

Jerry is currently a software engineer at Streamlio, a startup that is at the forefront of connecting, processing, and storing fast-moving data. Jerry has been working in the area of distributed systems and stream processing since his days in grad school at the University of Illinois, Urbana-Champaign. He has previously worked at Citadel and Yahoo. Jerry is also an Apache Storm committer and PMC member. Linkedin: https://www.linkedin.com/in/boyang-jerry-peng
Apache Heron is a stream processing engine (SPE) open sourced by Twitter in 2016 and now currently in incubation under the auspices of the Apache Software Foundation. At Twitter, Heron was built to provide multi-tenancy, efficient resource usage, support for a variety of programming languages and APIs, operational simplicity at massive scale, and high productivity for developers building both real-time and batch services. Today, Heron serves the lion’s share of Twitter’s massive real-time processing needs, is used by numerous large enterprises, and has a thriving open source community.
As a core contributor to Heron, I’m excited to announce that Nomad is being added as a fully supported scheduler for Heron. In this blog post, I’ll first provide a basic introduction to Heron and then talk about why and how we added Nomad support to Heron.
»Apache Heron basics
Heron is an SPE that enables you to easily run and manage stream processing applications called topologies. Processing topologies can be logically represented as directed acyclic graphs (DAGs) in which each edge represents a flow of data or events and each vertex represents an operator that uses application-defined logic (i.e. code that you write) to process data or events from adjacent edges.
In processing graphs, vertices (operators) can be split up into two types: sources and sinks. Sources consume external data/events and inject them into the processing graph while sinks typically gather results produced by the graph. In Heron, source operators are referred to as spouts (think of a faucet pouring data into the graph) and non-source operators—sink operators or regular operators—are referred to as bolts. Spouts and bolts are the constitutive components of a Heron topology. You can see a diagram of DAGs, Heron topologies, and how the components of each line up in Figure 1.
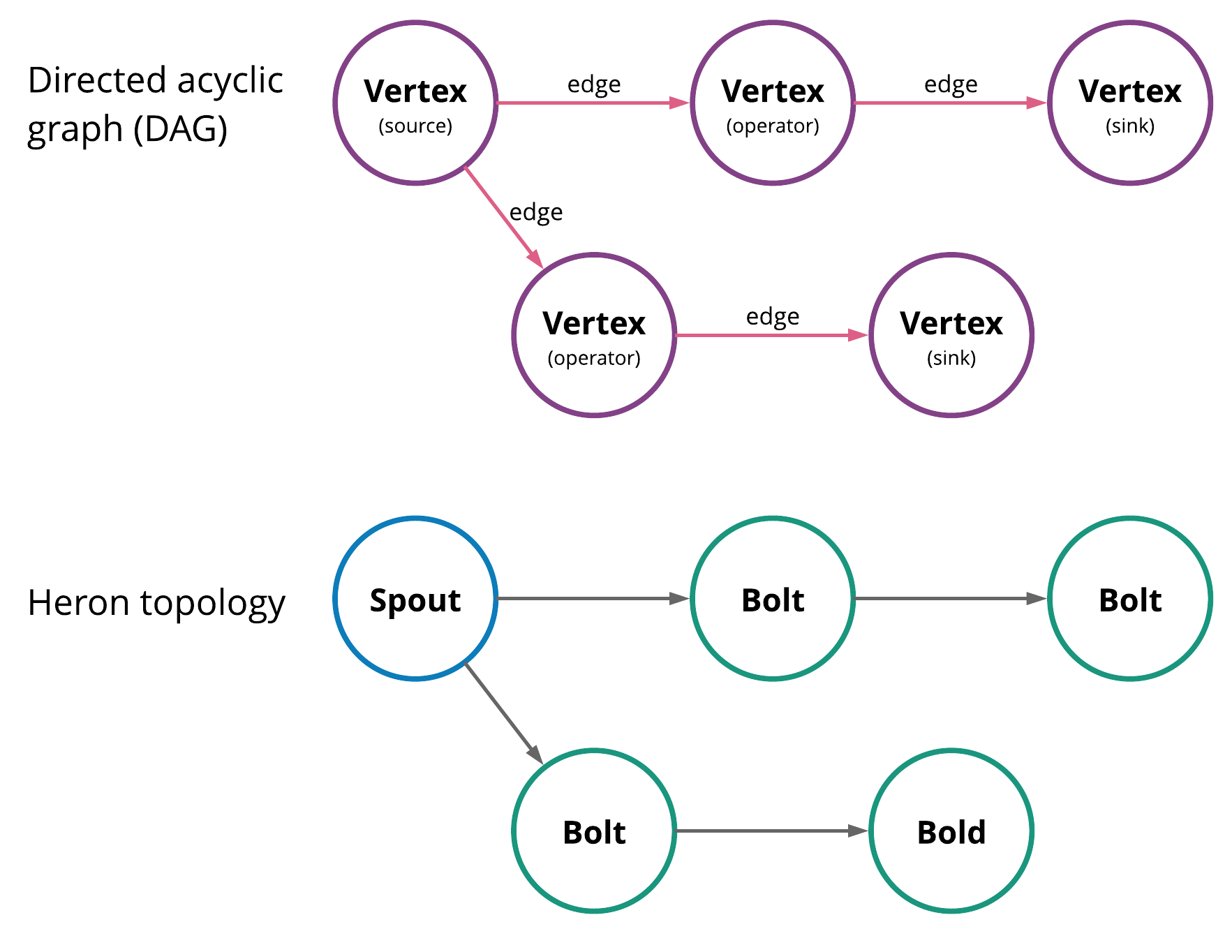
In a Heron topology, spouts feed data into the processing graphs and bolts process that data. Figure 2 below shows an example topology.
