

Thanks to Andre Newman, Senior Reliability Specialist at Gremlin, for his assistance creating this blog post.
Chaos engineering is a modern, innovative approach to verifying your application's resilience. This post shows how to apply chaos engineering concepts to HashiCorp Vault using Gremlin and Vault stress testing tools to simulate disruptive events. You’ll learn how to collect performance benchmarking results and monitor key metrics. And you’ll see Vault operators can use the results of the tests to iteratively improve resilience and performance in Vault architectures. Running these tests will help you identify reliability risks with Vault before they can bring down your critical apps.
»What is HashiCorp Vault
HashiCorp Vault is an identity-based secrets and encryption management system. A secret is anything that you want to tightly control access to, such as API encryption keys, passwords, and certificates. Vault has a deep and broad ecosystem with more than 100 partners and integrations, and it is used by 70% of the top 20 US banks.
»Chaos engineering and Vault
Because Vault stores and handles secrets for mission-critical applications, it is a primary target for threat actors. Vault is also a foundational system that keeps your applications running. Once you’ve migrated the application secrets into Vault, if all Vault instances go down, the applications receiving secrets from Vault won’t be able to run. Any compromise or unavailability of Vault could result in significant damage to an organization’s operations, reputation, and finances. Organizations need to plan for and mitigate several possible types of Vault failures, including:
- Code and configuration changes that affect application performance
- Lost the leader node
- Vault cluster lost quorum
- The primary cluster is unavailable
- High load on Vault clusters
To mitigate these risks, teams need a more modern approach to testing and validating Vault’s resilience. This is where chaos engineering comes in. Chaos engineering aims to help improve systems by identifying hidden problems and reliability risks. This is done by injecting faults — such as high CPU usage or network latency — into systems, observing how the system responds, and then using that information to improve the system. This post illustrates this by creating and running chaos experiments using Gremlin, a chaos engineering platform.
Chaos engineering brings multiple benefits, including:
- Improving system performance and resilience
- Exposing blind spots using monitoring, observability, and alerts
- Proactively validating the resilience of the system in the event of failure
- Learning how systems handle different failures
- Preparing and educating the engineering team for actual failures
- Improving architecture design to handle failures
»HashiCorp Vault architecture
Vault supports a multi-server mode for high availability. This mode protects against outages by running multiple Vault servers. High availability (HA) mode is automatically enabled when using a data store that supports it.
When running in HA mode, Vault servers have two states: standby and active. For multiple Vault servers sharing a storage backend, only a single instance is active at any time. All standby instances are placed in hot standbys. Only the active server processes all requests; the standby server redirects all requests to an active Vault server. Meanwhile, if the active server is sealed, fails, or loses network connectivity, then one of the standby Vault servers becomes the active instance. Vault service can continue to operate, provided that a quorum of available servers remains online. Read more about performance standby nodes in our documentation.
»What is chaos engineering?
Chaos engineering is the practice of finding reliability risks in systems by deliberately injecting faults into those systems. It helps engineers and operators proactively find shortcomings in their systems, services, and architecture before an outage hits. With the knowledge gained from chaos testing, teams can address shortcomings, verify resilience, and create a better customer experience. For most teams, chaos engineering leads to increased availability, lower mean time to resolution (MTTR), lower mean time to detection (MTTD), fewer bugs shipped to the product, and fewer outages. Teams who often run chaos engineering experiments are also more likely to surpass 99.9% availability.
Despite the name, the goal of injecting faults isn't to create chaos but to reduce chaos by surfacing, identifying, and fixing problems. Chaos engineering also is not random or uncontrolled testing. It’s a methodical approach that involves planning and forethought. That means when injecting faults, you need to plan out experiments beforehand and ensure there is a way to halt experiments, whether manually or by using health checks to check the state of systems during an experiment.
Chaos engineering is not an alternative to unit tests, integration tests, or performance benchmarking. It works complementary to them, and even in parallel. For example: running chaos engineering tests and performance tests simultaneously can help find problems that occur only under load. This increases the likelihood of finding reliability issues that might surface in production or during high-traffic events.
