Your secret's safe with me: Securing container secrets with Vault
In a containerized deployment, how do you safely pass secrets—passwords, certificates, etc.—between containers in a cluster without compromising their safety? This talk explores and demonstrates the risks, and discuss best practices for keeping your secrets safe using HashiCorp Vault.
In this talk from HashiConf 2017, Liz Rice explains how to use HashiCorp Vault to securely manage the secrets used by containers.
In her fast-paced, in-depth presentation and demo, Liz talks about: - What do we mean by "secrets"? - Desirable attributes for secrets management - How to pass secrets to containers (the bad ways and the good) - Orchestrator support for secrets—Nomad, Docker, Kubernetes - Combining Vault with each of those orchestrators
Speaker
 Liz RiceTechnology Evangelist, Aqua Security, Aqua Security
Liz RiceTechnology Evangelist, Aqua Security, Aqua Security
Transcript
My name's Liz. I work for a company called Aqua Security. If anybody's seen me speak before, I've done some talks where I've written a container in 60 lines of Go. I've written Strace in 60 lines of Go. Today I'm not going to be writing Vault in 60 lines of Go. So if that's what you're expecting, I'm afraid that you will be disappointed.
But I am going to talk a bit about Vault, and in particular how we can use it to help us with managing secrets for containers.
Just a little bit about Aqua Security: We have a product to help enterprises secure their container deployments. One of the things it does is help with secrets management. If you want to ask me about any of the other things it does, I will be here for the rest of the day and tomorrow. But safe secrets management can be done with Aqua but it can also be done with other mechanisms.
A lot of the orchestration platforms have secrets management capabilities so that's really what I'm going to talk about. And in particular how we can use Vault with that. But first…
What do I mean by "secret"?
I mean things like passwords, API tokens, certificates—things that you don't want other people to get hold of.
I'm not talking about your vast database of people's social security numbers—like Equifax. I'm not talking about those big databases. I'm talking about the things that we use to protect those.
The information that your code needs in order to access what it needs to access. Your web server maybe needs a database password so that it can access a database to do whatever it needs to do. And we want to make sure that we can get that information to the code that needs it without anybody else getting to see it.
How many people in the room are using containers? That's a pretty large proportion of you, good. How many of you are using containers under some form of orchestration? Also the majority, good.
You'll be aware that you are going to start some containerized code. It's going to land somewhere in your cluster. You don't know where. And the secrets management part of your configuration needs to get the secrets to the right code at the right time.
Desirable attributes for secret management
Let's think a little bit about desirable attributes—things that we would like to see from secret management.
Very importantly we would like to encrypt our secrets.
We want them to be encrypted when they're in storage and we want them to be encrypted when they're flowing around between machines in your cluster. We really only want to see them in plain text, in memory in the code that needs to use that password.
Why do we want to keep it encrypted? Well, if somebody somehow gets access to your cluster, gets access to one of your machines, gets access to one of your containers. If the secret is in plain text the job is done, if the secret is encrypted they still have a challenge ahead of them. Kind of obvious.
Ideally, we want to limit access to those secrets to the code that needs it.
This may not apply to you. You may have a relatively small deployment but if you're a large organization and you have a large number of secrets—maybe different products, different components that have access to different secrets—it's going to help if you can limit which containers have access to which secrets, because should anything go wrong, your exposure is smaller.
But if something does get into one of your containers maybe it can only get to that small set of secrets that that container should see and not all of the secrets for the whole deployment. That would be better.
Similarly with users, if you're in a large organization, you have multiple teams those team members don't all need access to all of the secrets from all the other teams. A lot of the time your developers don't necessarily need access to your production keys.
Being able to control who has access to which secrets, when—from a container perspective and from a user perspective—is useful.
And then I also put write-only access on this slide. I was with a customer yesterday and showed them the slide and he said, "Write-only, are you sure you don't mean read-only?" And I thought he was quite a senior guy, so I thought it's interesting he hadn't come across these concepts. It's the idea that I can change a password, or I can add a password, or a secret of some sort, but I can't necessarily read it back out again. And we'll see that later on.
(You might not need all these characteristics but the thing is to bear in mind when you're evaluating how you manage your secrets.)
And then finally the life-cycle of secrets and how your secrets management system can cope with this.
