Setting Up and Configuring Performance Replication
This guide goes into setting up and configuring Performance Replication for the purpose of maximizing horizontal scalability.
Intro to multi datacenter Replication
Many organizations have diverse infrastructure in geographically-distributed data centers across many clouds. For these multi-datacenter, multi-cloud users, Vault provides the critical services of secrets storage, encryption as a service, and policy and access management for those secrets.
This functionality is expected to be highly available and to scale as the number of clients and functional needs increase; at the same time, operators would like to ensure that a common set of policies are enforced globally and a consistent set of secrets and keys are exposed to applications that need to interoperate.
Vault Enterprise replication addresses both of these needs in providing consistency, scalability, and highly-available disaster recovery. Replication exists in two modes:
- Performance replication: allows geographically-distributed clusters to pair in order to increase read performance globally and scale workloads horizontally across clusters. As this happens at the cluster level, each cluster can be part of a replication set and also maintain HA characteristics.
- Disaster recover replication: ensures a standby cluster is kept synchronized with an active Vault cluster
Use cases
Vault Enterprise Replication is based on a number of common use cases:
Multi-Datacenter Deployments: A common challenge is providing Vault to applications across many datacenters in a highly-available manner. Running a single Vault cluster imposes high latency of access for remote clients, availability loss or outages during connectivity failures, and limits scalability.
Backup Sites: Implementing a robust business continuity plan around the loss of a primary datacenter requires the ability to quickly and easily failover to a hot backup site.
Scaling Throughput: Applications that use Vault for encryption-as-a-Service or cryptographic offload may generate a very high volume of requests for Vault. Replicating keys between multiple clusters allows load to be distributed across additional servers to scale request throughput.
Activating Replication
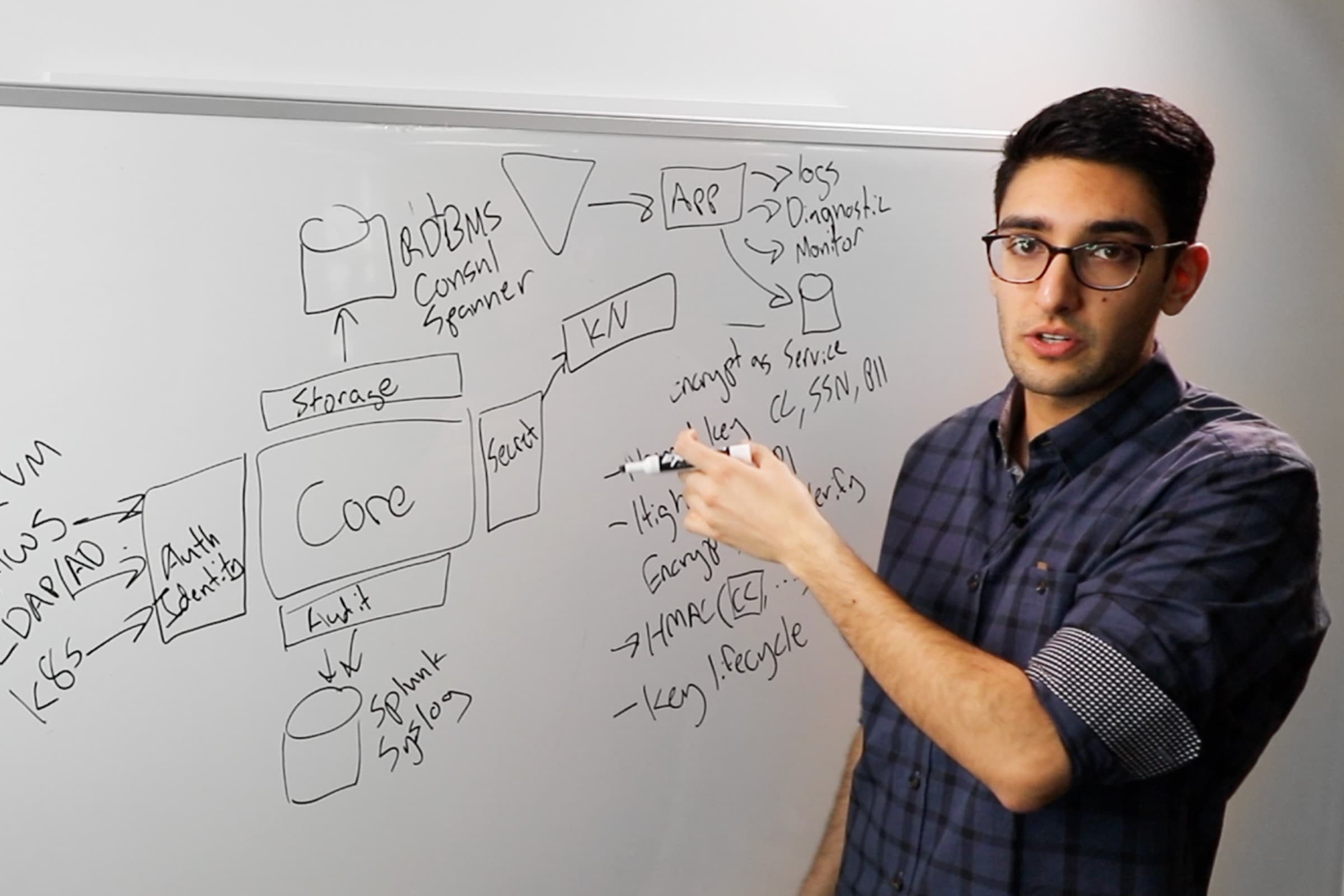
In Performance Replication, secondaries keep track of their own tokens and leases but share the underlying configuration, policies, and supporting secrets (K/V values, encryption keys for transit, etc).
