

As a platform engineer, you might work in an organization with several iterations of a platform for developers to deploy applications. These platforms may involve on-premises infrastructure or public cloud resources. Over time, you experience platform sprawl, spending more time maintaining the older versions of the platforms while expanding a new version. Your workflows are fragmented across your org, making cross-platform improvements, monitoring, debugging, and patching much harder.
In an effort to reduce technical debt and deliver quickly, you need to refactor your applications, infrastructure, and security to standardize on new patterns and workflows and support. Standardizing your applications, infrastructure, and security streamlines compliance and remediation at scale.
This post discusses patterns for refactoring your infrastructure provisioning and patching workflows across multiple platforms and application teams while minimizing the overall level of effort for risk discovery and remediation. Efforts to standardize your practices for lower risk and stronger compliance take time. However, implementing practices like policy as code and applying principles like immutability can streamline refactoring and encourage teams to transition to a single system of record.
»The struggle for standardization
Imagine your organization has five different platforms across a datacenter and two public clouds. Each application within a platform conforms to the platform’s automation and security approach but each platform differs in automation and change management. “Platform sprawl”, the growing number of platforms and their iterations that serve developers, become more challenging to manage over time.
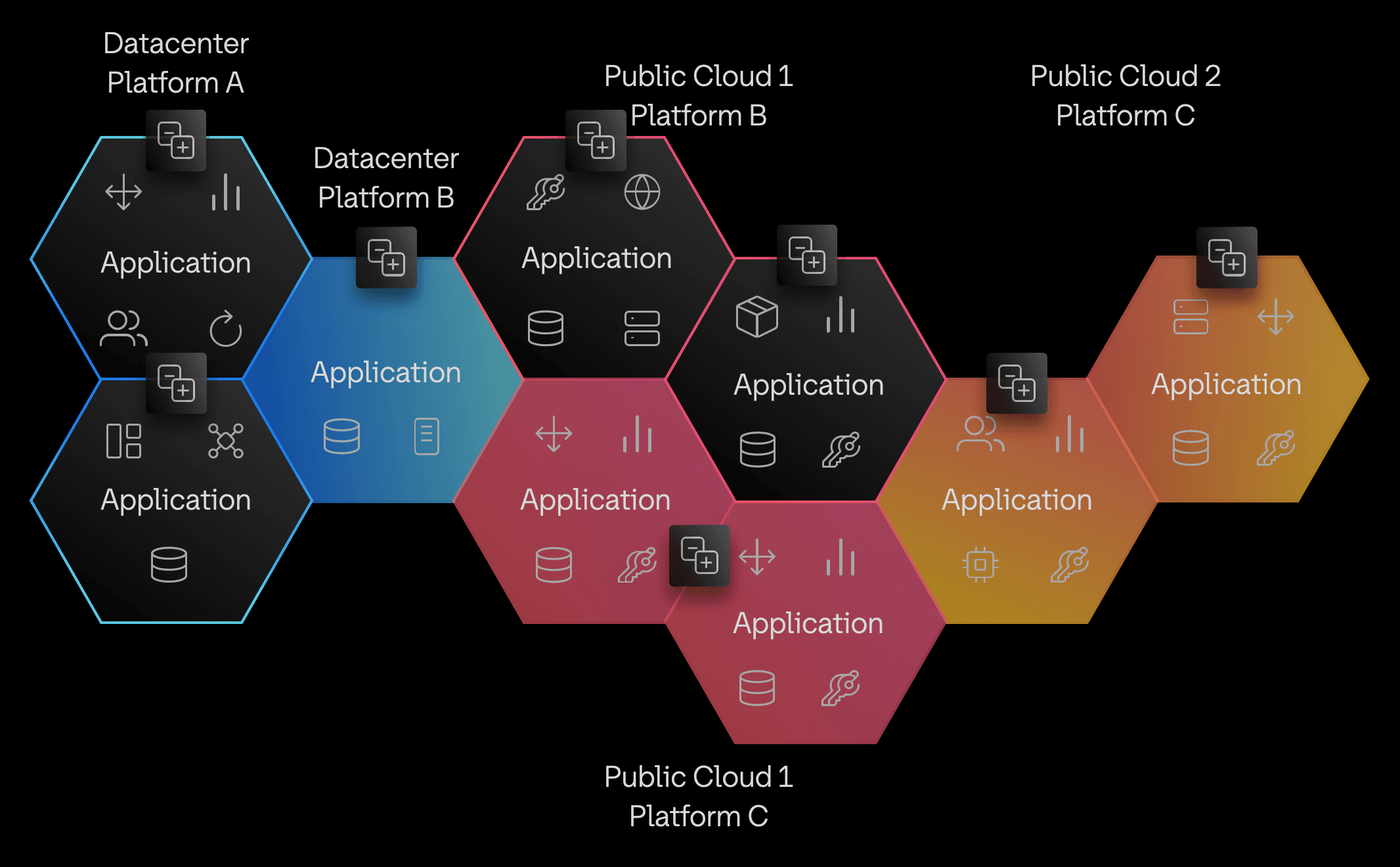
Diagram of example organization's five different platforms across a datacenter and two public clouds.