Unfortunately, the more time goes by, the more likely it is that your secrets will somehow have been compromised. It might be because a bad actor has done a bad thing. It might be because somebody has been an idiot and left a notebook on a train full of your passwords. Somehow, the more time goes by, the more likely it is that secrets will somehow have escaped your control.
If you know that a secret has been compromised, you need to be able to revoke that. You want to essentially stop that one from working. Replace it with a new value. Unfortunately, we don't always know when something has been compromised. So it's a good idea to rotate our secrets on a regular basis. And that way the old values don't work anymore and they need to be replaced with new ones. And every time that happens—the revocation or rotation—we need to get the new values into the containers wherever they are.
You may also have a requirement for audit logging for compliance purposes—it's often a requirement to know which code and which people have had access to different secrets and when they've changed them and what's happened to them. You may need that for a kind of tick-in-the-box compliance reason. It can also be really helpful if you're doing a forensic investigation after something bad has happened.
Passing secrets to containers
That's kind of talking in the sort of theoretical sense about what we'd like to see from secrets management. Now let's think about the practicalities of how we actually get a secret into a running container. And I'm just here talking about the bit where you execute the code and it's got to be able to read that value.
We'll start with some really bad ways.
The bad ways are to bake the secret value into the code somehow. They get into that image. Probably half of you say, "Of course that's stupid," and half of you are going, "Hmm, yes, no I've never done that. No, don't look at me."
In case it's not obvious to you, if you have your secrets in your source code, you've made those secrets accessible to everybody who can see the source code. Open source? That's a really bad idea. If it's closed source you don't necessarily want all of your developers to be able to read all your secrets.
The other thing is it couples changing your secrets with changing your code. You need to deploy new code if you want to deploy new secrets and that's probably not a good idea. If you're the security person who wants to wake up a developer to say hey, it's 3:00 in the morning but I need you to deploy a new secret. You are not going to be very popular. So don't put your secrets in the source code.
If they're not going to be in the container image, we're going to have to get them in at run time. And there are two methods for doing this:
One is Environment variables.
So let's actually just take a look at doing this. Let's do docker run … we'll get rid of it … I'm going to give it a name … we're going to pass in something like SECRET is mypassword … and we'll run an Ubuntu container and we'll just run a shell. Kind of obviously, that value is in the environment in the container. Anybody who can exec into that container will also be able to read that secret.
In case you don't know. it's also accessible from a couple of other places. So we can, for example, inspect that container. And we can see anybody who can run docker inspect—possibly remotely not necessarily on the exact same machine—can see that environment very well in the clear. And that's from where it was passed in and that run command.
Also—just going to send this to sleep for a little while so that I can find process id inside that container. Now I need to be sudo or root to do this, but inside the /proc directory, there is a ton of really interesting information about running processes—including the environment. And these are null-separated. So I'm just going to convert the nulls into new lines and we can see, right at the top there is my secret.
Now you can make a very strong case that [if] anybody who has root access to that machine and can do that [then] there are all sorts of other issues you have anyway. So it's just something to be aware of that anybody who can get root access on that machine can read all of your secrets from all of your running containers—no problem.
With environment variables, just to recap: Anybody here can run docker inspect, anybody who can exec into the container can read the environment. Root can get it out of the /proc directory.
But perhaps the most compelling reason to not use this mechanism is that environments are logged a lot. Quite often software when anything goes wrong it will dump the environment to some log file which now then contains all your secrets in the clear accessible to anybody who can read those logs. So for that reason, quite a lot of people will say environment variables are a bad mechanism for getting secrets into containers. You should use the alternative which is to…
Mount a volume.
So you have a volume on the host containing files containing your secrets. The code inside your container can read those secrets out of the file.
"But wait, Liz," I hear you say, "You said don't write your secrets onto disk, they have to be only unencrypted in memory." So what you want to see here—and this is generally the case—is that those volumes are temporary filesystems. A temporary filesystem looks like a filesystem—it has things that look like files and directories, but it's actually only held in memory, not on disk. So that's good.
How does this compare in terms of ways that people can get to those secrets?
- Well, the docker inspecting goes away. If I run docker inspect I can see the fact that volumes are mounted but you don't automatically get like a dump of all the files inside those volumes. So people can't just easily grab your secrets by running docker inspect.