»The 5 stages of chaos engineering
A chaos engineering experiment follows five main steps:
- Create a hypothesis
- Define and measure your system’s steady state
- Create and run a chaos experiment
- Observe your system’s response to the experiment
- Use your observations to improve the system
»1. Create a hypothesis
A hypothesis is an educated guess about how your system will behave under certain conditions. How do you expect your system to respond to a type of failure? For example, if Vault loses the leader node in a three-node cluster, Vault should continue responding to requests, and another node should be elected as the leader. When forming a hypothesis, start small: focus on one specific part of your system. This makes it easier to test that specific system without impacting other systems.
»2. Measure your steady state
A system’s steady state is its performance and behavior under normal conditions. Determine the metrics that best indicate your system’s reliability and monitor those under conditions that your team considers normal. This is the baseline that you’ll compare your experiment's results against. Examples of steady-state metrics include Vault.core.handle_login_request and vault.core.handle_request. See our well architected framework for more key metrics.
»3. Create and run a chaos experiment
This is where you define the parameters of your experiment. How will you test your hypothesis? For example, when testing a Vault application’s response time, you could use a latency experiment to create a slow connection.
This is also where you define abort conditions, which are conditions that indicate you should stop the experiment. For example, if the Vault application latency rises above the experimental threshold values, you should immediately stop the experiment so you can address those unexpected results. Note that an abort doesn’t mean the experiment failed; it just means you discovered a different reliability risk than the one you were testing for.
Once you have your experiment and abort conditions defined, you can build the experimentation systems using Gremlin.
»4. Observe the impact
While the experiment is running, monitor your application’s key metrics. See how they compare to your steady state, and interpret what they mean for the test. For example, if running a blackhole on your Vault cluster causes CPU usage to increase rapidly, you might have an overly aggressive response time on API requests. Or, the web app might start delivering HTTP 500 errors to users instead of user-friendly error messages. In both cases, there’s an undesirable outcome that you need to address.
»5. Iterate and improve
Once you’ve reviewed the outcomes and compared the metrics, fix the problem. Make any necessary changes to your application or system, deploy the changes, and then validate that your changes fix the problem by repeating this process. This is how you iteratively make your system more resilient; a better approach than trying to make sweeping, application-wide fixes all at once.
»Implementation
The next section runs through four experiments to test a Vault cluster. Before you can run these experiments, you’ll need the following.
Prerequisites:
- A Vault HA cluster
- A Gremlin account (Sign up for free for 30-days.)
- The Vault benchmarking tool
- Organizational awareness (let others know you’re running experiments on this cluster)
- Basic monitoring
»Experiment 1: Impact of losing a leader node
In the first experiment, you’ll test whether Vault can continue responding to requests if a leader node becomes unavailable. If the active server is sealed, fails, or loses network connectivity, one of the standby Vault servers becomes the active instance. You’ll use a blackhole experiment to drop network traffic to and from the leader node and then monitor the cluster.
»Hypothesis:
If Vault loses the leader node in a three-node cluster, Vault should continue responding to requests, and another node should be elected to leader.
»Get a steady state from the monitoring tool
Our steady state is based on three metrics:
- The sum of all requests handled by Vault
-
vault.core.handle_login_request -
vault.core.handle_request
Below graphs shows the sum of requests oscillates around 20K, while handle_login_request and handle_request hover between metrics 1 and 3.

»Run the experiment:
This experiment runs a blackhole experiment for 300 seconds (5 minutes) on a leader node. Blackhole experiments block network traffic from a host and are great for simulating any number of network failures, including misconfigured firewalls, network hardware failures, etc. Setting it for 5 minutes gives us enough time to measure the impact and observe any response from Vault.