If a user action modifies the underlying shared state, the secondary forwards the request to the primary to be handled; this is transparent to the client. In practice, most high-volume workloads (reads in the kv backend, encryption/decryption operations in transit, etc.) can be satisfied by the local secondary, allowing Vault to scale relatively horizontally with the number of secondaries rather than vertically.

Activating the primary
To activate the primary, run:
$ vault write -f sys/replication/performance/primary/enable
There is currently one optional argument: primary_cluster_addr. This can be used to override the cluster address that the primary advertises to the secondary, in case the internal network address/path is different between members of a single cluster and primary/secondary clusters.
Fetching a secondary token
To fetch a secondary bootstrap token, run:
$ vault write sys/replication/performance/primary/secondary-token id=<id>
The value for id is opaque to Vault and can be any identifying value you want; this can be used later to revoke the secondary and will be listed when you read replication status on the primary. You will get back a normal wrapped response, except that the token will be a JWT instead of a UUID-formatted random bytes.
Activating a secondary
To activate a secondary using the fetched token, run:
$ vault write sys/replication/performance/secondary/enable token=<token>
You must provide the full token value. Be very careful when running this command, as it will destroy all data currently stored in the secondary.
There are a few optional arguments, with the one you'll most likely need being primary_api_addr, which can be used to override the API address of the primary cluster; otherwise the secondary will use the value embedded in the bootstrap token, which is the primary’s redirect address. If the primary has no redirect address (for instance, if it's not in an HA cluster), you'll need to set this value at secondary enable time.
Once the secondary is activated and has been bootstrapped, it will be ready for service and will maintain state with the primary. It is safe to seal/shutdown the primary and/or secondary; when both are available again, they will synchronize back into a replicated state.
Note: if the secondary is in an HA cluster, you will need to ensure that each standby is sealed/unsealed with the new primary's unseal keys. If one of the standbys takes over on active duty before this happens it will seal itself to remove it from rotation (e.g. if using Consul for service discovery), but if a standby does not attempt to take over, it will throw errors.