- Anybody who can exec into the container can, of course, read that secret.
- The /proc directory thing is still a risk—again only for people who are on your host so probably, you have other concerns—but you can read the root file system of a container from inside that directory.
- One thing that does go away—as well as docker inspect—is the logging thing. You're unlikely to see routine logs of all the files.
So having a mounted volume holding your secret is probably a slightly more secure way of going about it than an environment variable. There're still risks either way.
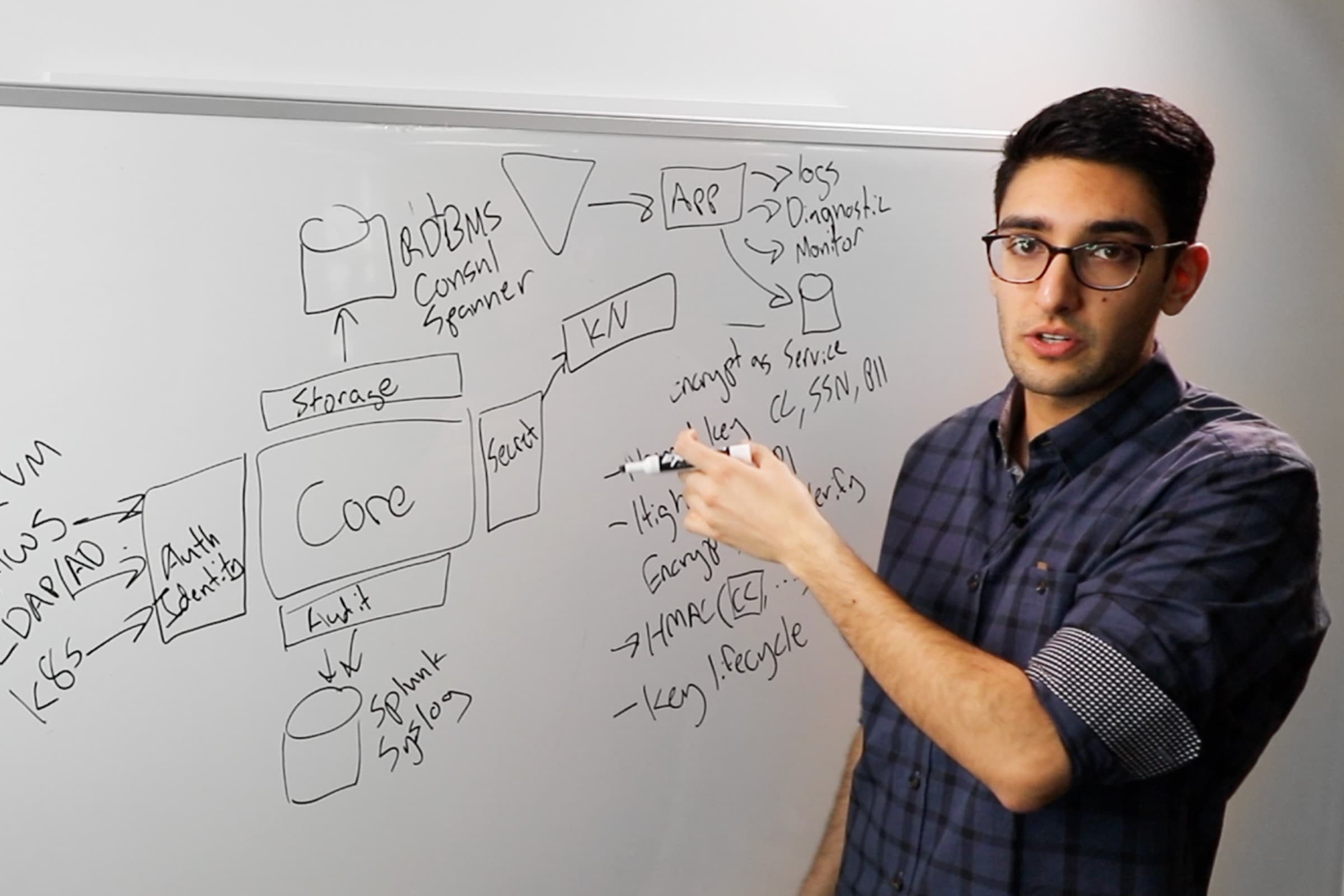
Orchestrator support for secrets
So that's talked about how at run time the secret gets from the host into the container, now let's have a look at the ways that some orchestrators support all these features of secrets management.