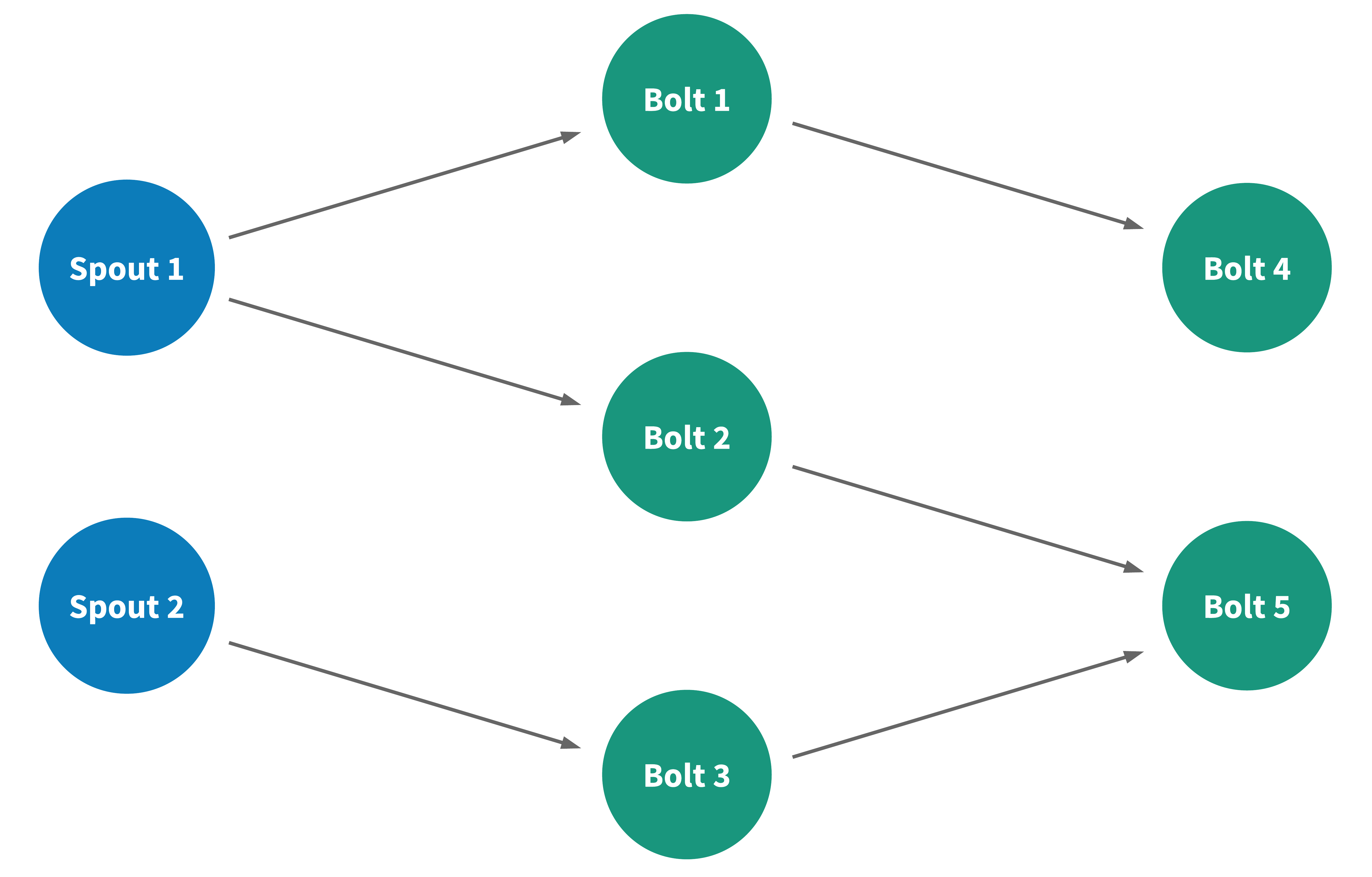
In this topology, there are two spouts, spout 1 and spout 2. Spout 1 produces two data streams, one consumed by bolt 1 and the other by bolt 2. Similarly, spout 2 produces a data stream that is consumed by bolt 3. Bolts 1, 2, and 3 each process their incoming data streams and produce an output stream. Bolt 4 consumes the stream produced by bolt 1 while bolt 5 takes input two streams produced by bolt 2 and bolt 3.
