Client-Side Response Caching Using Vault Agent
This talk will discuss features that existed in Vault Agent and explain the new caching functionality that came in Vault 1.1, followed by a demo.
Vault has features to improve performance-based scaling to meet a high number of read and write requests. These features include:
- Performance replication
- Performance standbys
- Batch tokens.
However, outside externalities like misconfigured clients and applications can cause problems. Ideally, clients should use the Vault tokens until they expire. Failing to do so causes creation of a huge number of tokens, leading to a write burden on Vault, which can get problematic.
Vault Agent in cache mode provides a solution. In this mode, specific responses from Vault get cached on the client side. Whenever clients request new tokens, the Vault Agent performs cache-lookup to return the cached token response. This avoids fresh token creations thereby reducing write loads on Vault. The same is applicable to leases as well. When clients request new credentials, Vault Agent performs a cache-lookup to return credentials with valid leases instead of requesting fresh credentials. Vault Agent acts as DDoS protector against misconfigured clients that continuously request for credentials.
Speakers
 Vishal NayakVault Software Engineer, HashiCorp
Vishal NayakVault Software Engineer, HashiCorp

Transcript
Hello, everyone. Good afternoon. I will be talking about "Client-side Response Caching Using Vault Agent." I am Vishal Nayak. I’ve been working for HashiCorp for more than 3 years now, and I am on the Vault team.
Even though the title says "response caching," I will be talking about many more things today. We'll be talking about basically these items: - Secure Introduction - Vault Agent Auto-Auth - Vault Agent secrets caching
The first one we'll talk about is Secure Introduction. And then we'll move on to talk about what a Vault Agent is. And then we'll see the Auto-Auth feature of Vault Agent, and what problem it solves. And then we'll move on to define another problem space, of Vault getting potentially loaded due to misconfigured clients. And then we'll talk about the secrets caching feature of Vault Agent that solves that problem.
Secure Introduction basically defines the problem space, and then the Auto-Auth feature tries to solve that.
At the end of this talk I hope that all the applications and services stop worrying about how to get Vault tokens altogether. And then zero token maintenance by all the applications, applications and services should not, and need not worry about how to maintain our token.
And then we will see that once the credentials and the token are received by the applications, how to make sure that they're used in the way that HashiCorp recommends. And we'll also see one way wherein applications can use Vault tokens, but never really need to see that.
Secure Introduction
Let's dive into what Secure Introduction is. We all know Vault is good at keeping secrets. It stores everything encrypted. It issues only secrets to those people who have access to it. Everything is encrypted; everything is good.
But the main catch is that everybody needs a Vault token in order to get anything done from Vault. Everything is centralized, but everything needs a token.
Secure Introduction is a problem space wherein all the applications and services somehow need to get hold of this first Vault token. If the services are running in GCP or AWS or Kubernetes or you name it, they all need a Vault token to operate. Secure Introduction is the secret zero problem: how to get that first Vault token.
After getting the first Vault token, services and applications should also make sure that the token is alive and healthy. Tokens usually will have a time-to-live (TTL) on them. So before the time-to-live is hit, applications and services should renew the token frequently until the maximum TTL is hit. If that is not done, the token will get invalidated and become a bad token.
There are various authentication methods to get a Vault token. You can use AWS Identity and Access Management to establish the AWS credentials to get a Vault token. You can use Okta credentials to get a Vault token. You can use RADIUS authentication credentials to get a Vault token, LDAP, and many more authentication methods to get a Vault token.
The logic to keep the Vault token may not be straightforward. Particularly when hundreds and thousands of applications are getting Vault tokens, they all need to stop worrying about whatever they're doing, and worry about how to take care of the tokens that they already fetched from Vault.
After taking a look at this problem, HashiCorp started an internal project to solve it. They called it Vault-Secure-Introduction. It ran as a daemon on the AWS instance and got the AWS EC2 instance metadata, took the PKCS #7 signature of that, sent it to Vault, got it authenticated, and fetched the Vault token. If you run the Vault-Secure-Introduction binary on an AWS EC2 instance, services need not worry about getting a Vault token.
But we knew that this was not a full-fledged project. And we also knew that this was supposed to be on the open-source side of Vault, and not on the enterprise side, which it was.