When you need to address a security issue across all platforms, you spend most of your time identifying affected platforms and remediating the issue based on individual platform automation. For example, you may have separate processes to upgrade a Kubernetes cluster running on-premises with OpenShift versus managed clusters in public clouds. Without a consistent system of record and a foundational automation system, you may find yourself remediating the same issue over and over again for months.
How can you standardize older and newer platforms? Refactoring for standardization across platforms includes three approaches:
Abstracting workflows across multiple platforms (e.g., using an internal developer portal): Requires a high level of development effort with the least disruption to existing applications.
Importing existing infrastructure onto new platforms using Terraform: Allows you to manage infrastructure as code, providing a foundation for standardization. This requires a medium to high level of development with some disruption to existing applications that depend on infrastructure configuration.
Migrating resources off older platforms to newer ones: Can have a high level of development effort with major disruption to existing applications depending on differences between platforms
Regardless of which refactoring approach you choose for standardization, practices like policy as code and principles of immutability support your refactoring efforts over time by communicating and maintaining the standards across multiple teams, platforms, and workflows.
»Policy as code
Policy for infrastructure can include rules such as “only use approved database versions” or “only use Terraform modules from our private registry”. Manually communicating, verifying, and enforcing these policies take time and effort, whereas policy as code automates, documents, and versions these rules.
Policy as code can be used to manage an entire organization’s policies related to:
Security
Compliance and auditing
Cost controls
Operational resilience
…and enforce them automatically through software delivery pipelines While policy as code applied to infrastructure varies in tools and approaches (for example, Terraform Enterprise and HCP Terraform can use OPA or their native policy as code system: Sentinel) it captures policy requirements in a codified manner so you can test infrastructure configuration for conformance.
You can write policy as code in two ways for infrastructure and security lifecycle management:
You can create a policy to check infrastructure configuration changes before applying them to production. This tends to involve static analysis or unit testing on Terraform or Packer configurations before going to production.
You can test for policy conformance on live infrastructure. This pattern involves dynamic analysis to check test or production infrastructure (like a virtual machine with a new machine image) for policy conformance.
Static analysis provides faster feedback on whether or not Terraform code conforms to organizational requirements — removing the need for ticket submissions and time-consuming manual reviews in many workflows.
Dynamic analysis offers scheduled feedback on the actual state of your production environment and checks if it conforms to organization requirements. It helps identify break-glass or automated changes that do not get merged as code, such as in emergency fixes or automated upgrades.