»Logical plan and physical plan
The processing logic for Heron topologies can be written using a variety of languages (including Java and Python) and APIs (including the more procedural Storm API and the more functional Streamlet API). When you create a topology using one of these languages/APIs, Heron automatically converts the processing logic you created for your topology first into a logical plan of the processing graph (like the one in Figure 2) and then into a physical plan of how the various topology processes will actually run the different topology components (the spouts and bolts).
The physical plan is where the scheduler comes in. Heron doesn’t act as a scheduler for topology processes. Instead, Heron manages topology instances—activating them, killing them, updating them, etc.—in conjunction with an external scheduler rather than doing that work directly. Heron initially supported the Apache Aurora scheduler (which Twitter uses for its internal needs), but Heron’s extensible nature has enabled the community to add support for a wide variety of schedulers, including Mesos, YARN, and Kubernetes.
»Word count topology
To give a more concrete example than the hypothetical topology in Figure 2, imagine a topology that counts the distinct set of words in a live stream of tweets. This topology, depicted in Figure 3, consists of one spout and two bolts.
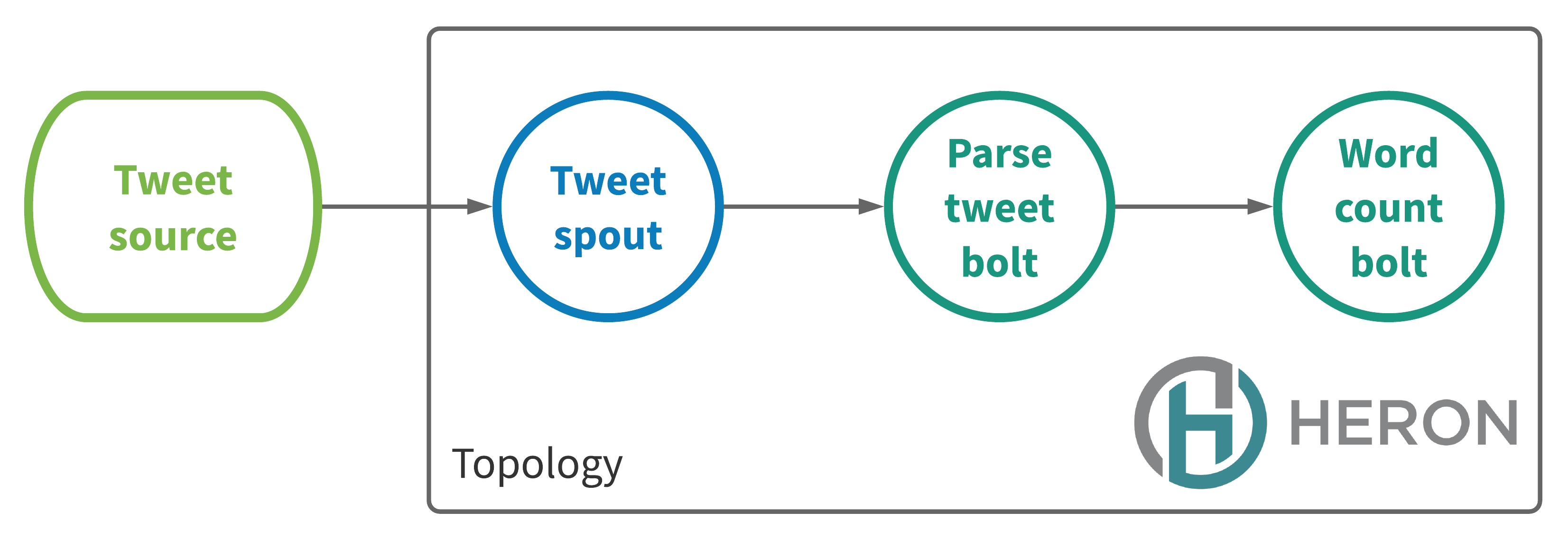
The tweet spout taps into a tweet source, for example the Twitter API, and injects the tweet stream into the topology. The tweet stream is then consumed by the parse tweet bolt, which breaks the tweet into a set of distinct words. These words are emitted as a word stream and consumed by the word count bolt that counts the words. That word count bolt periodically outputs pairs representing specific words and and their count of occurrence.