Dev-Mode root tokens
To ease development and testing, when both the primary and secondary are running in development mode, the initial root token created by the primary (including those with custom IDs specified with -dev-root-token-id) will be populated into the secondary upon activation. This allows a developer to keep a consistent ~/.vault-token file or VAULT_TOKEN environment variable when working with both clusters.
On a production system, after a secondary is activated, the enabled auth methods should be used to get tokens with appropriate policies, as policies and auth method configurations are replicated.
The generate-root command can also be used to generate a root token local to the secondary cluster.
Understanding the Replication security model
Vault is trusted all over the world to keep secrets safe. As such, we have put extreme attention to detail to our replication model as well.
Primary/secondary Communication
When a cluster is marked as the primary it generates a self-signed CA certificate. On request, and given a user-specified identifier, the primary uses this CA certificate to generate a private key and certificate and packages these, along with some other information, into a replication bootstrapping bundle, a.k.a. a secondary activation token. The certificate is used to perform TLS mutual authentication between the primary and that secondary.
This CA certificate is never shared with secondaries, and no secondary ever has access to any other secondary’s certificate. In practice this means that revoking a secondary’s access to the primary does not allow it to continue replication with any other machine; it also means that if a primary goes down,there is full administrative control over which cluster becomes primary. An attacker cannot spoof a secondary into believing that a cluster the attacker controls is the new primary without also being able to administratively direct the secondary to connect by giving it a new bootstrap package (which is an ACL-protected call).
Vault Enterprise makes use of Application Layer Protocol Negotiation on its cluster port. This allows the same port to handle both request forwarding and replication, even while keeping the certificate root of trust and feature set different.
Secondary activation tokens
A secondary activation token is an extremely sensitive item and as such is protected via response wrapping. Experienced Vault users will note that the wrapping format for replication bootstrap packages is different from normal response wrapping tokens: it is a signed JWT. This allows the replication token to carry the redirect address of the primary cluster as part of the token. In most cases this means that simply providing the token to a new secondary is enough to activate replication, although this can also be overridden when the token is provided to the secondary.
Secondary activation tokens should be treated like Vault root tokens. If disclosed to a bad actor, that actor can gain access to all Vault Enterprise data. It should therefore be treated with utmost sensitivity. Like all response-wrapping tokens, once the token is used successfully (in this case, to activate a secondary) it is useless, so it is only necessary to safeguard it from one machine to the next. Like with root tokens, HashiCorp recommends that when a secondary activation token is live, there are multiple eyes on it from generation until it is used.
Once a secondary is activated, its cluster information is stored safely behind its encrypted barrier.
Understanding Replication's internal architecture
The architecture of Vault replication is focusing on the intended use cases. When replication is enabled, a cluster is set as either a primary or secondary. The primary cluster is authoritative, and is the only cluster allowed to perform actions that write to the underlying data storage, such as modifying policies or secrets. Secondary clusters can service all other operations, such as reading secrets or sending data through transit and forward any writes to the primary cluster. Disallowing multiple primaries ensures the cluster is conflict free and has an authoritative state.

The primary cluster uses log shipping to replicate changes to all of the secondaries. This ensures writes are visible globally in near real-time when there is full network connectivity. If a secondary is down or unable to communicate with the primary, writes are not blocked on the primary and reads are still serviced on the secondary. This ensures the availability of Vault. When the secondary is initialized or recovers from degraded connectivity it will automatically reconcile with the primary.
Lastly, clients can speak to any Vault server without a thick client. If a client is communicating with a standby instance, the request is automatically forwarded to an active instance. Secondary clusters will service reads locally and forward any write requests to the primary cluster. The primary cluster is able to service all request types.
An important optimization Vault makes is to avoid replication of tokens or leases between clusters. Policies and secrets are the minority of data managed by Vault and tend to be relatively stable. Tokens and leases are much more dynamic, as they are created and expire rapidly. Keeping tokens and leases locally reduces the amount of data that needs to be replicated, and distributes the work of TTL management between the clusters. The caveat is that clients will need to re-authenticate if they switch the Vault cluster they are communicating with.
