

Both Kubernetes and HashiCorp Nomad are mature orchestrators used for managing the lifecycle of containerized applications. Teams and organizations choose Nomad for its core strengths of simplicity and flexibility. For users coming from a Kubernetes background, this blog series may help you find the equivalent terminology and understand the basics of Nomad.
Be sure to check out our Kubernetes to Nomad Cheat Sheet and Kubernetes User's Guide to Nomad Secret Management as well.
»What Kubernetes and Nomad Have in Common
Both tools support similar core use cases that help enterprises get their containerized applications up and running. The common feature set includes:
- Automated scheduling
- Self-recovery or self-healing of the applications
- Rollout and rollback strategy
- Storage orchestration
»How Kubernetes and Nomad Differ
Kubernetes aims to build a powerful platform with all the features included. It is designed to work as a collection of several interoperating components which together provide the full functionality. By contrast, Nomad was designed to focus solely on cluster management and scheduling. It intentionally leaves out non-core features so that it can run as a single process with zero external dependencies. It integrates with other tools like Consul for networking and Vault for secret management.
Another key difference is that Nomad is more general purpose. It supports virtualized, containerized, and standalone applications, such as Docker, Java, IIS on Windows, QEMU, application binary/executable, etc. You can look at the differences in greater detail here.

»Architecture
Both Nomad and Kubernetes follow a Client-Server architecture. In Kubernetes, they are called “Control Plane” and “ Node”. In Nomad, they are called “Server” and “Client”. A “Region” in Nomad describes a set of Server Nodes and Client Nodes operating together to orchestrate applications. It is similar to a Kubernetes “Cluster”, and these two terms are often used interchangeably.
Kubernetes requires a number of different processes to be installed on the control plane and nodes: the control plane consists of etcd, kube-apiserver, kube-scheduler, and kube-controller-manager, while the nodes run kubelet and kube-proxy. Nomad, however, is a single binary, which can be configured as either a server or client agent.
»Client Node
Nomad’s client nodes require a single process to be installed.

- Client agent: An agent that fingerprints the node and provides information to the Nomad servers for scheduling. It makes sure that the task is running and manages its lifecycle. It is similar to Kubelet.
- Task driver [Optional]: Task drivers are the runtime components. The Nomad Client agent provides built-in drivers such as Docker, Java, exec, QEMU, etc. Additionally, the task driver system is pluggable so that users can use any community plugin or create their own. In that case, the additional drivers need to be installed on the client node.
»Server Node
A Nomad server node requires a single process.