Here, you can see the ongoing status of the experiment in Gremlin:
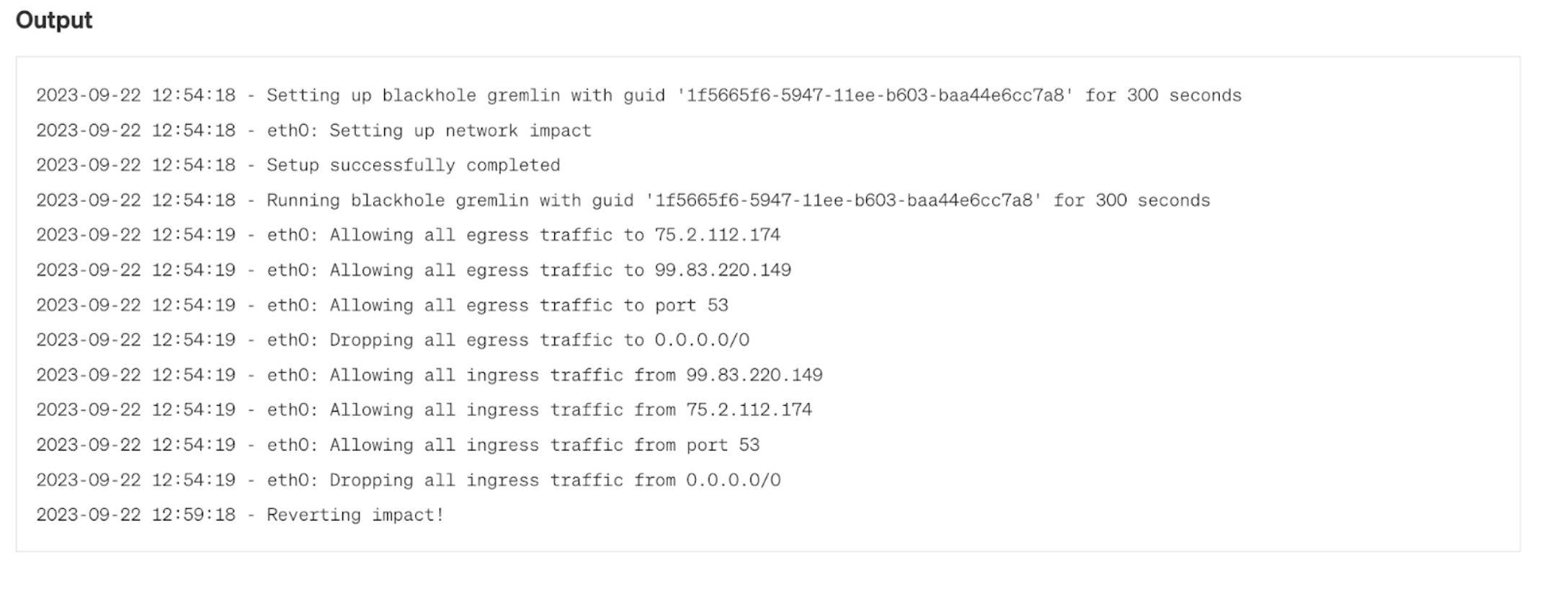
»Observe
This experiment uses Datadog for metrics. The graphs below show that Vault is responding to requests with a negligible impact on throughput. This means Vault’s standby node kicked in and was elected as the new leader.

You can confirm this by checking the nodes in your cluster using Vault operator raft command:

»Improve cluster design for resilience
Based on these results, no immediate changes are needed, but there’s an opportunity to scale up this test. What happens if two nodes fail? Or all three? If this is a genuine concern for your team, try repeating this experiment and selecting additional nodes. You might try scaling up your cluster to four nodes instead of three — how does this change your results? Keep in mind that Gremlin provides a Halt button for stopping an ongoing experiment ife something unexpected happens. Remember your abort conditions, and don’t be afraid to stop an experiment if those conditions are met.
»Experiment 2: Impact of losing quorum
The next experiment tests whether Vault can continue responding to requests if there is no quorum, using a blackhole experiment to bring two nodes offline. In such a scenario, Vault is unable to add or remove a node or commit additional log entries, resulting in unavailability. This HashiCorp runbook documents the steps needed to bring the cluster back online, which this experiment tests.
»Hypothesis
If Vault loses the quorum, Vault should stop responding to requests. Following our runbook should bring the cluster back online in a reasonable amount of time.
»Get a steady state from Vault
The steady state for this experiment is simple: Does Vault respond to requests? We’ll test this by retrieving a key:

»Run the experiment
Run another blackhole experiment in Gremlin, this time targeting two nodes in the cluster.