»Parallelism
One way to run the word count topology above would be to simply run each component (i.e. each spout and bolt) as a single process. But for many use cases you would need to run several instances of each component, for example 5 instances of the tweet spout, 3 instances of the parse tweet bolt, and so on. Developers can specify the parallelism of each component when creating their topology, and Heron will do the rest, routing data streams between component instances and using the scheduler, for example Nomad, to run the components.
Figure 4 depicts the topology shown in Figure 2 with parallelism. Here, bolt 1, for example, has a parallelism of 2, bolt 2 has a parallelism of 3, and so on.
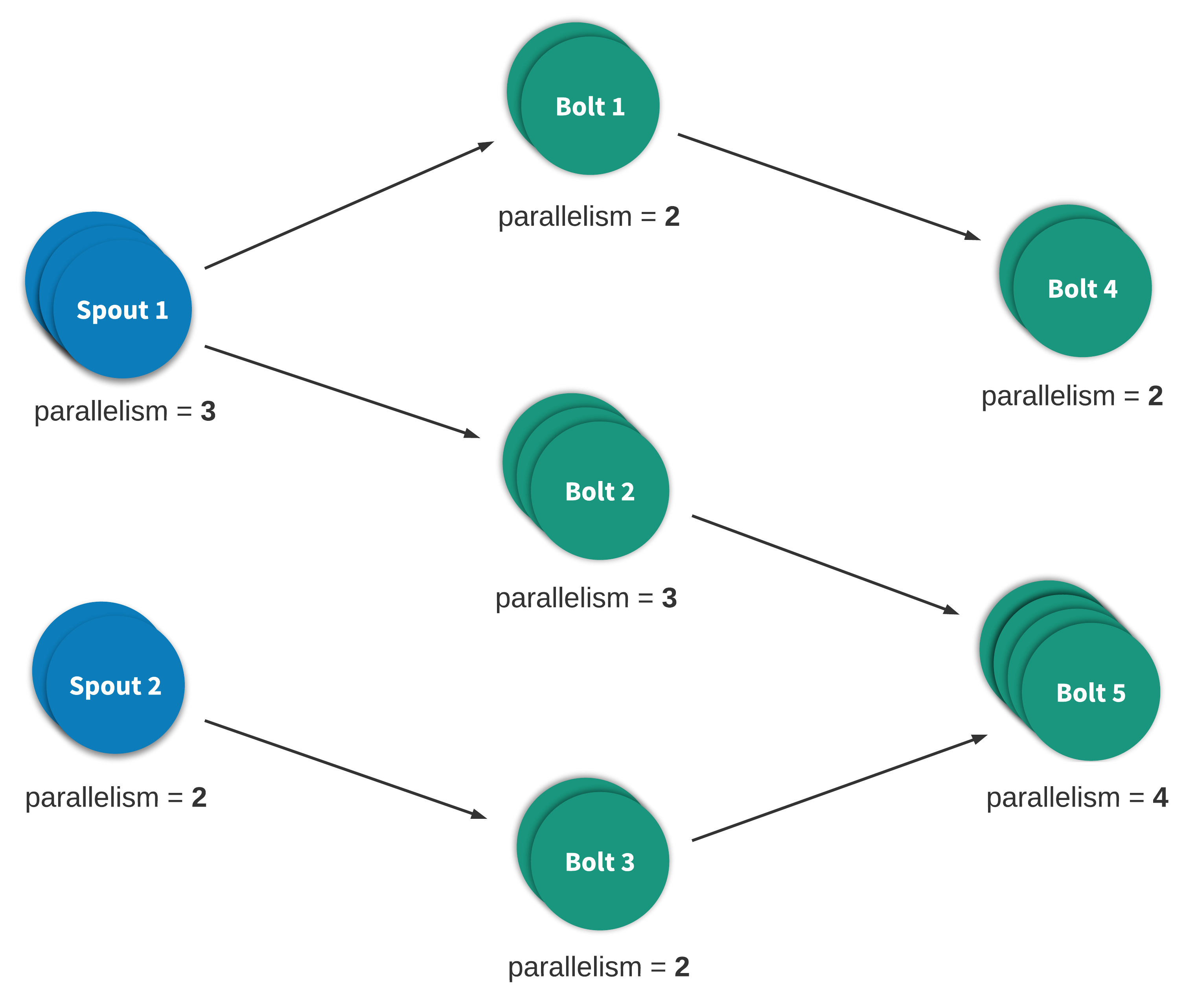
Parallelism is a method for users to scale out the computation of a component based on need. Typically, the parallelism of a component is specified based on the incoming data rate, outgoing data rate, and the computational intensity of component, but you’re free to use your own criteria to make those decisions.
