get no guarantee on whether or not Vault Advisor will finish. That's terrible, right? Can't have that, right? It's like Vault Advisor could execute, and not finished before the heat death of the universe if we were to use said cover as Karp lays out. Unacceptable. I don't think your bosses are gonna let you wait around that long.
Set cover gives you a point along the x-axis. It will give you the far bottom right. It will tell you, I found something that has 0 unnecessary risk, we have covered the set. We've viewed sets to cover all the vertices, all of the elements. That gives us something with 0 unnecessary rest. The problem with this is that it's going to be very complex. Set cover doesn't give you all that much, and you have no guarantee that it will finish before the heat death of the universe.
However, our observation was that we already know a way to generate a configuration that lies along this axis. We can come up with a constant-time solution that will give us something with 0 unnecessary risk. We do that by creating a single policy for each capability in your system. If you've got 50 secrets, and you're reading, writing all of them, you end up with 200 different policies. Also not amazing. Now we've ballooned our complexity in the same way that we ballooned it with set cover, arriving all the way at the bottom right over here.
But it does give us a starting point, and it lets us get there in constant time. What we do is, once we've split it up into these end policies, we can perfectly assign each of these policies to the entity that uses the capabilities. In this example, Alice uses exactly 1 capability. She uses read on secret 1, we can assign her that 1 policy. Versus the web server, uses 3 different capabilities. We can assign it exactly those 3 policies.
This gets us to 0 unnecessary risk, and it gets us there quickly. Problem with this is that it ends up ballooning complexity again. What we then did, as our solution to this, we noticed that we can begin to merge back these policies together, and end up agglomerating them. Pursuing a path, an algorithm that will give us multiple policies merging together, without introducing unnecessary risk.
For this example, Eve has access to policy 7, policy 9, and policy 10. She needs those capabilities, and we start off with 3 different policies. However, if we stick those 3 different policies together in 1, if we merge them together, transforming input so we end up agglomerating them into 1 policy instead of 3, we've still not introduced any unnecessary risk. Because Eve can be assigned 7, 9, and 10, merge them together, and still have no unnecessary risk.
This is how we do it. We roll up starting with 1 policy per credential, we start merging them back together, and then ultimately we will arrive back with 1 policy again. Which is where we started. So we'll move all the way from the far right of the curve, back towards the left. And that's how you get this sweeping arch in our graph. These points are the output of this algorithm.
Hierarchical agglomerative clustering
The algorithm that we use is called hierarchical agglomerative clustering. A little bit of a mouthful. The idea is that at each step of this tree diagram, we merge two policies together. We take the 2 policies that introduce the least amount of risk, and then merge them together to produce 1 policy. We start off, if you look at the chart, if you start at the bottom of the chart. We start off with 11 policies and then as we move up to 10, we merge, lets say, 7 and 9, or 8 and 9, and we don't end up getting any unnecessary risk because Alice was using both of those credentials. We perform it again, we merge, whatever it is, the combination of 8 and 9, with 10. Because Alice was using those credentials as well, we still don't have any unnecessary risk.
When we start merging on with other policies which Alice doesn't necessarily have access to, or the other entities don't necessarily need, we start introducing more risk. You can see we end up with this trade-off between risk and complexity. That's really what we're looking for. We're not looking to generate out configuration that does not give you any benefit.
The third stage: Filtering
That's how we solve the generation problems with hierarchical agglomerative clustering, and then finally we move onto the filter stage. How do we go from n policies, some number of policies, based on how many secrets there are in your system, up to something like 10. Such that an operator can survey this and decide exactly which ones they want to apply. This is the filtering step. The observation that we made here is that there are some of these configurations which don't buy us anything. They don't make a lot of sense.
You can see that some of these considerations are more complex and more risky than other configurations. We can see that some of the dots are further to the right, and further up, than other ones. Those are configurations that you'd never want. You'd never want to make your system simultaneously more complex and less secure. These configurations are ones we can eliminate.
Similarly, if 2 things are equal, if they are equally risky, but 1 is more complex than the other, we can eliminate that one as well. If you're not getting anything in the trade-off, you can eliminate the point, the configuration. Once we do that, we end up with something a little bit more sane. Here we've labeled the orange dots, the sub-optimal ones, while the blue dots are the ones that we're gonna show to the operator. We're never gonna show an operator one that would not make any sense. This is what we arrive at.
This is borrowed from game theory, it's an algorithm or a technique, known as the elimination of strictly dominating strategies. Which is to say that, we will never make a move that would not make sense. Configuration which is no better than any other configuration, in any measure, is unnecessary. we can mark it as redundant and move along.
That gives us all 3. That is the core of the engine of Advisor. We have a couple of other filters we can talk about later. A different date. Now I'm gonna show you the web UI and the CLI for Advisor. We have a CLI output, this is spinning up a Vault cluster with 3 instances, a 3-note cluster. Then it runs the hierarchical agglomerative clustering algorithm.
Some of the output from hierarchical agglomerative clustering. You can see here that we've got the risk score, the complexity score, the number of policies, and the number of stanzas in the HCL in each of those policies, added up. Along with some other scores here that might be future work. Finally you can also see how this new configuration, and assigned each of the entities in our system, our API server, Charlie might be an ops engineer, how they assign each of them the secrets. So Charlie and the API get access to the Twilio key, while they also get access to the TLS cert.
This is the CLI. But what might be more interesting is the web UI. This is the graph that you've seen before. This is from our sparse-matrix example. You can see that it's similar to what we demonstrated on the screen, and then here we have each of the use matrices. Each of the results after applying that proposal. This is the first one that is not sub-optimal.
We have a series of 7 different proposals, or 7 different policies that are generated. We split the first, the input policy, into 7 different ones. And then we get this covering here. We end up with each of the black dots represents a check mark, it represents a required authorization. Something that you cannot remove without breaking the system. You can see that this is a perfect covering. So this is zero unnecessary risk. But it does have 7 policies.
As we go, we can start to see introduction of a little bit more risk. We can start seeing that this policy here starts giving some unnecessary risk. As we keep going, we see the trade-off is starting to come into effect. We're starting to reduce the number of policies, and starting to get more sane configurations in terms of how complex or how psychologically acceptable they are. At the same time we end up covering a lot more spaces that we don't need to cover. This is introduction of unnecessary risk right here.
As you keep going, you can start getting into these situations where, now we've got it down. Advisor is saying, if you want me to split this into 2 policies, this is how I would do it. This is my greedy approach to doing this. And this is what you would get, this would be cleaving it into 2 policies. And you do end up eliminating a lot of the unnecessary risk here. But this would be a good example. And then ultimately, we wind up back where we started. Which is to say, this is where we initially were when we have 1 policy assigned to all of these different entities, in Advisor. In your Vault configuration. That is Vault Advisor, in a nutshell.
The project status is that it's currently a research project. The research team is pretty small, but we've been working on this for 18 months. It's finally come to fruition, we're finally ready to talk about it. The goal is general availability, so that's the direction that we're going. We will eventually publish a white paper, and we're going to see if we can publish in an academic journal as well.
And then the next thing, which I'm sure many people might be interested in, is the beta testers. We are actively recruiting beta testers, so if you want to try out Advisor, please send an email to advisorbeta@hashicorp.com, or find myself or Jon in the hallway. There's also a Slack channel in the Hashicorp Slack, Vault Advisor, if you want to chat with us then. Thank you.