Vault Agent
Vault-Secure-Introduction became Vault Agent. Vault Agent is a client-side helper that is used to interact with the Vault server on behalf of the clients and applications. This was introduced way back in 0.11. This runs as a client-side daemon. And the good thing is that it is part of the Vault binary. You don't have to download another binary or anything. This is just a mode in which Vault runs.
Auto-Auth
Let's talk about the Auto-Auth feature that tries to solve the Secure Introduction problem. In the Auto-Auth mode, Vault Agent will read the configuration file and then see where it is being run, whether it is being run on AWS or GCP or if it's using any other JWT authentication method or AppRole authentication method.
Based on those credentials, it will interact with Vault and get the Vault token.
On top of that, Vault's Go SDK already provides a way to keep the tokens renewed on the client side, but not everyone uses it. Vault Agent uses this feature to keep the token renewed all the time.
Another problem is after the token hits its maximum time-to-live, it needs to be re-authenticated. And services cannot take care of all this responsibility, particularly when there are hundreds and thousands of applications running.
Auto-Auth currently supports Alibaba Cloud, AWS, GCP, Kubernetes, and many more authentication methods.
How Auto-Auth configuration works
It's a very simple configuration file. We can see that there is an Auto-Auth block at the top. That has 2 things, the method and the sink.
First one defines where the Agent is being run. In this case we are using AppRole as the authentication method. AppRole is an authentication method which is very similar to the username/password way of authentication. But it's for the machines to authenticate themselves.
AppRole authentication is enabled on the Vault server, and then a role is created on it. And against that role we create what we call a SecretID. The ID of the role serves as the username. And the SecretID that we create serves as the password.
All that AppRole authentication will do is to ensure that the RoleID is already known by the applications beforehand. During the service startup, somehow the SecretID is injected into the service so that the service can use both the RoleID and the SecretID to interact with Vault and get the Vault token.
In this case, we are telling Vault Agent to do it on behalf of the client.
The second block is the sink block. Sink tells the Agent where to dump the Vault token that it got from Vault server. In this case, it is explaining that the type is a file and the path name of the file where it needs the token to be put.
One important thing is that sink can be multiple. It can be used as a fan-out feature, wherein different services and applications are looking for different files they want to look into for Vault token, and Vault token magically appears in those files.
Auto-Auth workflow
Let's take a look at how it all works. The green block that you see is the client side, and the gray block is the Vault server side.
The application will not do anything. The Agent automatically reads the configuration, and sees the method and the sink defining the configuration file, interacts with Vault, and gets the Vault token back. After getting that token, it dumps it in the sink defined in the configuration file.
Then the application will only need to look at the sink, read the token, and use it to interact with Vault directly. In this case, the client does not need to implement authentication and token-enabled logic at all. The Agent will take care of doing that.
Let's do a demo and see how it all works. First we'll run a Vault server, and then we'll enable the AppRole authentication method, create an AppRole RoleID and a SecretID. And then configure Agent and have it fetch our token automatically.
Here we are killing the existing Vault process, if there was any.
This command starts the Vault server and then Vault auth-enabled AppRole. This enables the auth of AppRole authentication method.
This command creates a role. And then immediately followed by that we create a SecretID against that role and we read out the RoleID. Now we have Vault server running, AppRole authentication enabled. We have RoleID and a SecretID fetched.
We take those 2 credentials and dump them to these 2 files, /tmp/roleID/file and /tmp/secretID/file. Then we move on to configuring the Agent. In the Agent, this is exactly the one that we saw on the slide. This has an Auto-Auth block, which has the method as AppRole, and the role_ID_file_path and the secret_ID_file_path.
These 2 are the same files where we dump the SecretID and the RoleID. Sink is a file, and it is writing to tmp/approle-token.
The next block is Vault, which tells the Agent where Vault server is running. And then we simply begin the Agent.
In this one I'll run the script that we just saw. And in this one we'll be watching the sink file. Let's look at the logs.
I ran the Agent; the Agent is now running in the background. If we take a look at the logs, Agent created a file sink, and then it started authentication. It initiated the authentication. Authentication was successful. It started the sink server and wrote the file of the sink.