»Heron Use Cases
To highlight some actual use cases of Heron, let us first talk about some of the notable use cases of Heron at Twitter.
- Abuse detection - Heron is used to analyze continuous live data at Twitter to find fake or abusive accounts, so proactive actions can be taken to take down those accounts and tweets from those accounts.
- Real-time trends - Twitter uses Heron to continuously compute trends that emerge by examining all Tweet data. Breaking news and hashtag trends are continuously computed and the results delivered to end users
- Online machine learning - Models are continuously updated as new data arrives.
- Real-time classification - Various media uploaded to twitter, e.g. photos, videos, etc, are classified in real-time based on features extracted from them.
- Operations - Twitter runs datacenters that span all five continents that consist of hundreds of thousands of machines. Statistics and logs are analyzed by Heron in real-time to monitor the health of clusters and predict impending failures.
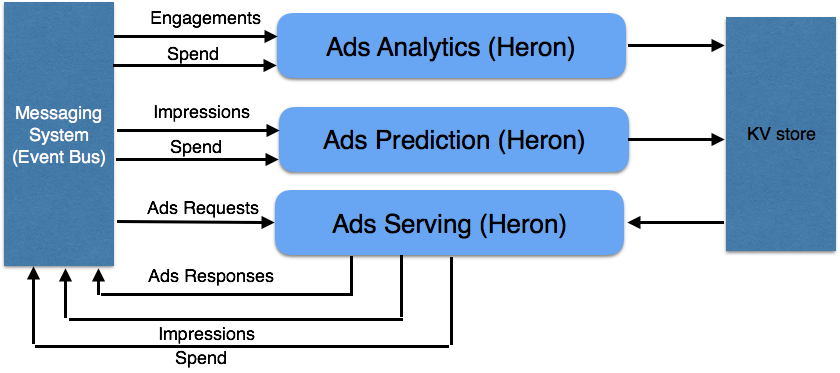
Let’s take a deeper dive into a couple of Heron’s use cases. A classical use case of low latency data stream processing is in the area of ad serving. At Twitter, real-time data concerning ad engagements, impressions, and requests are first collected by a messaging system called Event Bus. That data is then injected into Heron topologies to be processed and the results get either sent to a key-value store (Manhattan) or potentially delivered into Event Bus. The results can be used to track the performance of certain ad campaigns and monitor ad spending for a end user in real-time so that he or she is within budget. Figure 5 depicts the architecture of this use case.
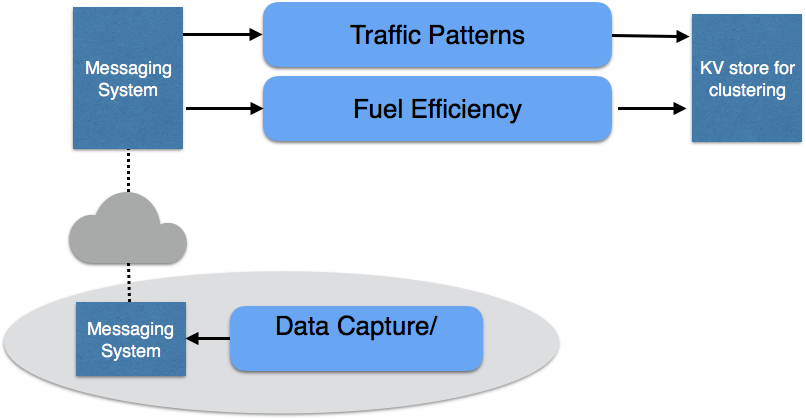
Another interesting use case arises outside of Twitter. As we enter the age of IoT (Internet of Things) and every aspect of our lives have become connected, so have our cars. There has been an initiative in the automotive industry to make our cars smarter using real-time analytics. Real-time statistics about a car’s performance, driving habits, etc are collected by a messaging system. From there, such real-time stats data from all connected cars are injected into Heron for analysis to make real-time predictions on fuel efficiency and traffic patterns for certain routes, predict failures in your car, and much more. Such analysis is incredibly valuable to determine the terms of pay-as-you-go car insurance. Figure 6 depicts the architecture for this use case.