Implementation Details
It is important to understand the high-level architecture of replication to ensure the trade-offs are appropriate for your use case. The implementation details may be useful for those who are curious or want to understand more about the performance characteristics or failure scenarios.
Using replication requires a storage backend that supports transactional updates, such as Consul. This allows multiple key/value updates to be performed atomically. Replication uses this to maintain a write-ahead-log (WAL) of all updates, so that the key update happens atomically with the WAL entry creation. The WALs are then used to perform log shipping between the Vault clusters. When a secondary is closely synchronized with a primary, Vault directly streams new WALs to be applied, providing near real-time replication. A bounded set of WALs are maintained for the secondaries and older WALs are garbage collected automatically.
When a secondary is initialized or is too far behind the primary there may not be enough WALs to synchronize. To handle this scenario, Vault maintains a merkle index of the encrypted keys. Any time a key is updated or deleted, the merkle index is updated to reflect the change. When a secondary needs to reconcile with a primary, they compare their merkle indexes to determine which keys are out of sync. The structure of the index allows this to be done very efficiently, usually requiring only two round trips and a small amount of data. The secondary uses this information to reconcile and then switches back into WAL streaming mode.
Performance is an important concern for Vault, so WAL entries are batched and the merkle index is not flushed to disk with every operation. Instead, the index is updated in memory for every operation and asynchronously flushed to disk. As a result, a crash or power loss may cause the merkle index to become out of sync with the underlying keys. Vault uses the ARIES recovery algorithm to ensure the consistency of the index under those failure conditions.
Log shipping traditionally requires the WAL stream to be synchronized, which can introduce additional complexity when a new primary cluster is promoted. Vault uses the merkle index as the source of truth, allowing the WAL streams to be completely distinct and unsynchronized. This simplifies administration of Vault Replication for operators.
Caveats
Read-After-Write Consistency: All write requests are forwarded from secondaries to the primary cluster in order to avoid potential conflicts. While replication is near real-time, it is not instantaneous, meaning there is a potential for a client to write to a secondary and a subsequent read to return an old value. Secondaries attempt to mask this from an individual client making subsequent requests by stalling write requests until the write is replicated or a timeout is reached (2 seconds). If the timeout is reached, the client will receive a warning.
Stale Reads: Secondary clusters service reads based on their locally-replicated data. During normal operation updates from a primary are received in near real-time by secondaries. However, during an outage or network service disruption, replication may stall and secondaries may have stale data. The cluster will automatically recover and reconcile any stale data once the outage has recovered, but reads in the intervening period may receive stale data.
Intro to Performance Replication
Performance replication allows for synchronized secrets management across multiple locations, enabling flexible horizontal scalability. Features include:
- Secret access from any location, with centralized management
- One to many replication
- Write-ahead logs for efficient replication (using Merkle-trees)
- Asynchronous - i.e. replicates changes to all of the secondary clusters. Replication occurs for secrets, policies, secret backends configurations, auth backends configurations, and audit backends configurations. Note that access tokens are NOT replicated
Below, we will walk through an example of how performance replication can be configured.
Example configuration
Below is the basic architecture for two clusters where the primary cluster is the authoritative cluster - i.e. the only cluster allowed to perform writes to the underlying data storage. The secondary cluster services all other operations.
For example, the primary cluster is responsible for modifying policies or secrets and the secondary cluster is reponsible for reading secrets or sending data through transit. In this case, writes are forwarded to the primary cluster.

If a secondary is down or unable to communicate with the primary, writes are not blocked on the primary and reads are still serviced on the secondary. See below.


An operator can also manually promote a new primary.

Best practices
Vault’s performance replication model is intended to allow horizontally scaling Vault’s functions rather than to act in a strict Disaster Recovery (DR) capacity. For more information on Vault's disaster recovery replication, look at the general information page.