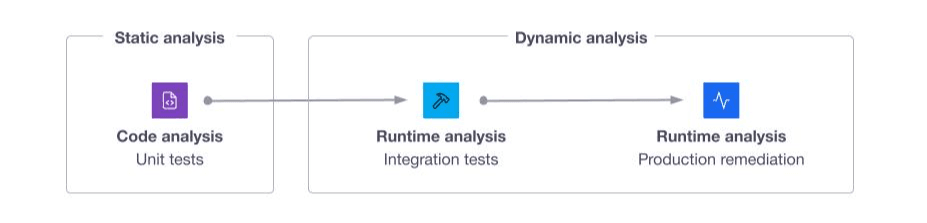
A plan for static analysis: With stakeholder help, platform teams should select a policy as code framework that integrates with, or is native to Terraform (i.e. Sentinel). They can learn how to build policy configurations for things like checking for the correct Terraform module version using publicly available policy sets as a starting point.
A plan for dynamic analysis: In your test or non-production environment, use Terraform custom conditions to check that a server uses the latest approved image version. In your production environment, detect configuration drift and continuously validate resources against Terraform code using HCP Terraform health assessments.
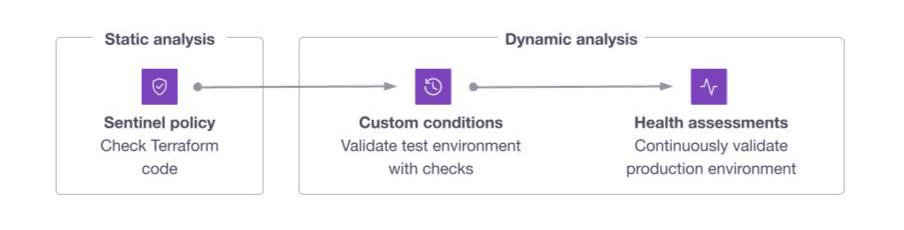
»When to use policies vs custom conditions
Note that in the case of Terraform, Sentinel or OPA policies and custom conditions may overlap in function. Here’s some general guidance for when to use each:
»Use policies
For any rules that apply to any Terraform run. For example:
Checking for valid module versions
Checking that modules from the private Terraform registry are being used
»Use custom conditions
When validating attributes against third-party services or dependencies. For example:
Comparing resource-specific tags to a CMDB
Validating attributes against HCP Packer metadata
»Using policy sets
You’ll want to organize individual policies into a policy set to allow the distribution of standard policies — built, tested, and approved by technical leadership and policy stakeholders — across multiple teams in your organization. A policy set offers two benefits:
The policy definitions are centralized in one place. For example, all AWS and Azure policy sets are organized in version control, simplifying updates by security and compliance teams.
They encourage modularization and composition by grouping relevant policies together. Grouping by benchmark type, compliance level, and geography allows different teams to apply the policy sets relevant to their infrastructure or application. For example, if a team needs to comply with Payment Card Industry (PCI) Security Standards, they choose a pre-built policy set with checks for PCI compliance. Another team that supports a web application running on a multi-tenant Kubernetes cluster can select a Kubernetes-specific policy set to verify their cluster has a secure configuration.
»Standardizing on policy as code: An example scenario
The diagram below illustrates an example: Imagine you want to standardize your platforms in public cloud #1. Platform C uses Terraform to deploy and manage all infrastructure and Sentinel policies to check the use of secure machine images and versions for managed services. Platform B allows developers to provision resources manually without policy checks.
