HashiConf 2018 Keynote: Vault 1.0
Here's your first look at Vault 1.0, with HashiCorp co-founder and CTO Armon Dadgar.
Speakers
 Armon DadgarCo-founder & CTO, HashiCorp
Armon DadgarCo-founder & CTO, HashiCorp

Transcript
Now that we’re talking about Vault, I want to switch gears a little bit and start talking about product updates. When we first released Vault 0.1, it was April 2015. At the time, it started out as an internal tool. We built it for ourselves at HashiCorp. We had no intention of open-sourcing it. It was for us to manage our own internal usernames and passwords, API keys, certificates.
We had this interesting challenge of, “OK, we’re using Packer and Terraform and our own tools. How do we do secrets management in a way that’s automated but also secure?” It was born out of that need internally, and it was pressure from our community, folks like you, to say, “Hey, how do we solve this problem?” that drove us to open-sourcing it.
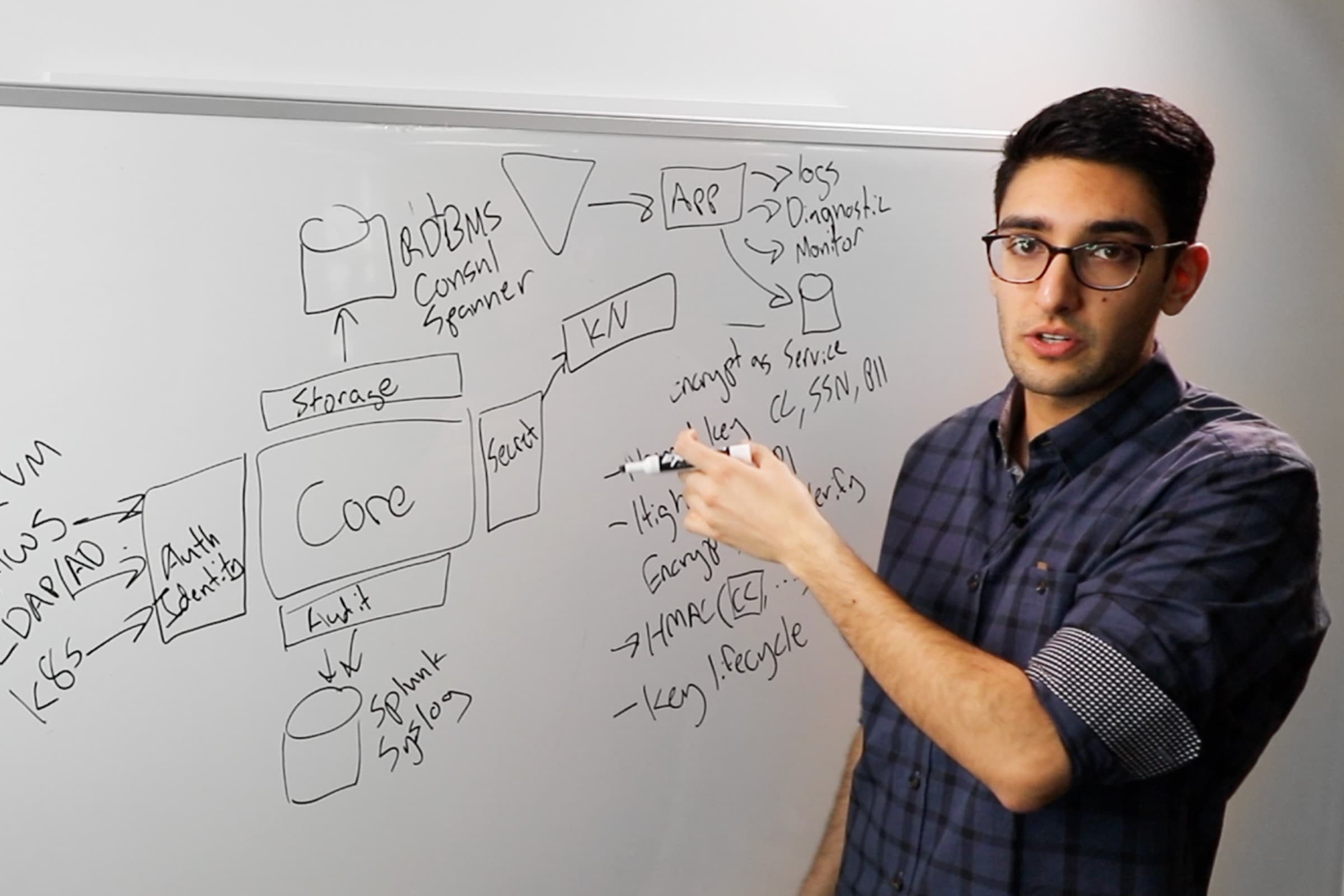
Our original focus, like I said, was thinking about secret data that lives within Vault, usernames, passwords, API keys, tokens, certificates, all that good stuff. What quickly became apparent to us is there’s this whole other class of data that doesn’t live within Vault, or sensitive data. Credit card numbers, transaction information, user details, PII, all sorts of data that we’re not putting in Vault, we’re putting in databases or data lakes, other things like that. How are we securing this?