- Nomad server agent: The server agent maintains the cluster state and performs the scheduling. It combines multiple functions into one lightweight process
- API: Nomad supports two API protocols: an RPC API used mainly for internal server-server and server-client communication and an HTTP API used by the UI, CLI, and most external tooling.
- Controllers: Server agents are internally responsible for most of the work associated with managing a Region. For external controllers such as the Nomad Autoscaler, instead of running special services in the control plane, they are built as Nomad “Jobs” running alongside users’ applications on the Client nodes.
- Cluster data: Instead of relying on an external state store like etcd, each Nomad server agent internally implements the Raft algorithm to maintain the cluster state.
»Production Deployment
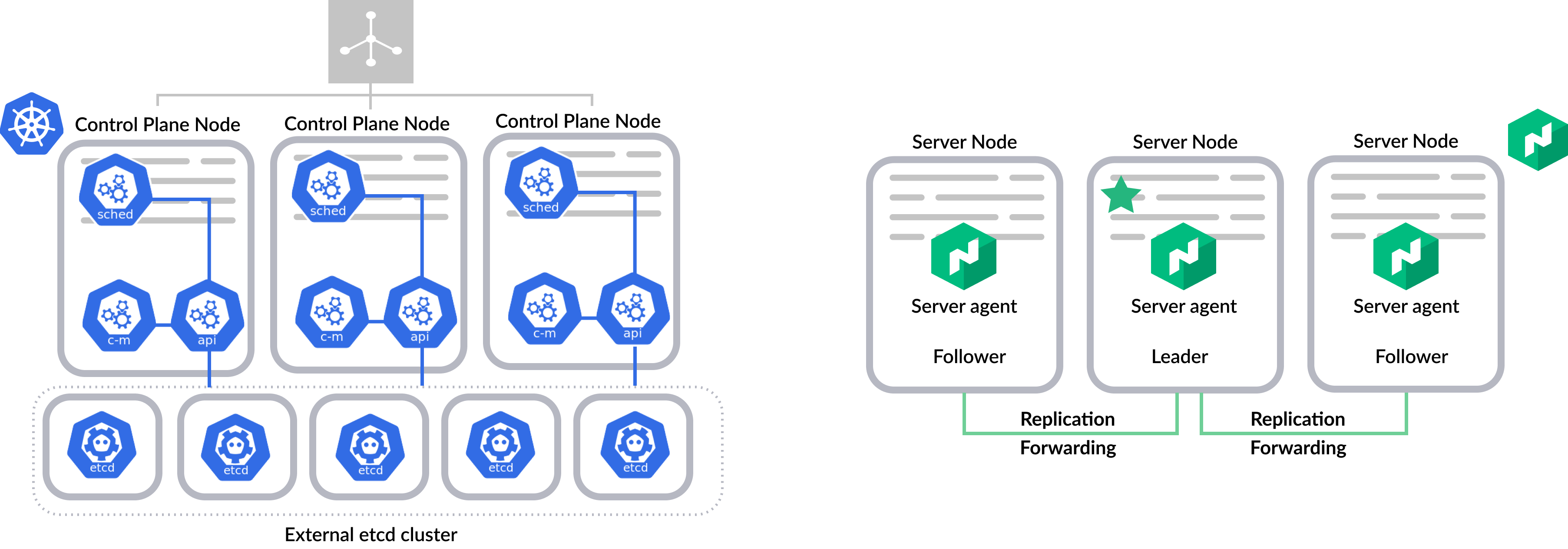
For a production environment, it is critical to ensure that the control plane is highly available. For Kubernetes, users run multiple instances of the control plane behind a load balancer. Decoupling etcd from the rest of the control plane components is recommended.
For Nomad, the server nodes are highly available by design. We recommend running 3 or 5 server nodes per region. All servers perform some management work, such as making scheduling decisions in parallel. Servers in a region are part of a consensus group and work together autonomously to elect a single leader which has extra duties. The leader provides cluster-level coordination, manages cluster status changes, and replicates the cluster state to the followers. If the leader fails, one of the followers is automatically elected to leader without the need for operator intervention.
»Core Concepts
»Job, Task, Task Group, and Allocation

In Kubernetes, Pods are the smallest deployable units. A Pod can contain one or more containers with shared storage and network resources. The resource for deploying pods — Deployment — is the most commonly used resource. The specification for a deployment features a pod spec and the desired number of replicas of the pod.
In Nomad, users define how applications should be deployed with a declarative specification: the Nomad Job. A job represents a desired application state defined in JSON or HCL format. In a Nomad job, Tasks are the smallest units of deployment. A task could be a Docker container, a Java application, or a batch processing job. It is similar to an individual container in a Pod.
A Task Group defines a set of tasks that must be run on the same client node. Tasks in the same group can be configured to share network and storage resources. Each group has a count parameter to indicate the desired number of instances. It is similar to how users specify pods and the number of pod replicas in ReplicaSet or via Deployment.
An Allocation is an instantiation of a task group running on a client node. If there need to be 3 instances of a task group specified in the job, Nomad will create 3 allocations and place those accordingly. An allocation is similar to a pod once the pod is scheduled on a worker node.
In short, a Nomad job is composed of one or multiple different task groups, and a task group is composed of one or more tasks. Once the job is submitted to a Nomad server, each task group will have a certain number of allocations to be created based on the number of instances required.
job "example" {
region = "us"
datacenters = ["us-west-1", "us-east-1"]
type = "service" # Run this job as a "service" type
constraint {
attribute = "${attr.kernel.name}"
value = "linux"
}
group "cache" {
count = 3 # number of instances
task "redis" {
driver = "docker"
config {
image = "redis:6.0"
}
resources {
cpu = 500 # 500 MHz
memory = 256 # 256MB
}
}
}
}
Kubernetes provides multiple ways of creating pods depending on the nature of the application: Deployment, ReplicaSet, DaemonSet, Job, CronJob, and so on. In Nomad, a single job spec allows users to define how various applications should be running. Through parameters like type, periodic, and parameterized, Nomad jobs allow users to specify the application type and desired scheduling paradigms. Nomad servers will invoke the appropriate scheduler to deploy applications.
»Networking
Nomad and Kubernetes differ a lot in networking. In a Kubernetes cluster, there are normally three IP networks:
- Node network: The physical network that your nodes are connected to
- Pod network: In Kubernetes, each pod gets its own unique IP. The pod network is separate from the node network and many users choose to implement an overlay network to route traffic between pods and nodes.
- Service network: A service is a Kuberentes resource that represents a group of pods, with a permanent IP address. The service network is a system of virtual IPs that are generally separate from Pod and Node networks.