»Heron on Nomad
I’ve been excited about HashiCorp Nomad for years. Schedulers are crucial components in many large-scale software systems, and Nomad is powerful, it provides a straightforward API and simple abstractions (such as jobs), and its distribution as a precompiled binary makes deployment a breeze. It also has great documentation and a very nice UI. Building out Nomad support for Heron was surprisingly simple and, I believe, a big win for the project.
Not only can Apache Heron now be run using an existing Nomad cluster—potentially in a large-scale production environment—but we also chose Nomad to be used as the scheduler for Apache Heron’s so-called standalone cluster mode due to Nomad’s operational simplicity (more on that below). Standalone cluster mode allows users to quickly and easily set up a lightweight distributed cluster to run Apache Heron processing topologies on their own machine, and thus to have a ready-made development and testing environment with very little effort.
Even better, when using Nomad with the raw fork/exec driver, the user doesn’t even need admin/root privileges to run the cluster. Integrating Heron with Nomad potentially lowers the barrier to entry for many users.
Figure 7 shows how Heron uses Nomad to manage topologies:
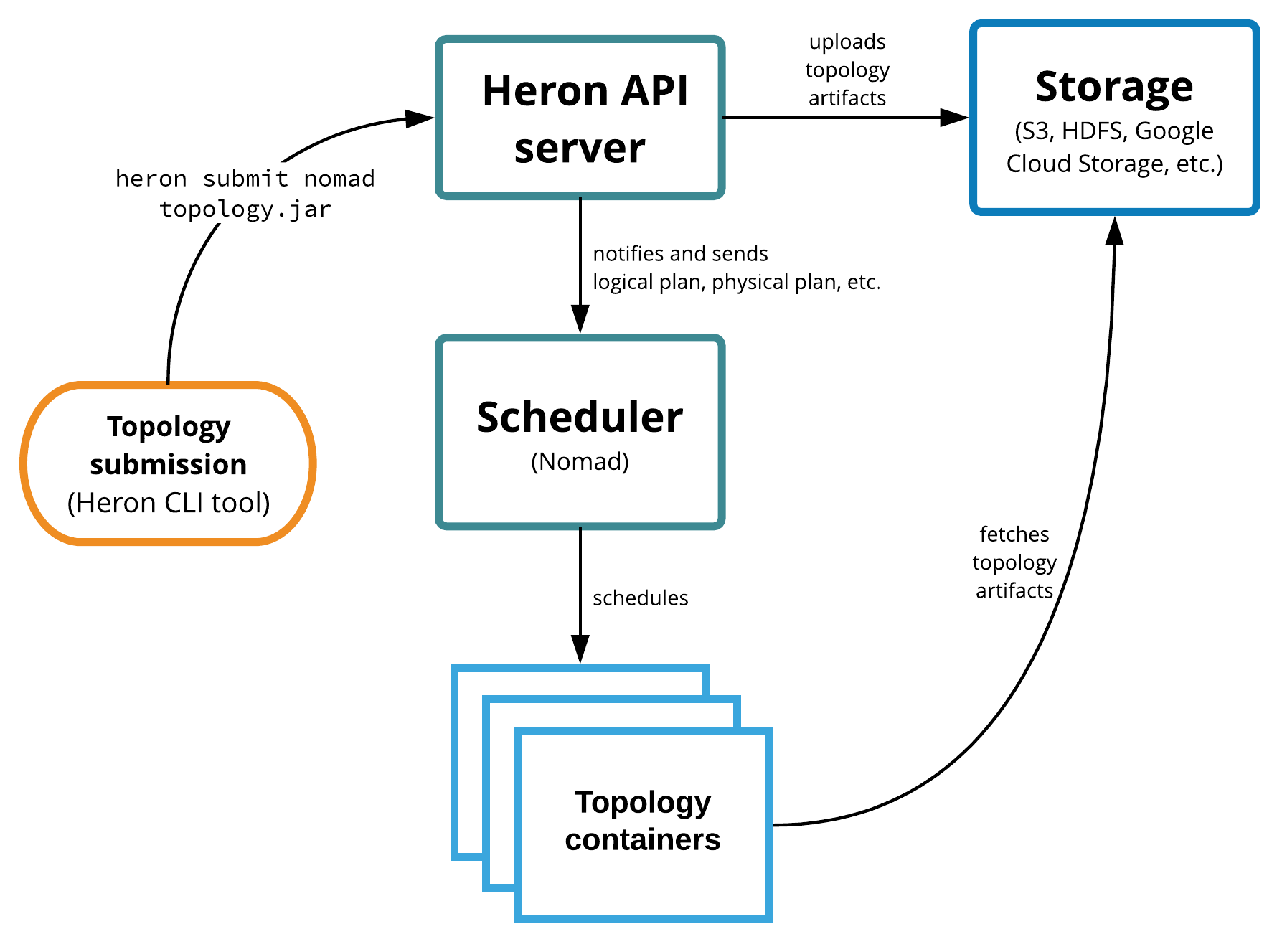
When you submit a new topology to Heron using the Heron CLI, it interacts with the Heron API server, which creates a logical and physical plan for the topology and uploads any topology artifacts to a storage system (this aspect of Heron is also highly configurable/extensible). The API server then provides Nomad with a logical and physical plan for the topology. Nomad then uses uploaded topology artifacts to schedule actual topology spout and bolt instances (containers) as Nomad jobs.