Also, we need to see one more thing. The token that we are creating has an ADL of 3 seconds. Which means that within 3 seconds, this token needs to be renewed by the service asking for the token. And after 10 seconds, this token will get invalidated regardless of renewal.
Agent will need to ensure that it roughly takes about 3 to 4 renewals, or 5 renewals in case of jitter and the back-off logic. After that, after roughly 10 seconds, it needs to re-authenticate and fetch a new token.
In the logs we can see that the Agent renewed the token about 5 times, and then the renewal said it is done. And then the Agent started to re-authenticate. And the token was returned to the sink again.
In order to take a look at how this is working, we can look at this window. If you take a look at this part, every 10 seconds this switches to a new token.
It changed now. So that was Vault Agent in action and how it used AppRole authentication method to talk to Vault and get a new token. It continuously does that every time that the token hits its max TTL.
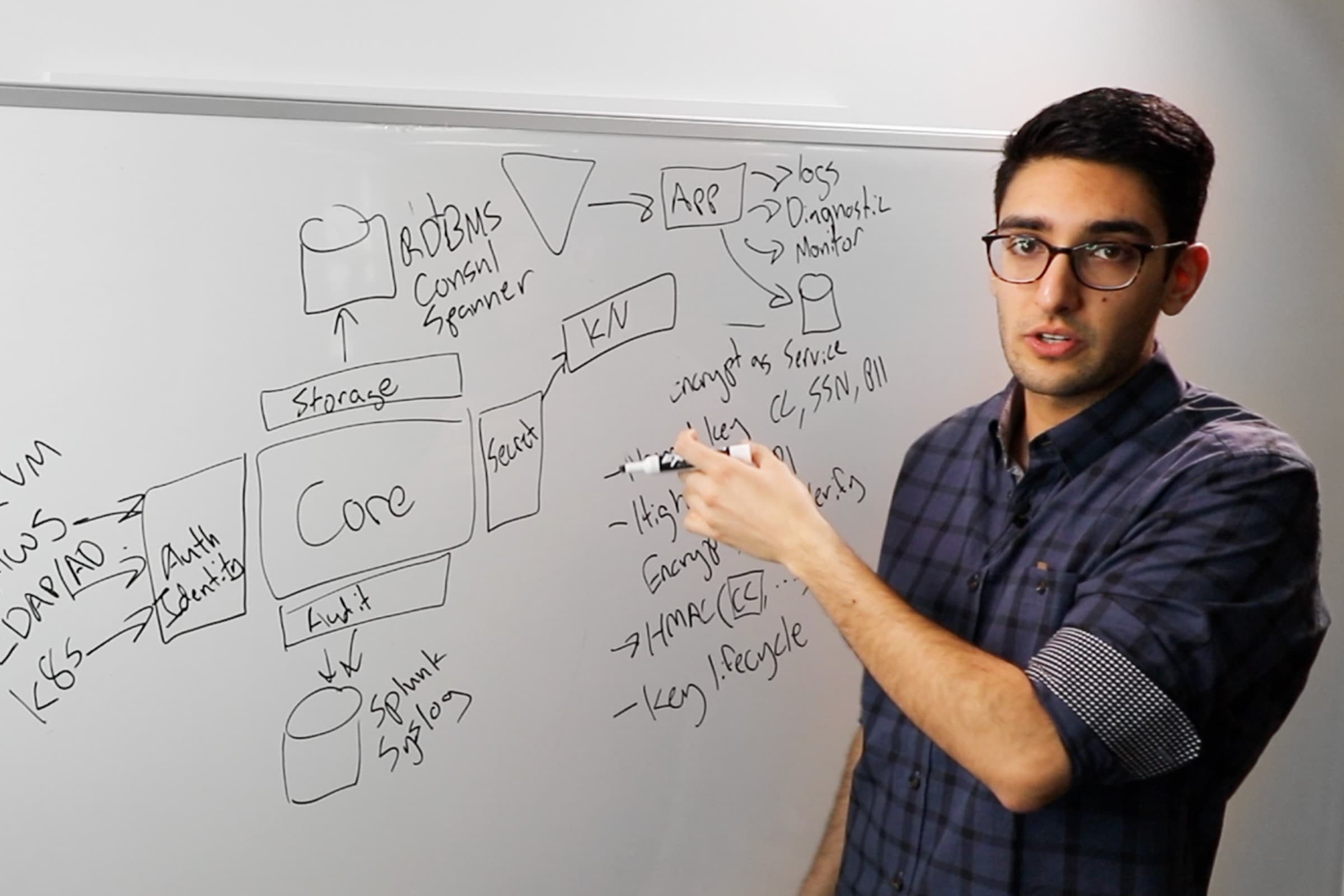
Agent caching: Problem statement
Let's move on to another problem statement. We saw that Agent was creating the token. Recently, HashiCorp introduced something called batch tokens. Before that, all the tokens created by Vault used disk storage. Batch tokens are intentionally designed to not use disk storage and be very lightweight.
