

Update: This blog exists for historical purposes. For the most up to date information on distributed tracing in Consul service mesh (Connect), visit our distributed tracing documentation.
Earlier this month, we co-hosted a webinar with our partners at Datadog about the benefits of using a service mesh for modern networking and how to implement tracing into your environments. The purpose of this webinar was to show how to enable these features, illustrate the type of data that becomes visible, and explore how this information can be useful in mitigating potential issues. The recording of this webinar is now available in our resource library, but the purpose of this blog is to explore the concepts that were covered at a higher level as well as provide a step by step for how spans capture service request information in a microservice environment.
»Observability and Tracing
This blog is going to assume that readers are already familiar with the concept and benefits of a service mesh. If you are not familiar with this concept, we previously published a blog that explains core principles of service meshes and another that lays out the roadmap for Consul’s service mesh capabilities. Both of those should help get you familiar with the general concepts, whereas this blog is going to focus specifically on observability and tracing.
»Observability
The term observability comes from control theory, where it describes a measure of how well internal states of a system can be inferred from knowledge of external outputs. Essentially, the key purpose of observability within service meshes is to understand where your services are running, the traffic patterns of the data flowing, and the health of the connections between them. Having this information makes it easier to not only understand whether or not failures are happening in your deployments, but also give you the granularity needed to identify more subtle failures within your network, e.g. performance degradation, packet loss, memory pressure, etc. Implementing a service mesh enables users to extract Layer 7 data from applications and feed it into monitoring solutions allowing for greater visibility into problem areas and helping eliminate issues before they can become more widespread. However, having visibility into issues is just the beginning. By adding distributed tracing to services running in a service mesh, we can get even more fine grained details about connection requests, successes, retries, timeouts and failures as they move through the data plane.
»Tracing
Distributed tracing enables users to track a service’s requests as they progress through a mesh and allows developers to obtain a visualization of that flow through a number of tools. At a high level overview, this is done by adding tracers to an application or service. These tracers then collect key metadata and record timing about the operations undergone by this specific service and store it as a Span. The elements captured in a Span are:
-
tags: This field captures the instance being tracked by the tracer and contains the initial request, e.g. connecting to and requesting a value from another database instance. -
logs: the result of the connection request. -
span context: Where identifying information about the span is captured, e.g.span_idandtracer_id.
Once a Span has been created, it is then ingested and aggregated by tracing systems, like Zipkin or Jaeger, which can then output the information for APM and monitoring solutions, like Datadog or Grafana, and be observed in real time. So the next question is, how does this help me?
By implementing tracing capabilities, you enable your development teams to get much more granularity into what is causing failures. For example, let’s say Service A is failing to connect to Service B. If we only know that Service A and B are unable to communicate, we have to go step by step to see where the error is starting. In non-service mesh environments, this may not be as problematic because there might be a fewer number of connection points between the services to inspect. In a service mesh though, the increased agility and scale that we get also introduces more complexity, e.g. services residing in different regions/clouds, more services connecting at various points, etc., and as a result, searching for connection errors manually can impair those benefits. If we have added tracing to the system though, we can visually see the flow of our services and identify exactly where Service A stopped talking to Service B making it easier to fix the error. Let’s now look at an example of how to configure an environment with tracing and leverage an APM to inspect errors.
»How it works
The way that tracing allows you to see a hierarchical graph of service to service calls and internal functions inside applications is due to the hereditary nature of spans. Every span has a unique id and every span also carries the id of its parent (except root spans which have no parent). Consider the following simple architecture, you have an Ingress router which directs traffic to a HTTP Web service, the Web service then calls a gRPC based API service. All of this is operating inside of a service mesh so other than the public traffic into the ingress, all other network traffic flows through the data planes for the Service Mesh.
When tracing is enabled in this environment spans would be generated as follows:
-
The ingress service receives a new request, it generates a root span and makes a call to the Web service through the Envoy proxy including specific HTTP headers relating to the
span_id. -
The Envoy proxy for the Web service receives the request and creates a span containing the
parent_iddecoded from the HTTP headers, which is the rootspan_id. It then forwards the request to the web service.

-
The Web service handles the request and creates its own span, again using the parent information in the HTTP headers. It then calls the upstream API service via Envoy. Because the upstream API service uses gRPC rather than HTTP it can not use HTTP headers. Instead the parent span information is encoded into the gRPC metadata.
-
The Envoy proxy for the Web service receives the outbound request and creates a span, since this is a gRPC request it understands that the information regarding the
parent_idis encoded into the metadata. It forwards the request again including the parent span information into the request metadata.