Figure 8 below shows what a physical plan for a topology might look like, with the topology’s spout and bolt instances spread across containers.
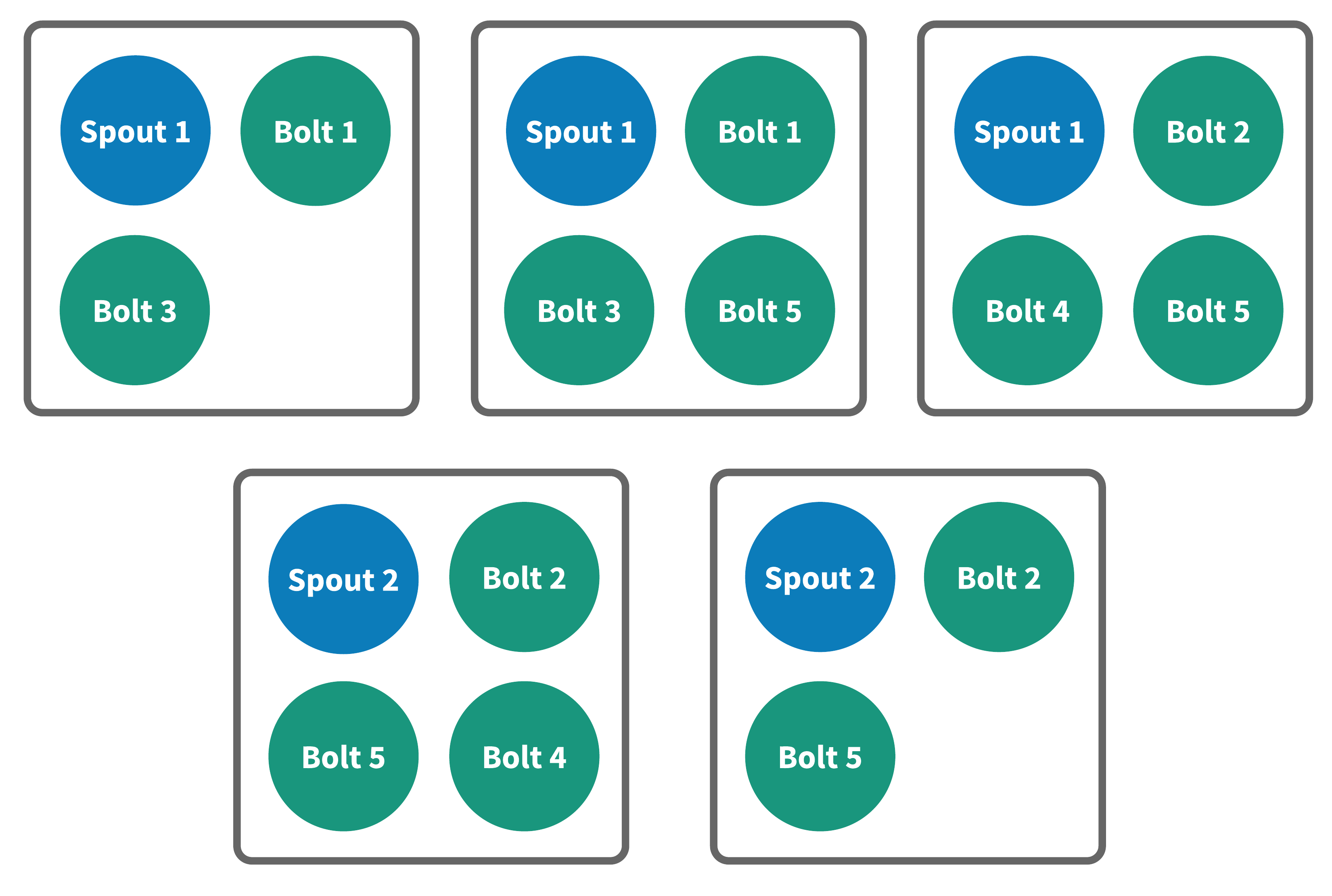
The physical plan for this topology consists of five containers, each containing a number of instances of various components scheduled in a round robin fashion. Heron uses the Nomad scheduler to translate each container into a Nomad job specification and then submit those jobs to a Nomad cluster.