But outside of that, all the regular tokens—not batch tokens; we call them "service tokens" now—that is expensive. The reason I call it expensive is because, when a token is created, it needs to store itself. And it has multiple indexes along with it. It has something called "a parent index," and it has a token accessor. If replication is in play, all the data will also be replicated in the Write-Ahead Logs that we use for replication to work. So it gets replicated there.
And then if DR replication is also in action, all the things that are in the primary cluster are also replicated on the secondary cluster. That means that all these things will be replicated to the secondary as well, and those many storage rights will go there.
This is the same case with the dynamic credential creation as well. Even though dynamic credential creation does not result in a lot of storage rights, it does result in an active lease under timer being maintained in memory.
What it means is that, in order to rework the lease and the dynamic credentials that Vault issues, it maintains a timer and tracks it in memory all the time until it is done. So even if Vault goes down, it remembers all those leases. If you bring Vault up, it will restore all the leases and keep it in memory.
If there are too many dynamic credentials created, that can become a problem. Usually Vault scales to a very large degree. It fails to address the problem only when the clients are misconfigured.
What do I mean when I say misconfigured clients? One of the customers we had was running into a problem where it had thousands of services requesting Vault tokens with every action that it was taking, every time. And the detail of the token was much larger. So all the active leases of the token used to live in memory, and the services were creating tokens every time continuously.
Obviously this led to a problem, where the memory was getting choked, the storage was getting choked. The instances were not responsive; Vault became unresponsive. And the problem was exactly this: Instead of reusing the tokens that the clients received in the first place, all the applications would request a new token with every action they did.
As a solution to this, the Vault team developed Vault Agent caching. The idea was, since Agent was anyways running as a daemon and used to authenticate with Vault, why not unload that daemon into a full-fledged server and consume entire Vault API? Client and applications will not ever need to talk to Vault server directly. It simply points to the Agent itself.
And Agent will have a listener of its own, and it forwards the request to the Vault server and then somehow ensures that, even though the clients are misconfigured, it returns only those responses that it needs at the client, and not create a fresh one every time.
It essentially proxies all the requests and manages the responses. We will see what Agent does with the responses. It does not need to deal with all the responses, but it has something to do with some responses.
Agent caching scope
It only caches those secrets that are long-lived and have an expiration. There are only 2 things in Vault as of today that need this: tokens and leases. Leases refers to dynamic credential generation: DB passwords, AWS credentials, anything of that sort, anything that generates in a lease. If you have PKS certificates generating in a lease, that will also fall under this same problem space.
Agent takes the responses, and the majority of the responses are simply a passthrough. But if it is a token or a lease, it caches that. So the next time the client asks for the same secret, it will see that the same client does already have a valid lease and a valid token. And if yes, we return it.
Reading KV secrets are also not cached because it does not create tokens and leases. But we have plans to make sure that this can also be supported. There are some underpinnings that we are working on that can enable this. But right now Agent cannot do it.
Agent caching configuration
Let's see how Agent caching is configured. It's pretty simple. We need to make sure that Agent runs as a server. There are 3 things that need to be done:
Add a cache {} block to let the Agent know that it needs to run in the cache Vault mode as well.
Add and the second one is a listener {} block. And we basically tell it what to listen onto. It supports two 2 things at this point: TCP and Unix UNIX socket at this point.
Set And the last thing is Vault Agent VAULTAGENTADDR to the address of the listener. So we already know about Vault ADDR, but this time if you set VAULTAGENTADDR, CLIA will already know that ADDR address, and refer to our Agent address, and send the requests to Vault Agent instead of the Vault server.
