What is the Difference Between Identity Access Management (IAM) and Privileged Access Management (PAM)?
PAM was conceived to manage the credentials of people. In today's dynamic, hybrid infrastructure environments and microservice architectures, developers use IAM to scalably manage credentials for much faster-moving applications.
Speakers
 Armon DadgarCo-founder & CTO, HashiCorp
Armon DadgarCo-founder & CTO, HashiCorp Mitchell HashimotoCo-founder, HashiCorp
Mitchell HashimotoCo-founder, HashiCorp


For more information on how HashiCorp Vault compares to traditional PAM, watch this video next.
Transcript
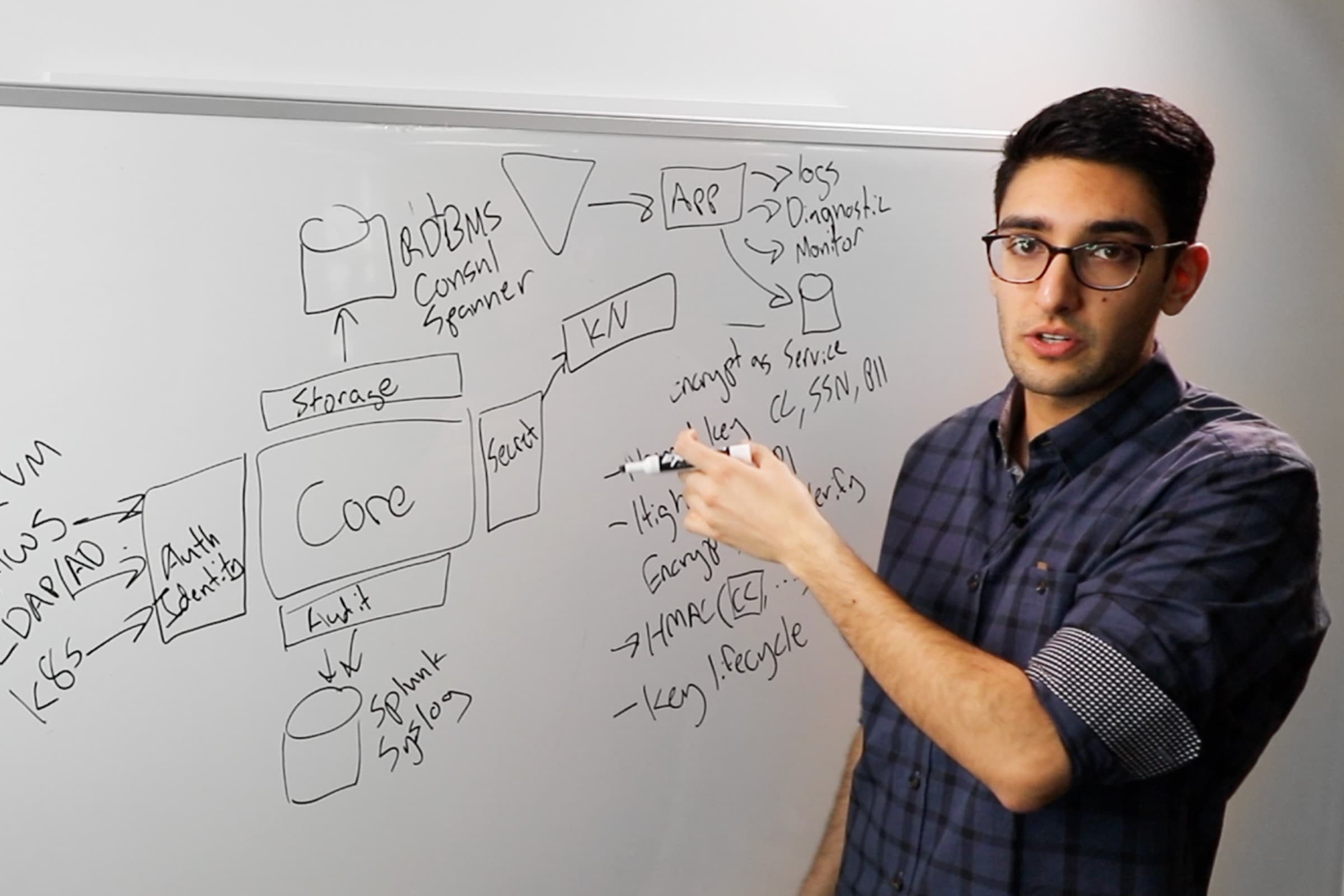
Armon Dadgar: We often get asked about the difference between identity access management and privileged access management, particularly in the context of managing credentials and secrets.