Containers are submitted as separate Nomad jobs (instead of as a single Nomad job) for two reasons:
- Each container may require a different set of resources, depending on which components are placed inside.
- Heron supports dynamic scaling, which means increasing or decreasing the number of instances of a spout/bolt component independently of other components. Thus, specific containers need to be dynamically added and removed by Heron.
Submitting each container as a separate Nomad job gives Apache Heron the flexibility of scheduling.
»Using Heron on Nomad
You can use the Heron CLI to submit topologies to a Nomad cluster just as you would to any other cluster management tool or scheduler. Here’s an example command for submitting a Java topology to a Nomad cluster:
$ heron submit nomad \
~/.heron/examples/heron-api-examples.jar \
com.twitter.heron.examples.api.ExclamationTopology \
Test1
Once you have the topology running, you can check on its status using the Nomad Web UI or using the Nomad CLI (which is packaged with Heron):
$ ~/.heron/bin/heron-nomad status
Here’s some example output for the topology running in the Nomad cluster:
ID Type Priority Status Submit Date
test117cb18c9-192d-4271-8d42-4a5e62a93c89-0 service 50 running 02/26/18 19:26:06 UTC
test117cb18c9-192d-4271-8d42-4a5e62a93c89-1 service 50 running 02/26/18 19:26:06 UTC
test117cb18c9-192d-4271-8d42-4a5e62a93c89-2 service 50 running 02/26/18 19:26:06 UTC
test117cb18c9-192d-4271-8d42-4a5e62a93c89-3 service 50 running 02/26/18 19:26:06 UTC
test117cb18c9-192d-4271-8d42-4a5e62a93c89-4 service 50 running 02/26/18 19:26:06 UTC
This output shows a single running topology consisting of 5 total containers. You can also check on the status of the topology using the Heron UI. In the UI you can see that the topology is running and also examine relevant stats for the topology.
You can also kill a Heron topology running in a Nomad cluster using the Heron CLI:
$ heron kill nomad test1
In this section I’ve provided an overview of Apache Heron’s integration with Nomad. For specific details on how to deploy to an existing Nomad cluster, please see the official Heron documentation.
»Heron Standalone Cluster
As I mentioned above, we’ve introduced a new runtime mode for Apache Heron called standalone cluster mode, which we added to enable users to deploy a Heron cluster using just a few simple commands. Under the hood, a Heron standalone cluster is a Nomad cluster. Theoretically, we could’ve chosen any number of schedulers for standalone cluster mode, but we chose Nomad because it’s so lightweight and easy to use and also because users can interact with their standalone cluster using Nomad’s very good tools, such as the Nomad Web UI, to interact with their Heron cluster.
Starting up a Heron standalone cluster running on Nomad is very simple. First, set the number nodes you’d like in the cluster (you’ll be prompted to provide host information about the nodes in your cluster):
$ heron-admin standalone set
With the configuration in place, you can start the cluster:
$ heron-admin standalone cluster start
Once the cluster is up and running, you can manage topologies using the Heron CLI like normal. Here’s an example topology submission command:
$ heron submit standalone \
~/.heron/examples/heron-api-examples.jar \
com.twitter.heron.examples.api.WordCountTopology \
test1
You can tear down a running cluster like this;
$ heron-admin standalone cluster stop
For details on how to deploy a Heron standalone cluster, see the official Heron documentation.
»Future Work
As it stands, Nomad is very well supported as a scheduler for Heron, capable of backing Heron deployments of just about any size. There are, however, some features that we’d like to add in the future to improve support even further:
Support for running Heron topologies via Docker containers (Heron containers are currently process based). This will allow you to use whatever Docker-specific tooling you like in conjunction with Heron topology components. Support for dynamic scaling, either on demand or automatic.
»Conclusion
I hope to have piqued your interest in both Apache Heron and Nomad. Feel free to try out both systems for yourself. You can get started with Heron at https://apache.github.io/incubator-heron/docs/getting-started/ and Nomad at https://www.hashicorp.com/products/nomad.
If you have questions or problems, feel free to ask questions on the official Apache Heron mailing list. Please note, though, that we’ll soon be transitioning this mailing list to Apache: users@heron.incubator.apache.org