Agent caching: Caveat
There is one caveat. I'll delve into a little bit of implementation detail to explain this, but I'll also hopefully justify why I explained the implementation detail to explain this point.
Essentially the Agent looks at the HTTP request as it is, along with the request headers and a body. It serializes everything into a blob, and then hashes that to create a consistent string for a particular request. It uses that string as an index into the cache to identify unique requests from the applications.
The problem is that, even though the request is the same, if the order of the request parameters of the headers is modified, it results in a different serialized blob. Hence it results in a different hashed value. And hence the index will change. So Agent will think that it's a unique request, not a cached one, and make another request to Vault server and get a different credential.
But this was experimental. There are some other approaches that we are trying out. We wanted to try this out and see how it works in practice. It looks like it's not hurting as much as we thought it would. Applications are making similar requests all the time. We have not run into any issue. But we still certainly have plans to improve this workflow.
Agent caching: Renewals and evictions
How does Agent know how to evict the cache and trace? This is a tricky problem. The problem exists because Agent has no way to know what the Vault server is doing. It needs to make an API request to check with the Vault server and see if the token is revoked or not.
Another problem, if the applications and clients interact with Vault directly, and without the Agent knowing about the interaction that happened with the Vault server, the Agent will never know to invalidate the cache. So it does 2 things. One is, if the renewal in the Agent, which is taking care of both the tokens and the leases, is completed, it knows that the cache invalidation needs to be done. And it evicts the entries from the cache.
The second one is it tries to do some best-effort thing, where it tries to see what the request is. If the request is to revoke a token, it'll know that anyways the client and the application are asking for the token to be revoked: "Let's follow the request of the Vault server. Look at the response. If it is successful, let's invalidate the cache."
And the same is the case for lease invalidation as well.
Possible improvements
Can this be improved? Here's a sneak peek into what might be coming in the future, but don't take it for granted.
We are thinking of ways where there is a notification method that clients can subscribe to and get updated for. So if such a thing lands, then this certainly can be improved because with cache invalidations, all this best effort will become certain effort.
And what happens when a user is granted a new policy? What I mean to say is that an application has already gained a token from the Vault Agent. And the operator of Vault issues a new permission to that user, and requests that user to get a new token in order to get access to some of the resources in Vault.
But when that application makes a request to the Agent, it gets the same old token that it already had, not the new token. In that case, the same operator can also tell the same application, "Bust the cache using the Cache Clear API."
This is achieved because, when we make an entry into the cache, we make sure that we use multiple indexes to do it. When a response is cached, we index that entry based on which token access resulted in that response. Which API request spot was the request making in order to get this response?
Based on all those factors, you can bust the cache entries. This API is active only on the Agent and not on the Vault server. Because it affects only the cache maintained by the Agent. So hit this API on the Agent and supply that token, that will be validated and make a request again. That application will get a new token.
Agent caching: Something to remember
If tokens expire, all the leases that were created by that token also expire. This is a general Vault philosophy, and this is how Vault works. This has nothing to do with Agent. But there may be consequences. If the renewal of the Agent is stopped, if the Agent is brought down, eventually all those leases and all those tokens will expire. This is applicable for Auto-Auth tokens as well.
Something to keep in mind is that when the Agent goes down, all the tokens will not get invalidated automatically. It will only stop the renewal process. It does not mean that all the tokens are revoked automatically. All of these leases will eventually expire, but not immediately after the Agent is brought down.
Security concerns
Let's see if there are any security concerns. Primarily we believe in the zero-trust philosophy. And in the same way, an Agent does not have any permissions to talk to our server whatsoever. It only has those permissions to access the Vault server as much as the client had, with the credentials that it provided using the auth method.
The Agent does not persist anything to storage. Everything lives in memory. Which is why when Vault server goes down and comes back up, it restores all the token leases and the secret dynamic credential leases. But the Agent will not do it. We cannot rely on hitting storage.
Sink currently has support for dumping things to file. But we are thinking of doing the same for UNIX sockets as well. But we have seen that people are using tmpfs and ramfs instead of the storage directly. So that way the credentials never leave the memory of the application and the service where it is running.