»Observe
Now that the nodes are down, the Vault cluster has lost the quorum. Without a quorum, read and write operations cannot be performed within the cluster. Retrieving the same key returns an error this time:
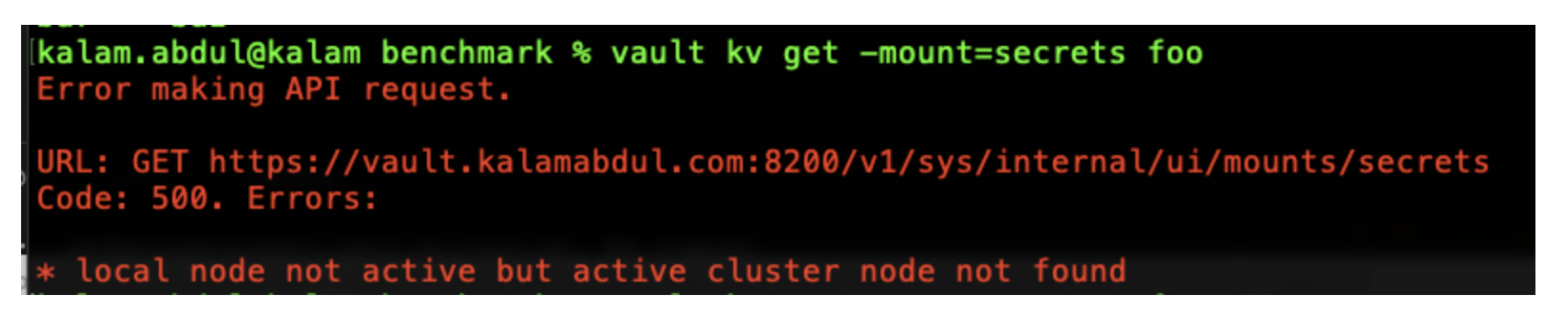
»Recovery drill and improvements
Follow the HashiCorp runbook to recover from the loss of two of the three Vault nodes by converting it into a single-node cluster. It takes a few minutes to bring the cluster online, but it works as a temporary measure.
A long-term fix might be to adopt a multi-datacenter deployment where you can replicate data across multiple datacenters for performance as well as disaster recovery (DR). HashiCorp recommends using DR clusters to avoid outages and meet service level agreements (SLAs).
»Experiment 3: Testing how Vault handles latency
This next experiment tests Vault’s ability to handle high-latency, low-throughput network connections. You test this by adding latency to your leader node, then observing request metrics to see how Vault’s functionality is impacted.
»Hypothesis
Introducing latency on your cluster’s leader node shouldn’t cause any application timeouts or cluster failures.
»Get KPIs from monitoring the tool
This experiment uses the same Datadog metrics as the first experiment: vault.core.handle_login request, and vault.core.handle_request.

»Run the experiment
This time, use Gremlin to add latency. Instead of running a single experiment, create a Scenario, which lets you run multiple experiments sequentially. Gradually increase latency from 100ms to 200ms over 4 minutes, with 5-second breaks in between experiments. (This Gremlin blog post explains how a latency attack works.)