So since we're at HashiConf, let's talk about Nomad. Who's using Nomad? So as I rather suspected a lot of you using orchestrators that are not Nomad. And that's not a surprise. Nomad does have really nice secrets management integrated with Vault though. So it is one thing that is very strong about the solution.
A few things to bear in mind … You have to use Vault in production mode. But they say that really clearly in the documentation: don't run in development mode for production.
Vault is giving you encryption of the box, it's giving you these security primitives that Nomad can then use to take care of everything we're looking for from a secrets management solution. The secrets can get passed into your job, container or otherwise as a file, and Nomad will look after the exchange of tokens required to get that secret information out and it can poll—so that if you want to change your secret values if you're rotating or revoking a secret, it can bring your container up to speed.
And it also takes care of the access control things that we might be looking for. And the audit logging that we might be looking for.
So I'm going to give the Nomad plus Vault combination, three ticks for the three different things that we're looking for. But as we said not everybody is just using Nomad.
Some people might be using Docker. Anybody heard of Docker? Yes, of course, you have.
Out of the box, Docker's Swarm has some pretty nice solutions for managing secrets. Only works for Docker Swarm services, not for containers that you run by typing in docker run. Swarm will set up encryption between each pair of nodes that are mutually authenticated. This all happens for you without you having to do a single thing out of the box. So very nice and easy to use.
Docker only supports … the volume method for getting secrets into the containers. I think a very opinionated about not using environment variables for the logging reason which is a completely valid opinion to hold.
In terms of the access control, if you're using the Enterprise Edition they do have role-based access control and they also have things like the audit log solutions baked in.
Couple of things to bear in mind with the Docker solution though.
First of all, secrets are held in the Raft log. Raft is the mechanism that Swarm managers use to communicate with each other. And this is the one thing that doesn't happen automatically out of the box. You have to explicitly say I want to lock my Swarm. Otherwise—although everything is encrypted and that's all beautiful—there is an encryption key sitting right next to your host. So you want to just be aware if you're using Swarm make sure to lock it. Otherwise, all that encryption is not as secure as you would hope.
The other thing that isn't quite so strong with with Docker we can see if we just have a quick look at some of the help for that—if I look at
docker secret, we can see you can create, inspect, list, and remove secrets but you can't update them, you can't change the value of an existing secret. If you're running a service that has access to one of these secrets you can add new secrets to the service so you can do a rotation by creating a new secret and deleting the old one. But there's a couple of steps to that process. It also requires the container to restart. That could be absolutely fine. We're all writing our container code to be cattle not pets. And to be able to restart at any time this is probably absolutely fine. But just a thing to be aware of, when you want to rotate your secrets, when you want to revoke a secret it will involve a container restart.
So for that reason, I've kind of … I'm not going to give them three out of three. I think the life-cycle management it could be easier to rotate a secret than it is with the Docker solution.
And then finally Kubernetes. Who's using Kubernetes? Okay. Few hands. I apologize if I've not mentioned your favorite orchestrator. There may be a few others.
So in Kubernetes, secrets are set up through YAML files like everything. It supports both the volume mechanism or the environment variable mechanism. You immediately get namespacing for access controls. So like a lot of things in Kubernetes, thing's are namespaced so you can only see the secrets that are inside the namespace that you're looking at.
And, I can't quite remember which version—I think maybe 1.7—RBAC was introduced, so you can turn on role-based access control and limit access to the different secrets. Secrets are stored in etcd. And only recently has etcd had encryption support in Kubernetes. You have to go through a bit of work to make sure that they are encrypted. So for that reason I'm not going to give them the three out of three—it's possible and there is a lot of work going on in the Kubernetes community to improve the ease of using a lot of security features including secrets management. But out of the box, it's not as easy to use as some of the other alternatives today.
Combining Vault with other orchestrators
So we've seen that the Nomad plus Vault combination was really strong, and Vault is a really nice way of getting a bunch of the security primitives that we want. It gives us the encryption out the box, it gives us all these nice sort of token renewal features that are really strong.