Because of these separate networks, external applications cannot directly communicate with applications within a Kuberentes cluster. Most users choose to deploy an ingress controller — a pod running reverse proxy like Nginx — and expose it as the single entry point to a Kubernetes cluster.
Nomad’s default network is the Node network. Each task group instance uses the Node IP network and gets its own port through dynamic port assignment. Since there is no Virtual IP or an additional overlay network required, the Nomad cluster network can be part of an existing enterprise network.
»Networking with Consul
In Kubernetes, the Service and Kube-proxy are responsible for tracking the pods and routing the traffic to them. In Nomad, this function can be done by another HashiCorp product, Consul.
Consul is a widely-deployed networking tool that provides a fully featured service mesh and service discovery. It allows application instances to easily register themselves in a central catalog. When applications need to communicate with each other, the central catalog can be queried using either an API or DNS interface to provide the required network location.
Consul and Nomad have a lot of similarities in architecture. Consul Client agents register the application instance and are responsible for health checking, while Consul Server agents collect the information shared by the agents and keep the central catalog up-to-date.
Through native integration, users can specify the job file to automatically register task groups with Consul. A task group can define one or more services identified by a unique name. When each allocation is started, Nomad registers the IP address and port for the defined services with Consul.

»Load Balancing and Ingress
One approach to load balancing is to use Consul's built-in load balancing functionality. Consul integrates health checks with service discovery. By default, unhealthy application instances are never returned from queries to the service discovery layer. In this mode, applications running on Nomad can talk directly to Consul each time they want to find other applications. It will receive a randomized response containing a list of network locations that correspond to healthy application instances in the cluster. The DNS interface offers essentially zero-touch service discovery integration into any application.
In addition to discovering applications through Consul DNS, users may choose to deploy load balancers. Nomad and Consul integrate with NGINX, HAProxy, Envoy, Traefik, and other popular reverse proxies. Nomad Jobs support a templates stanza to populate dynamic values from environment variables, service and key-value data from Consul, or secret data from HashiCorp Vault into configuration files. In this load balancer deployment scenario, users can set up Nomad to handle several things:
- Automating the deployment and scaling of load balancers
- Leveraging the built-in templating support to dynamically update backend configuration files as applications scale up and down
- Specifying auto-reloading of the load balancers in Nomad jobs when the configuration files change
One of the main use cases of a load balancer is to distribute incoming traffic from the internet to frontend applications running on Nomad that can handle those requests. This provides functionality similar to an ingress controller in Kubernetes.
»Next Steps
We hope you find these comparisons of core concepts useful. In the later posts of this series, we will look at the typical security and cryptography workflows, basic operation and troubleshooting, and more. Let us know if you are looking for a particular topic here.
To get started with Nomad, visit the HashiCorp Learn platform to get step-by-step instructions.
»Video
You can also watch this demo presentation comparing Kubernetes and Nomad terminology.
The speaker, Iris Carrera, is a Site Reliability Engineer on the Cloud Services team at HashiCorp. Over the past five years she has worked on cloud infrastructure and site reliability, where she has gained Kubernetes and Nomad operations experience in production environments. In this session, she will explain Nomad's core concepts and demo basic operations through the lens of Kubernetes.