As a result, Vault performance replication acts on static items within Vault, meaning information that is not part of Vault’s lease-tracking system. In a practical sense, this means that all Vault information is replicated from the primary to secondaries except for tokens and secret leases.
Because token information must be checked and possibly rewritten with each use (e.g. to decrement its use count), replicated tokens would require every call to be forwarded to the primary, decreasing rather than increasing total Vault throughput.
Secret leases are tracked independently for two reasons: one, because every such lease is tied to a token and tokens are local to each cluster; and two, because tracking large numbers of leases is memory-intensive and tracking all leases in a replicated fashion could dramatically increase the memory requirements across all Vault nodes.
We believe that this performance replication model provides significant utility for horizontally scaling Vault’s functionality. However, it does mean that certain principles must be kept in mind.
Always use the local cluster
First and foremost, when designing systems to take advantage of replicated Vault, you must ensure that they always use the same Vault cluster for all operations, as only that cluster will know about the client’s Vault token.
Enabling a secondary wipes storage
Replication relies on having a shared keyring between primary and secondaries and also relies on having a shared understanding of the data store state. As a result, when replication is enabled, all of the secondary’s existing storage will be wiped. This is irrevocable. Make a backup first if there is a remote chance you’ll need some of this data at some future point.
Generally, activating as a secondary will be the first thing that is done upon setting up a new cluster for replication.
Replicated vs. local backend mounts
All backend mounts (of all types) that can be enabled within Vault default to being mounted as a replicated mount. This means that mounts cannot be enabled on a secondary, and mounts enabled on the primary will replicate to secondaries.
Mounts can also be marked local (via the -local flag on the Vault CLI or setting the local parameter to true in the API). This can only be performed at mount time; if a mount is local but should have been replicated, or vice versa, you must disable the backend and mount a new instance at that path with the local flag enabled.
Local mounts do not propagate data from the primary to secondaries, and local mounts on secondaries do not have their data removed during the syncing process. The exception is during initial bootstrapping of a secondary from a state where replication is disabled; all data, including local mounts, is deleted at this time (as the encryption keys will have changed so data in local mounts would be unable to be read).
Audit devices
In normal Vault usage, if Vault has at least one audit device configured and is unable to successfully log to at least one device, it will block further requests.
Replicated audit mounts must be able to successfully log on all replicated clusters. For example, if using the file audit device, the configured path must be able to be written to by all secondaries. It may be useful to use at least one local audit mount on each cluster to prevent such a scenario.
Never have two primaries
The replication model is not designed for active-active usage and enabling two primaries should never be done, as it can lead to data loss if they or their secondaries are ever reconnected.
Considerations related to unseal behavior
If using replication with Vault clusters integrated with HSM devices for automated unseal operations, take the below precautions. * If a Performance primary cluster utilizes an HSM, all other clusters within that replication set must use an HSM as well. * If a Performance primary cluster does not utilize an HSM (uses Shamir secret sharing method), the clusters within that replication set can be mixed, such that some may use an HSM, others may use Shamir.
For sake of this discussion, the cloud auto-unseal feature is treated as an HSM.
Disaster recovery replication
Local backend mounts are not replicated and their use will require existing DR mechanisms if DR is necessary in your implementation.
If you need true DR, look at the general information page for information on Vault's disaster recovery replication.
Additional notes
- There is no set limit on number of clusters within a replication set. Largest deployments today are in the 30+ cluster range.
- Any cluster within a performance replication set can act as a Disaster Recovery primary cluster.
- A cluster within a performance replication set can also replicate to multiple disaster recovery secondary clusters.
- While a Vault cluster can possess a replication role (or roles), there are no special considerations required in terms of infrastructure, and clusters can assume (or be promoted) to another role. Special circumstances related to mount filters and HSM usage may limit swapping of roles, but those are based on specific organization configurations.
- For more information on using replication API. Please see the Vault Replication API documentation