So what we want really is to use Vault to manage the secret storage and use that in combination with whatever orchestrator we want to use. And the good news is that that is indeed possible.
We talked about Nomad having integration. Docker are working on a plugin backend approach for secrets. So Vault will—I believe—be one of the backends that will be supported by that. So you'll be able to use the same Docker Swarm commands and the same Docker secrets commands but they'll be stored in Vault for you.
Kubernetes: there is an existing project, Kubernetes Vault that will let you use Vault for the secrets backend for Kubernetes. And I'm not sure whether some of the announcements this morning will also make Vault Kubernetes … Well, it will make a Vault and Kubernetes integration easier, but whether it covers secrets I'm not sure yet because I only heard about it this morning.
And then another approach is what we have at Aqua which can use a number of different secrets backbends of which we support Vault and use that to inject secrets into running containers through Aqua code alongside any orchestrator. So I'm going to just share that.
With Aqua, we're running a piece of agent code on every node in a cluster. I've got a single-node cluster on a virtual machine here and I have a secret store set up to use Vault. So that's where one of the places that I can store secrets.
And I can configure a secret. This is what I meant about write-only access. There is a secret here but I can't read it and all I can do is change it. So let's change it here.
Now, rather than passing in a secret value, I'm going to pass in like a key to the secret which is this. Okay, let's call it Ubuntu again and we'll run a shell.
So similar to what we did before, we can look for that secret but rather than getting the key to the secret we can see the value that I just typed in. That value has been stored in Vault and retrieved by the Aqua code. I can run and inspect on that container. And now we've got the key to the secret rather than the secret value.
So if somebody has the ability to run Docker commands on this machine they don't automatically get to see the secret. We'll do that sleep thing again and find the process id and take a look in the /proc directory … translate the nulls into newlines … and let's just find secret. And again we only see the key to the secret rather than the actual secret value of Hello Austin.
So we've removed some of the concerns about using environment variables by using this mechanism. This is also injecting the secret into a file. So again that's available—if you want to use the file mechanism, you can. And it's also possible to use a slightly different environment variable in the run command which will say "only use the file version and don't use the environment variable. So if you're concerned about the logging issue, that is also possible.
And then let's see what happens with rotation. So I'm going to change its value again … and we'll look at that environment again. And the secret has been updated with our container restart and the environment is also been updated in the file version without a container restart which is pretty neat. You might not need that but it's there if you need it.
So that is taking advantage of all the goodness of Vault for encryption and the token management we had to pass in a token from Aqua to be able to get access to these secrets. We've avoided some of the ways in which environment variables get leaked. So it's not leaked through the Docker inspect or through the /proc mechanism that way.
Oh, I didn't show you the audit logs. So if I look in here we can see where I updated it. We can see that every time that that a secret gets used by a container—and in fact if my container is still running—I can look in here and see which containers are using which secrets. So if we learn that a secret has been compromised this could give us a handy shortcut for figuring out which containers need to be affected.
And there's also the ability to limit access to secrets by different containers using labels. And there's a whole role-based access control system built in there. So by using the Aqua injection mechanism plus the storage in Vault, we can get all those three ticks again and we can get out which ever orchestrator we using.
Summary
So I am going to wrap up. And the key things I want you to take away:
- First of all, if you are writing your secrets in source code, please stop. Don't do that any more.
- When you're thinking about secrets—like everything in security—there's no perfect solution. All you can do is reduce risk and you need to have a think about what risks you're concerned about [and] what your priorities are.
- And I wouldn't say choose your orchestrator on the basis of its secrets management—you want to choose your orchestrator on the basis of its orchestration capabilities. But in many ways your secrets management may vary according to which orchestrator you are using.
- Vault does provide really great underlying security primitives, the storage solution for secrets, and the ability to then actually have Vault using a backend. The secret data can be held in a variety of different physical storage mechanisms [which] gives you the ability to change that to your particular environment and your particular requirements.
So the last thing I would leave you with is that we wrote a white paper about secrets management. So if you have questions and concerns about secrets management you may find the answer in that white paper with a nice little easy to remember URL.
And so as I said, I will be here for the rest of the day and most of tomorrow to answer any questions you might have about container security or about writing anything in 60 lines of Go. So thank you very much.