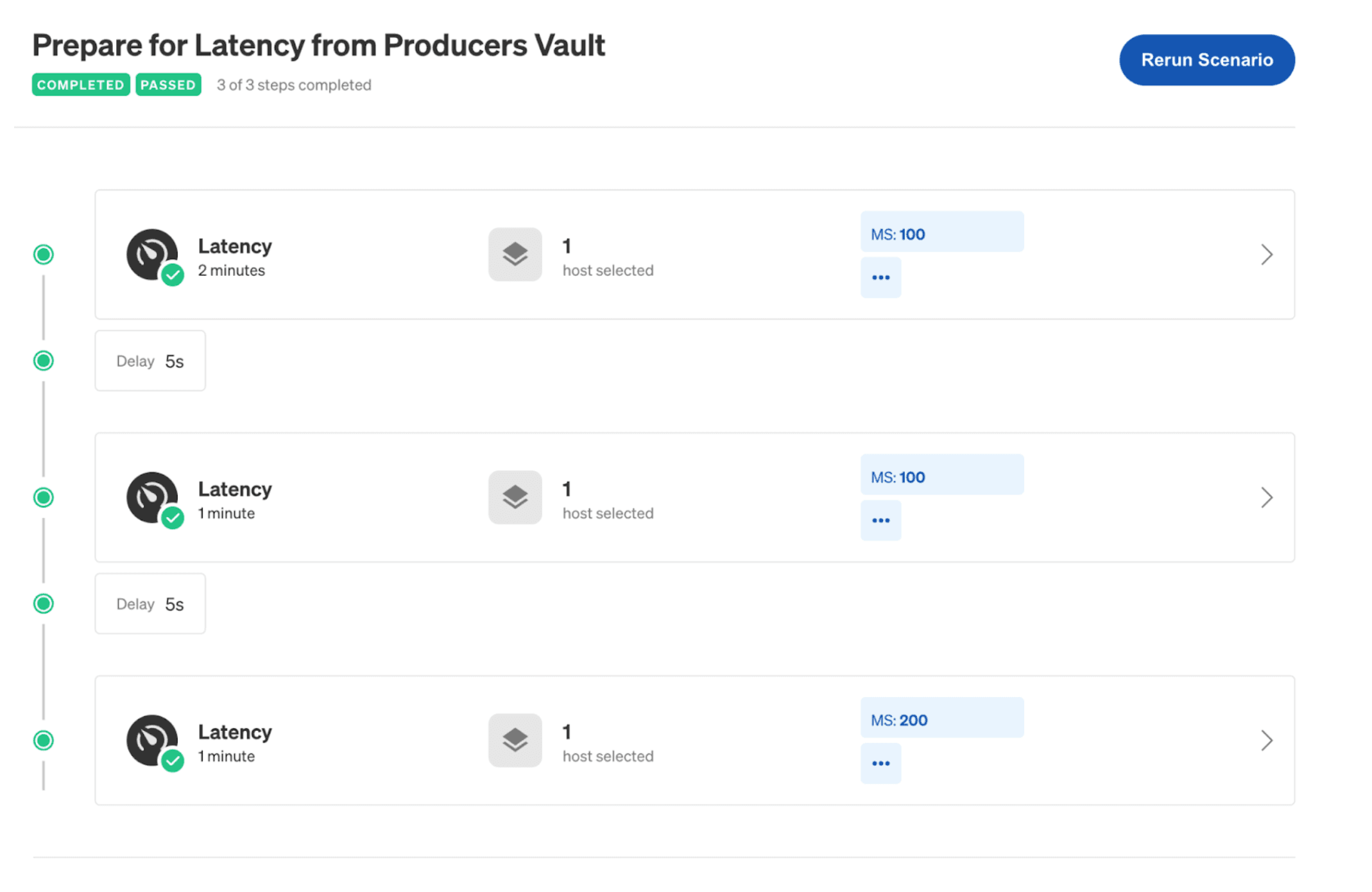
»Observe
In our test, the experiment introduced some delays in response time, especially in the 95th and 99th percentiles, but all requests were successful. More importantly, our cluster is stable from key metrics below:

»Improve cluster design for resilience
To make the cluster even more resilient, add non-voter nodes to the cluster. A non-voting node has all of Vault's data replicated but does not contribute to the quorum count. This can be used with performance standby nodes to add read scalability to a cluster in cases where a high volume of reads to servers is needed. This way, if one or two nodes have poor performance, or if a large volume of reads saturates a node, these standby nodes can kick in and maintain performance.
»Experiment 4: Testing how Vault handles memory pressure
This final experiment tests Vault’s ability to handle reads during high memory pressure.
»Hypothesis
If you consume memory on a Vault cluster’s leader node, applications should switch to reading from performance standby nodes. This should have no impact on performance.
»Get metrics from monitoring tool
For this experiment, graphs below gather telemetry metrics directly from Vault nodes; specifically, memory allocated to and used by Vault.

»Run the experiment
Run a memory experiment to consume 99% of Vault’s memory for 5 minutes. This pushes memory usage on the leader node to its limit and holds it there until the experiment ends (or you abort).