And even if the Agent is not there, the application would have fetched the token and kept it wherever it intended it to be. Instead, if people begin to use this, operators can decide where the tokens will go, generally speaking.
Cache + Auto-Auth
There is another neat feature that we thought could change things for good. Earlier I made a statement that anything and everything needs a Vault token to interact with Vault. This feature enables applications and services to never see a Vault token at all in their lifetime. This is achieved by setting the flag use_auto_auth_token = true to the cache block.
What it does is that when applications make a request to the Vault Agent, it sees that the request does not have a Vault token on it. And the configuration for Agent says, "Use the Auto-Auth token." So if there is no request, Agent will automatically stick the Auto-Auth token to the request, and then forward the request to Vault server.
Earlier we were in a world where services need to do some juggling to provide identity, to get the tokens, and then do some more juggling in order to maintain those tokens by renewing them, and then re-authenticating them. And then do some more juggling to distribute those tokens to all the other applications that needed them.
Now we are moving into a mode where we do not ever have to worry about getting the Vault tokens, renewing them, and storing them. All these problems can be completely offloaded to Agent.
Agent caching: Workflow
Let's look at Agent cache using a diagram. The gray block above depicts the Vault server. And the green block below shows Vault Agent on the client side.
The application, instead of talking to Vault server, requests a lease or a token to the Vault Agent. It need not necessarily be a lease or a token. It can be any request. But the response will be a passthrough, and cache will be a no-op. But only in the case of a lease or a token. If it looks at the cache, and if there is a response already, it returns it back.
If not, the request is forwarded to the Vault server. Vault server returns the lease or the token requested by the app, and then stores it in the cache and returns it back to the application. And then application can choose to directly talk to Vault using that token. And then use the DB credential as well.
Let's look at a demo for this. This is exactly the same as in that previous demo. We run the Vault server, enable the AppRole authentication method, run the Agent. And then after running the Agent, we make a request to the Agent to create a token. And then we create the same request.
We make the same request in quick succession, 2, 3 times. And make sure that the response received is always the same.
It's the same script. Hits the Vault server, starts the Vault server, enables the AppRole authentication, reads out the SecretID and the RoleID. But I have given the TTL as 5 minutes in this case, instead of 3 seconds. Dumps the RoleID and SecretID to files. This is the exact same configuration that we saw for Auto-Auth.
These are the 2 things enabling the caching feature. Cache block lets the Agent know to run in the cache mode. Use_auto_auth_token = true can be set in this one. And then this is the listener that we are defining. Similar to how Vault server does it. Mention an address where it needs to run, and the port number. And then start the Agent.
After starting the Agent, we are fetching a different RoleID and a SecretID. The RoleID and SecretID mentioned above are for the Auto-Auth. This is an explicit request being made to the Agent. That is enabled by VAULTAGENTADDR. We are pointing to 8007, which is the port where Agent is running.
Then we make 3 consecutive login requests. Let's run this script and see how it works.
We just ran the script. The script has run successfully. Agent is running. And in the Agent we see that Auto-Auth was successful. And then cache received a request to create a SecretID, and then it received a request to create the RoleID. Responses will not be cached in this case. And then it received 3 consecutive login requests.
In the response, the output of this script, we can see that for all these 3 login requests, the token received is the same. So that's Agent caching in action.
Recap
We looked at what Secure Introduction problem is: How do all the applications initially establish their identity and interact with Vault? You get a Vault token. And how it is a problem when things are at scale.
And we saw what Vault Agent is. Why did it come into existence? And what Auto-Auth feature does to solve the problem of Secure Introduction.
And then we discussed the problem of how misconfigured clients can potentially overload Vault with too many unnecessary requests. And how Agent caching is meant to solve that.
I really hope that people transition to use Agent, and ensure the workflows in services never see a Vault token.
The demos and the scripts that you saw are pushed to this link. All it needs is a Vault binary to be stuck there. And then you can run it and see exactly what we ran.
The one difference and the catch is that the Agent works with some of the response tags for the token creation, which initially was not present. It was introduced in Vault 1.1. So it's best if people use Vault 1.1 and above to run these scripts. And generally use Vault Agent in caching mode.
Thank you.