-
The Envoy proxy for the API receives the request, creates a span using the gRPC metadata to obtain the parent span id and forwards the request to the local service.
-
The API service receives the request, creates a span using the gRPC metadata, performs the necessary work and returns.
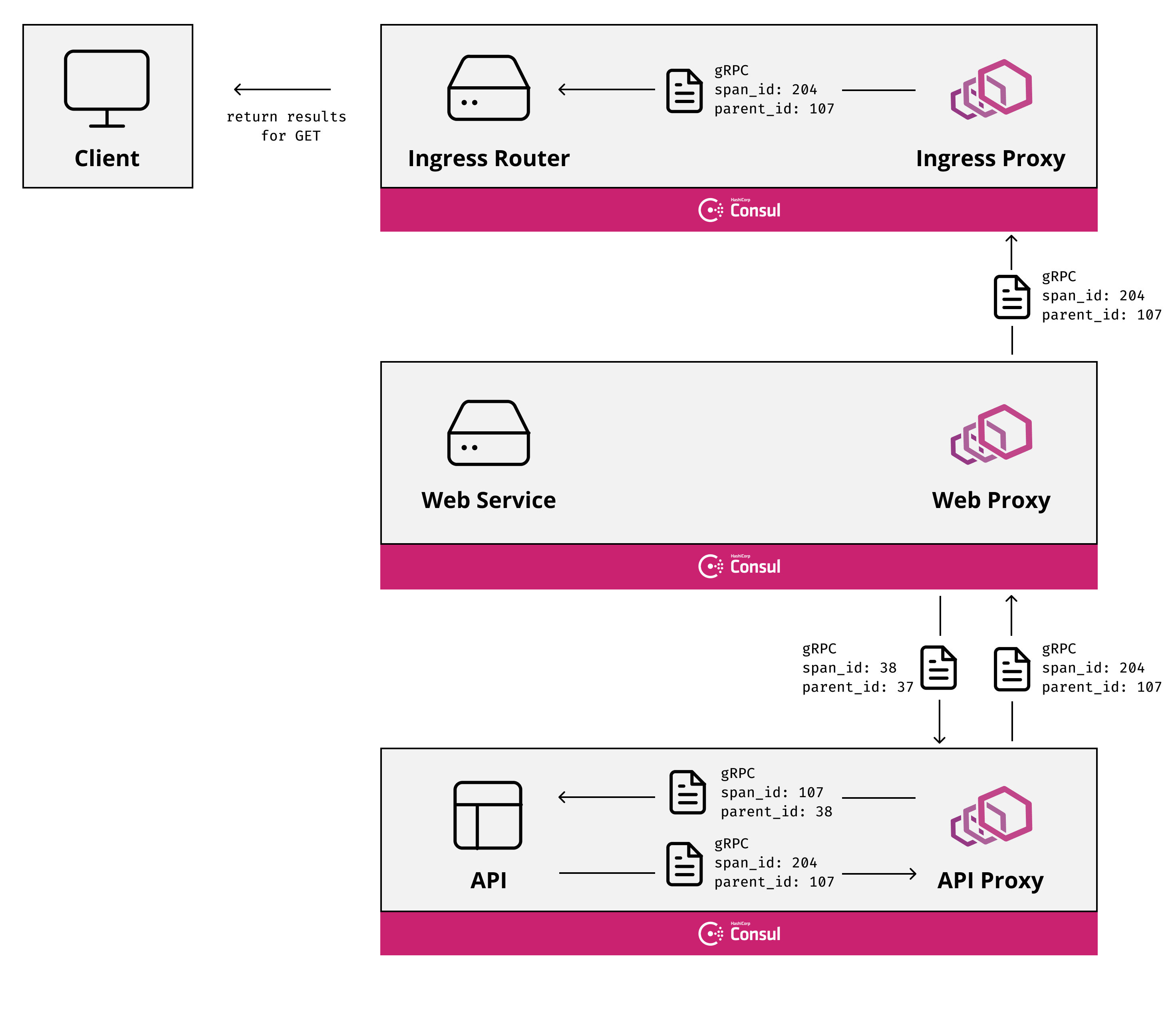
All of the spans are independently transmitted to the tracing system as the work they are monitoring completes. Since each span contains the id of the originating request the tracing system can then reassemble this data into a trace. If at any point in the request chain a span does not include the parent_id then the trace will be broken at this point as a span without a parent_id is regarded as a root span by the tracing software.
»Conclusion
When configured correctly, tracing is an incredibly powerful capability that Consul service mesh enables. As mentioned earlier though, just adding tracers to applications will not give you the insights and information desired. The key is to ensure that each tracer has the correct parent_id which allows tracing systems to follow the hierarchy and create a visual output of the path. If the spans aren’t connected in this manner, the tracing system will not be able to show the full end to end journey of the request and the data will look fragmented. If you want to see a demo of tracing in action, be sure to watch our recent webinar with Datadog or if you would prefer to try it for yourself, we have a demo of using distributed tracing with Datadog and Jaeger here. We chose to use Datadog and Jaeger for this demo because of the rich feature sets that they offer, but we know that not every environment is the same and yours may be utilizing different technologies. Consul service mesh supports most major tracing systems including Open Tracing, Honeycomb, Zipkin, and others.
For more information about HashiCorp Consul, please visit our product page