What we tend to see in practice is, if it’s being secured at all, it’s being secured by an application that’s doing cryptography itself. The application is managing a set of encryption keys and it’s encrypting the data before it’s writing to the database, typically. The bad part about this, what makes us uncomfortable, is, “How many of these applications are implementing the cryptography correctly?”
If you do an audit, it’s very few. There are a lot of nuances to getting crypto correct, and so a lot of applications don’t. As we talk about key management, that’s also an issue.
So we expanded Vault and said, “How do we look at solving the sensitive-data problem?” We added a new backend we called Transit. The idea behind Transit was we’d define a set of named encryption keys—credit card, PII logs, things like that. Then we could use a high-level set of cryptographic operations to go and do encrypt, decrypt, sign, verify, things like that. As a web client, I just consume Vault to protect my sensitive data.
As we spent time thinking about this leakage problem, we realized there was a bigger issue of credential leakage. An application would come up, it would talk to Vault and say, “I need a database key to go talk to my database.” At the same time, it’s going to log that out to a config and say, “Here is my configuration with my username and password.” When there’s an exception, it’s going to capture that in a traceback and send it out to our APM system, or our monitoring tools will end up getting it, or it’ll go into our diagnostic pages. We render a 500 error and put our database password on it, etc.
The applications tend to be leaky buckets. They are not designed in a way that’s assuming that they have to keep these credentials secure. They’re leaking them all over the place. It’s not just encryption keys.
The other problem we have is thinking about privileged operators. We have these administrators that are either database administrators, or system operators that need to be able to have access to these end systems to do what they need to do. What happens is, they change roles. Or, more scary to think about, what happens when they leave the company? Did they take any of these credentials with them? They needed them to operate. What prevents them from just writing it on a piece of paper and taking it?
This brought us to the idea of dynamic secrets. The idea here is we create these secrets just in time, when the client asks for it. The client comes in and says, “I need a database credential.” Vault goes and creates one on demand. It’s unique per client and auto-expiring. This way, if the application leaks it, or an operator takes it with them, we’re automatically rotating and revoking those credentials all the time.
This was a feature that was landed as part of Vault 0.1. At the time, we were only thinking about it through the lens of databases—what prevents leakage of database credentials? All the classic things MySQL, Postgres, MSSQL, all that kind of stuff, were supported as part of this. Over time, we realized this applies to other systems as well. NoSQL systems have the same problem.
As we talk about our cloud providers, they also have the same problem. We have maybe an IM token that allows you to read from S3, but we don’t want you to have permanent access if you leave the business. Things like applications or messaging queues like RabbitMQ, and so on. Other applications like Active Directory service accounts, TLS certificates, SSH brokering. You don’t want the master PIN file that allows you to SSH into everything. We expand this dynamic secrets capability to a broad range of systems, looking at, “How do you only give time-bounded access so that you don’t have to worry about these credentials leaking forever?”
The other thing we’ve been focused a lot on over the last year has been improving the user experience. This is both in the CLI as well as the web UI. Both have been totally revamped to figure out, “How do we make this a much richer experience that’s easier to use, but has more of a coverage of Vault’s API?” Historically, this has only covered a small bit of Vault’s total surface, so we’re trying to fill that out.
In addition, we’ve added what we jokingly refer to as “Clippy for Vault,” a getting-started wizard. “It looks like you’re trying to add a secret. Can I help you?”
We joke about it, but a system like Vault is very complex. It has many different knobs, many different features. How do we make it easier to get started? Like, “OK, if you do want to set up a new engine—maybe you’re trying to set up an AWS IM generator—there are a bunch of parameters. How do we help walk you through that and make it a little bit more intuitive, how you set up Vault?” Luckily, we decided not to give it any cheesy clip art.
The other big investment in Vault has been, “How do we make it accessible for the enterprise?” That’s a different set of challenges, because there’s a different set of requirements there. We first released Vault Enterprise in 2016. What we first looked at was, “What are the hardware integrations that are required in an enterprise setting?”
That’s where we started. From there, you see, there’s a gamut of operational challenges, from multi-data center replication, to real-time backup, to administrative challenges like multi-tenancy and policy sandboxing. Those have all iterated on over time, to make it more suitable in an enterprise environment.
Today, what you see is a much, much more mature Vault than what we had in our 0.1. We’ve had 45 releases since then. These have brought many new features and production hardening of the system. Today, it’s very broadly adopted by the user community, and it’s mission-critical for many of our customers.
We were very excited: This year, we won the OSCON 2018 Breakout Project of the Year Award.
All of this makes us very excited to talk about that journey from Vault 0.1, bringing us all the way to Vault 1.0, which we’re super excited to be able to announce today. The preview will be available today. You can go online, download it, start kicking the tires. It should be the Vault you know and love, just with a little bit rounder of a version number.