Privileged access management (PAM) is a market that’s been around for a while, and what it focuses on is the people side of it. You have a database operator or a developer or a system administrator that either needs to SSH into a box or log into a database and do some maintenance or do some sort of activity on the infrastructure. They need credentials.
PAM is for people
What privileged access management has forever focused on is, “I don’t want to give all my DBAs root credentials to the database.” I’m going to say, “OK, Mitchell, you can log in with your Active Directory credential. We’ll validate you’re a valid DBA who still works for the company. You can log into the PAM system and check out the database credential, and then you’ll go connect to the database.”
What you’re doing is saying, “I’m going to verify the person who still works for the company. If their credentials are valid, they can use that to get a credential to target SSH access or database or whatever they need. When we talk about the language of PAM, we’re talking about people doing things.
IAM is for machines
When we talk about identity and access management—the classic Amazon IAM, for example—you’re talking about machines, you’re talking about applications. “I’m going to launch my Lambda container, and the Lambda container needs read and write access from S3.” The identity is that Lambda function, or the container that we’re launching. And the access that it needs is to some other service. It needs to read and write from S3 or spin up an instance on EC2.
The difference is, when we’re talking IAM, we’re always talking about machines and apps and services. This becomes the key distinction. With PAM, we said, “I’m going to use your human identity, verified against some single sign-on, to say, ‘Do you work here? Are you allowed to access the database?’” But IAM is focused on machine identity.
And the challenge is that with people, we have a more natural understanding of what intrinsic identity means. You have a name, and you’re autonomous, whereas an app is sort of a weirder concept. You have to go out of your way to assign an identity to a Lambda function or a random binary running somewhere.
Say that I’m going to make the distinction that this random binary is a web server, and this random binary is an API server, and this thing is a database. And those identities mean something. They have access to different levels of credentials. That is at the crux of identity and access management—I’m going to assign identity to machines, application services, and tie that back into the set of capabilities they have in terms of what are you allowed to access.
Then use that to say, “Great, my Lambda function boots, it can request an S3 credential that lets it read and write from S3. We’re off to the races.” So in that sense they’re both managing credentials, in some sense. But 2 very different audiences: 1 for people, 1 for machines. And as a result you see very different scales. One might do 100 requests a minute; the other might do 10,000 requests per second. One needs to be deployed one place in the world; the other one you might need multi-region, multi-data center, global deployment because you have applications running all over the place.
Different requirements for access
You end up with a different requirement of access. One’s point and click in a UI; one’s API-driven. One’s low-scale; one’s very high-scale. One’s people-oriented; one’s machine-oriented. At a 10,000-foot view, you can say, “Well they’re both about managing credentials.”
But once you zoom in at a 10,000-, 5,000-foot view, there are a bunch of nuances in terms of access patterns and scale in the operational deployment. And that becomes the key distinguishing piece between PAM, which is a bit more traditionally people, and IAM, which is more machine- and app-oriented.
Mitchell Hashimoto: A challenge with PAM versus IAM is that, with IAM, the surface area is huge compared to the standards that exist for PAM. With PAM, it’s pretty common—from the people side—that you’ll have Active Directory, or some other of a handful of standards to verify a person is a person.
But on the IAM side, especially with the adoption of cloud and SaaS and all these different things, it’s an order-of-magnitude larger surface area of how you prove identity—not only how you prove it, but how you give it and all that sort of stuff.
At the 10,000-foot view, you could squint, and it looks the same. But the features you want are very different, too. You want session recording with PAM, which you don’t really need for a machine, in the same way.
Armon: The ecosystem integration is a huge point. For PAM, there is no real ecosystem. It’s: Active Directory, check out the credential, you go log in. Whereas with a system like IAM, it lives and dies by integration. Do you integrate with all of the different platforms that need to connect, and all of the different systems you need to govern access to? That’s a huge difference as well.