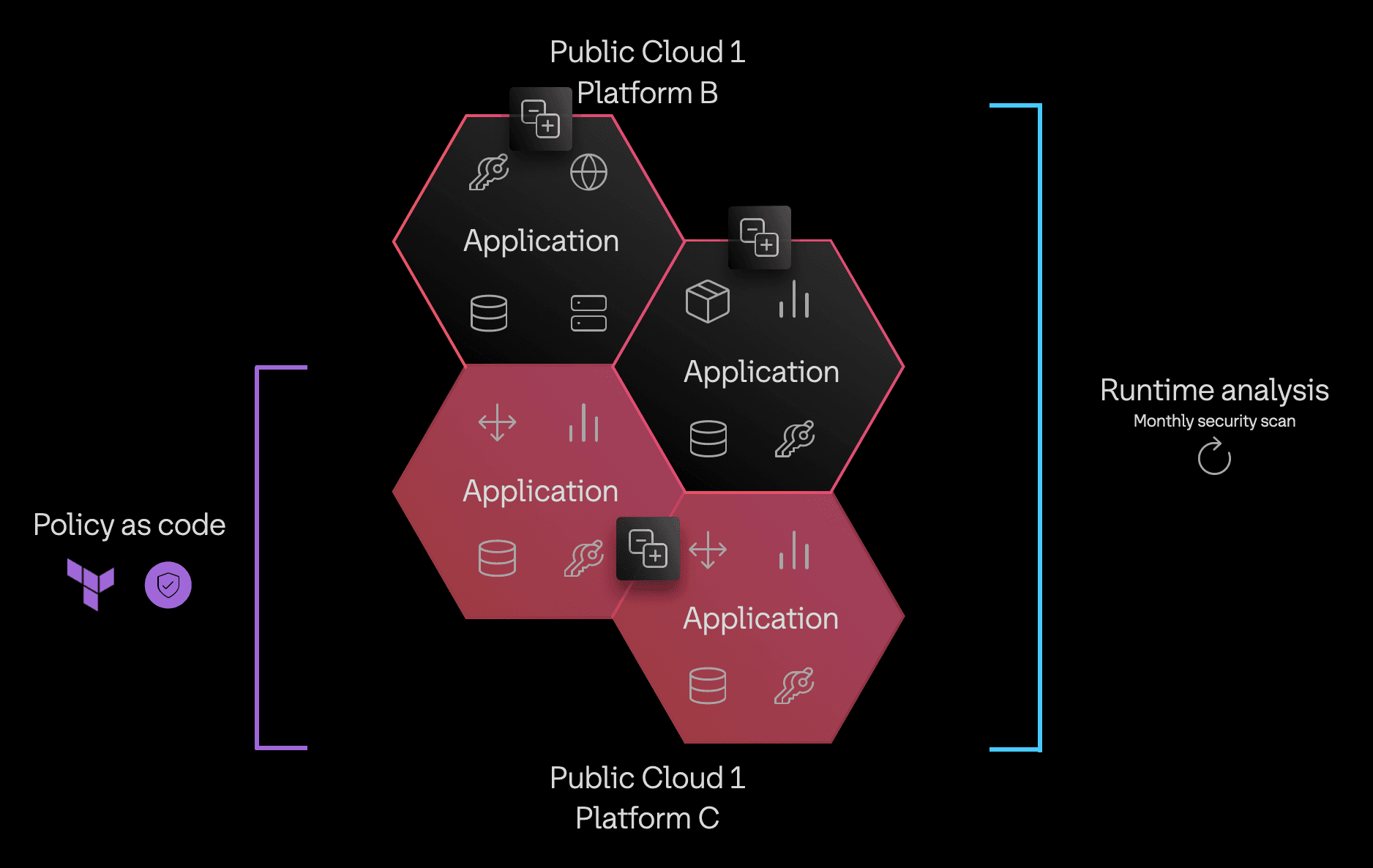
Platform C has standardized on policy as code, but Platform B has not. Regardless, each every platform in the organization has to patch issues found in the global runtime analysis.
The company doesn’t mandate either one of those two workflows, but it does require a series of security scans to run against all cloud accounts every month to identify potential vulnerabilities. After this month’s scan, Platform B has a number of security alerts to address whereas Platform C caught them all with Sentinel checks, so they don’t have any vulnerabilities to address this month.
Rather than patching a large list of security vulnerabilities every month, and running high-touch manual deployments, both developers and platform admins on Platform B want to adopt the time-saving workflows of Platform C. Platform B decides to standardize on HCP Terraform in order to adopt the more successful workflow, so they talk to the Platform C team to help streamline their transition.
