What is the Crawl, Walk, Run journey for using Vault?
HashiCorp solutions engineering VP Jon Benson guides you through the walk, crawl, run maturity model for using Vault.
Speakers
 Jon BensonVP Worldwide Solutions Engineering, HashiCorp, HashiCorp
Jon BensonVP Worldwide Solutions Engineering, HashiCorp, HashiCorp

Transcript
When you're adopting Vault, there's a journey, and this journey is not: "I'm going to do it in six months or twelve months." It's a journey that never ends, because secrets management is something that you can always evolve upon. You can always tighten up your security. You can always de-risk what some of the different threats are that are available out there in the world today. That's always going to change. There's always going to be new attack vectors, and so it always makes sense to tighten up your security.
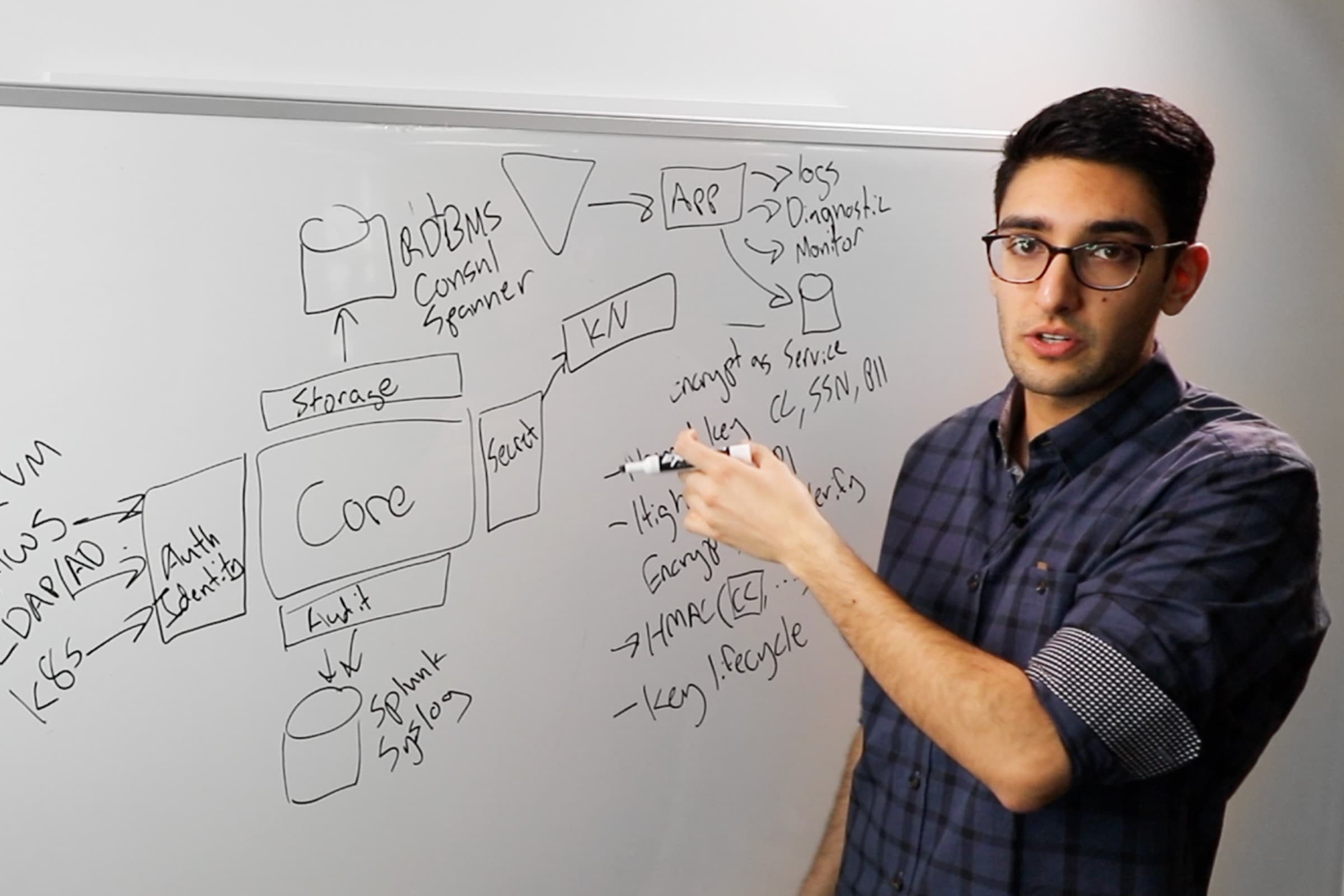
Crawl
The crawl portion of this is just getting Vault stood up and centralizing your secrets. How do I take all of the secret sprawl that exists today and put them in one place so that I can properly manage who can access what; when did they access it, etc. By centralizing those secrets and putting proper ACLs around it, you're moving a huge step in the right direction, because you can at least wrangle all the secrets that are out there.
Walk
When you're looking to walk, the way you want to think about it is: In the crawl stage, you've centralized everything, how do you make consumption of those secrets easier? This often is through your orchestration tools. Can your orchestration tools actually facilitate the secure introduction of those secrets to the underlying consumer?
Maybe it's a VM and you're using a tool like Terraform to securely introduce secrets into the VM. Maybe it's a Kubernetes, and you want to inject those secrets into the different pods that may be consuming them. Maybe it's sitting on metal, or it is on a VM, but that application isn't aware of the orchestration system, and you want to put a helper daemon like Consul Template or Envconsul that can retrieve the secrets as a sidecar and inject those into the file system or an environment variable.
It's really about the lifecycle of those applications that you've stored centrally, and ensuring that all the applications that are consuming them can do so easily. That way, you don't have to rewrite all of the thousands of applications that are legacy that you've written over time. But you've also provided an easy way for your greenfield applications that may be running on some newer orchestration platforms like Kubernetes to be able to consume that in a safe manner.
Run
Now as you move on to the run, how do we tighten up the time in which a secret that got exposed can actually be used? We implement what we call dynamic secrets; can I, as a requester of a secret, get a different secret every time I make that request? Can I have a tight TTL (Time-to-Live) on it, so that if I leave the company as a consultant or if I'm a container that just got moved to a different host, then ensure that secret gets cleaned up, and I don't have to have a human that's responsible for remembering to go revoke that secret.
What we end up with is tens of thousands of secrets—if we're doing this right—and a system like Vault is able to actually keep track of and manage all of the different leases on those secrets for you, so that if someone were to get onto a host that happened to have a secret sitting on disk, that credential probably isn't good anymore if you have aggressive of enough TTLs.
The next piece of run is encryption as a service, and ensuring that all of that data that you've been passing around your network and storing in databases can't be compromised, because it's encrypted by those encryption keys sitting within your centralized secrets management solution.