As we talk about the HashiCorp 1.0s, I think this is an interesting topic for us. We often get asked about it: “Why do you have these tools that you have millions of users on these things and it’s still a 0.8 or something like that?” It goes against what we tend to see in industry.
I think for us, it comes to, “What is the bar we want to set for ourselves? What does a 1.0 mean to HashiCorp? For us, what it means is, “Do we understand what are all the major use cases of this tool? And is it supported at that 95, 99 percentile mark?” If you say, “I’m using Vault for one of the 3 main use cases,” can 99% of users just use it out of the box and it works at their scale, it works at their level of SLA, it has all the features they need? That’s a major milestone for us.
The other thing is, as these products evolve, their core architectures change. You end up realizing, “Oh, at this particular scale, we need to do this data handling in a different way. Or we need data to replicate in a different way.” These architectures change and evolve over time, as you see different use cases, different scales. We have to feel like the architecture is at a mature point in time, where it’s not going to be under rapid churn. It has to have this stable implementation that we know works at scale.
The other part of it is understanding, “What is the workflow and UX? Do we feel like that’s been refined to a point that we’re happy with? Or is there still a lot of rough edges we need to sand down?”
The last part is, “Things need time to bake.” There’s really no way around that. There’s a certain class of bug that is only found in production. We feel like there has to be a broad deployment of the tool, there has to be broad usage, so that it gets that production hardening. There is no amount of unit testing that is the same as production. Those all have to be there before we’re comfortable calling it a 1.0 release.
Auto-unseal for Vault open source
Along with the 1.0, it’s not just a version number change; there are new features as well. A big ask for a long time has been, “How do we get access to the auto-unsealing feature of Enterprise in the open-source version?” With 1.0, we’re graduating that out of Enterprise and making it available in the open source.
Like I said, there was a lot of community ask for it, as you can tell. This is going to be AliCloud, AWS, Azure, and Google from the get-go. This will allow you to automate the unseal of Vault much more easily in automated provisioning.
For users that are already on Vault that want to make use of this feature, we’re making it super easy to do that migration. When you do unseal, you’ll basically say, “I want to migrate away from Shamir and toward auto-unseal.” Once the key holders provide their keys, Vault will flip over to using the new mechanism and from then on will use the auto-unseal capability.
If you decide at any point you want manual control back, you want to be able to tightly control when the unseal happens yourself, you can always migrate away from auto-unseal back toward Shamir. It’s not a one-way operation. You can go back and forth as you like.
Batch tokens
Another big feature we’ve been looking at is, “How does Vault fit into environments that are more edge-case-y?” Particularly when we talk about serverless environments or high-scale batch processing. What makes these environments unique is they’re very high-scale and bursty, but short-lived. These Lambda functions, you might have a thousand that come up, they process for 30 seconds, and they go away. They’re going to create a whole bunch of traffic against Vault all of a sudden and then disappear.
This is an interesting use case for us. The challenge, historically, is Vault’s token, when it returns to you, is just a flat UUID. All of your session’s state is maintained server-side by Vault. When this burst shows up, we create a whole bunch of session state that is then garbage. It’s valid for 30 seconds, and then you’re not using it anymore. It’s a bunch of stuff Vault has to keep track of, and over time this can cause performance issues if you keep having this bursty behavior.
Batch tokens are a new way of looking at this problem, specifically looking at batch-type use cases, which are short-lived and bursty. What we do is invert it. Instead of handing the client a UUID and maintaining state server-side, what we did is encrypt the whole session state and hand back an encrypted session to the client.
Only Vault can decrypt it and look at what the session state is. “Are you still authorized?” What this lets us do is eliminate the server-side state and handle these batch cases much more gracefully. Even for applications that need to do thousands of authentications a second, now it’s not an issue for Vault.
There are a bunch of other interesting features coming with 1.0 as well. One that’s been long asked for is migration between storage backends. You might start off with something like a cloud blob store, and then decide to migrate to Consul for higher performance, something like that.
There are a bunch of replication changes to make it more parallel, more batching, to do higher performance for customers that have millions of keys involved, as well as an open API specification for the full API. What this will let us do is auto-generate SDKs, generate documentation, mock servers. All of that stuff can be derived from the API automatically now.
There’s a lot more, but these are a few of what I wanted to highlight for 1.0.
Vault roadmap
What does the road ahead look like for Vault? There’s the immediate 1.0 release, but beyond that we have a long roadmap still planned. The way we think about Vault is as an extensible security platform. You see that when we talk about things like SSH brokering, and TLS generation and things like that. Once we have this trusted core, what is the surrounding set of security problems that we need to still solve? How do we solve those in a modular way that keeps the simplicity of Vault’s core? That’s how we see our roadmap from here: “What is that next set of challenges? How do we solve that in a way that we’re doing that modularly and not expanding the scope of Vault core?