After migrating their infrastructure into HCP Terraform, the Platform B team doesn’t have to write many new policies because Platform C shares their Sentinel policy sets with them. Now, each time an infrastructure change gets applied through HCP Terraform, developers on Platform B get immediate feedback on organization-wide best practices for security and compliance. They no longer have a large list of vulnerabilities to address, because they’re running mostly the same checks as Platform C. As more developers use the public cloud, Platform B and C teams can share their policy sets to help ensure infrastructure changes on more teams have a secure and compliant configuration by default.
As more teams use a single system of record for infrastructure and policy, the security and efficiency benefits multiply and reach further around the org.
Now imagine that your organization has 100% of platforms using HCP Terraform and the same core policy sets that started with Platform C. You now have a single plane for communicating and enforcing security and compliance goals for all teams across their different platforms.
Let’s say a security research organization publishes a new vulnerability that affects some of your organization’s virtual machine base images. Your teams can use HCP Packer to create a new base image without the vulnerability and revoke the old images. Next, a central platform team can update an org-wide Sentinel policy that checks for the new version of the machine image that patches the vulnerability. The next time any team across your organization runs a terraform apply, they receive a notification that they need to fix their server. The Sentinel policy effectively communicates the security goal of a secure machine image across all platforms and teams.
»Immutability
Continuing with the image vulnerability patch management (VPM) scenario — when each team fails the Sentinel policy for a secure machine image, they need to implement a fix. They update their Terraform modules and configurations to use the updated machine image. Since the team at your org automates the setup and startup of their applications, they can create a new infrastructure resource with minimal interference and disruption by changing to a single line of Terraform. By using Terraform, they used the principle of immutability to destroy the old resource and create a new resource with updates instead of updating the image in place.
Immutability provides a few benefits:
Reduces the complexity of dependency management. When a package has a vulnerability, you need to identify the different versions of its software dependencies to update as well.
Minimizes disruption to upstream dependencies. You can gradually cut over traffic to the new machine running the application and determine if it works properly.
Scales for larger use cases, such as refactoring across platforms.
»Using immutability in migrations
Migration from older platforms to newer platforms benefits from the principle of immutability. Imagine migrating a Java application from a non-compliant server to a HashiCorp Nomad cluster on a public cloud. You could apply the principle of immutability by running a Nomad job describing the Java application. You could also run a load balancer to control traffic between the older Java application and the newer Nomad job. This technique, also known as blue-green deployment, mitigates disruption to upstream users or services if issues occur with the newer Nomad job.
When refactoring across platforms seems particularly challenging, applying the principle of immutability to the migration workflow offers a lower-risk approach. It may cost more and take more time but it offers a measured approach to standardizing platforms and resources.
»How policy as code an immutability speed up discovery and remediation
Many organizations today are spending too much time firefighting security and compliance risks with their focus being primarily on discovery and remediation.
Policy as code puts risk discovery ahead of deployment and accelerates it.
Standardizing infrastructure and platforms takes risk discovery and scales it, and in the process it removes the risks of security practice fragmentation. Standardization also reduces the time for remediation because all platforms use similar automation to roll out changes.
Immutability also reduces remediation time because you don’t introduce further risks. By starting with a clean slate instead of changing infrastructure in place, you prevent configuration drift and dependency issues.
»How policy as code and immutability help with refactoring
When dealing with platform sprawl, standardizing across multiple platforms may take too much effort. Rather than refactoring every resource to a single standard, you can choose to selectively refactor portions of platforms and infrastructure to conform to the standards outlined with policy as code.
Policy as code provides tests capturing the known compliance and security standards and communicates them to any team that needs to create infrastructure. As more teams see the benefits of policy as code and automated provisioning, adoption, and standardization will happen organically.
Consider applying the principle of immutability to mitigate the risk associated with migration and refactoring. Immutability provides a repeatable foundation for rolling out changes while minimizing disruption to the system. An immutable, repeatable workflow for rolling out changes also reduces the time to remediate infrastructure and security in the future.
»Learn more
To learn more about policy as code, review the examples and documentation for Sentinel. Our documentation also includes tutorials on using HCP Packer and Terraform to identify compromised artifacts and remediate them.