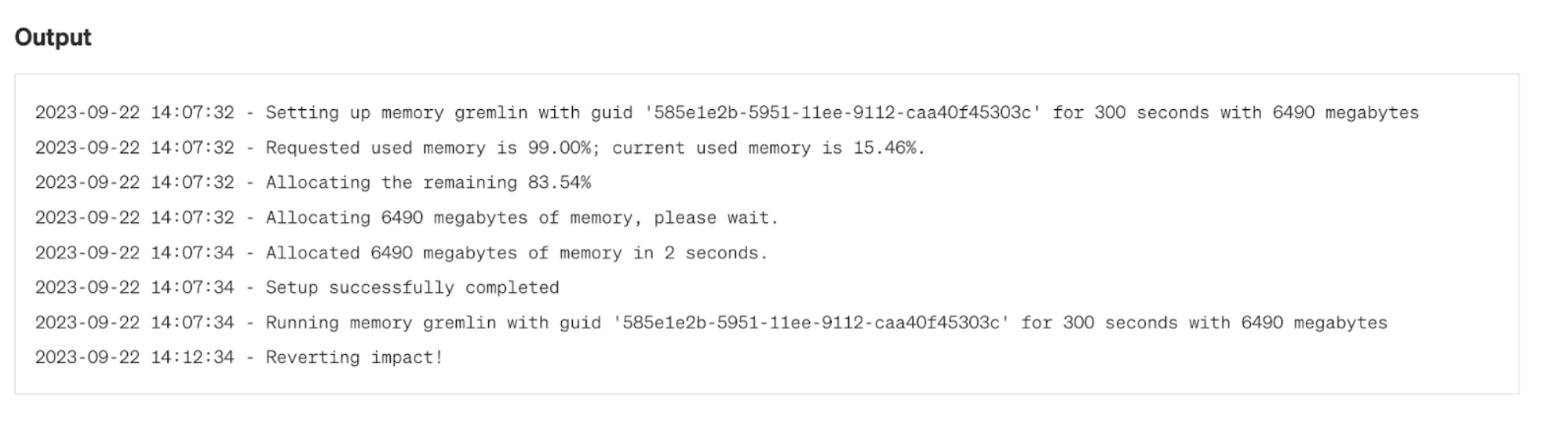
»Observe
In this example, the leader node kept running, and while there were minor delays in response time, all requests were successful as seen in the graph below. This means our cluster can tolerate high memory usage well.

»Improve cluster design for resilience
As in the previous experiment, you can use non-voter nodes and performance standby nodes to add compute capacity to your cluster if needed. These nodes add extra memory but don’t contribute to the quorum count. If your cluster runs low on memory, you can add these nodes until usage drops again.
Other experiments that might be beneficial include DDOS attacks, cluster failover, and others.
»How to build chaos engineering culture
Teams typically think of reliability in terms of technology and systems. In reality, reliability starts with people. Getting application developers, site reliability engineers (SREs), incident responders, and other team members to think proactively about reliability is how you start building a culture of reliability.
In a culture of reliability, each member of the organization works toward maximizing the availability of their services, processes, and people. Team members focus on improving the availability of their services, reducing the risk of outages, and responding to incidents as quickly as possible to reduce downtime. Reliability culture ultimately focuses on a single goal: providing the best possible customer experience. In practice, building a reliability culture requires several steps, including:
- Introducing the concept of chaos engineering to other teams
- Showing the value of chaos engineering to your team (you can use the results of these experiments as prooft)
- Encouraging teams to focus on reliability early in the software development lifecycle, not just at the end
- Building a team culture that encourages experimentation and learning, not assigning blame for incidents
- Adopting the right tools and practices to support chaos engineering
- Using chaos engineering to regularly test systems and processes, automate experiments, and run organized team reliability events (often called “Game Days”)
To learn more about adopting chaos engineering practices, read Gremlin’s guide: How to train your engineers in chaos engineering or this S&P Global case study.
»Learn more
One of the biggest challenges in adopting a culture of reliability is maintaining the practice. Reliability isn’t can’t be achieved in a single action: it has to be maintained and validated regularly, and reliability tools need to both enable and support this practice. Chaos engineering is a key component of that. Run experiments on HashiCorp Vault clusters, automate reliability testing, and keep operators aware of the reliability risks in their systems.
Want to see how Indeed.com manages Vault reliability testing? Watch our video All the 9s: Keeping Vault resilient and reliable from HashiConf 2023. If you use HashiCorp Consul, check out our tutorial and interactive lab on Consul and chaos engineering.




