What are the best practices for preventing a data breach?
Your network will be breached, and any plaintext secrets will be exploited. Assume this, and you'll start adopting practices that greatly mitigate the damage from a breach.
Speakers
 Armon DadgarCo-founder & CTO, HashiCorp
Armon DadgarCo-founder & CTO, HashiCorp

Transcript
The way we think about this problem is: How do we change our thinking from traditionally one of, how do we avoid one from ever happening? This is the standard castle-and-moat approach to security, where we build and focus on a network perimeter and assert that an attacker never gets in and that an insider is never a threat.
Instead, let's change our mentality to saying, "We assume that our network will be breached, or has been breached, and that insiders are threats to us." The moment we make that assumption, then we change a bunch of things about our security.
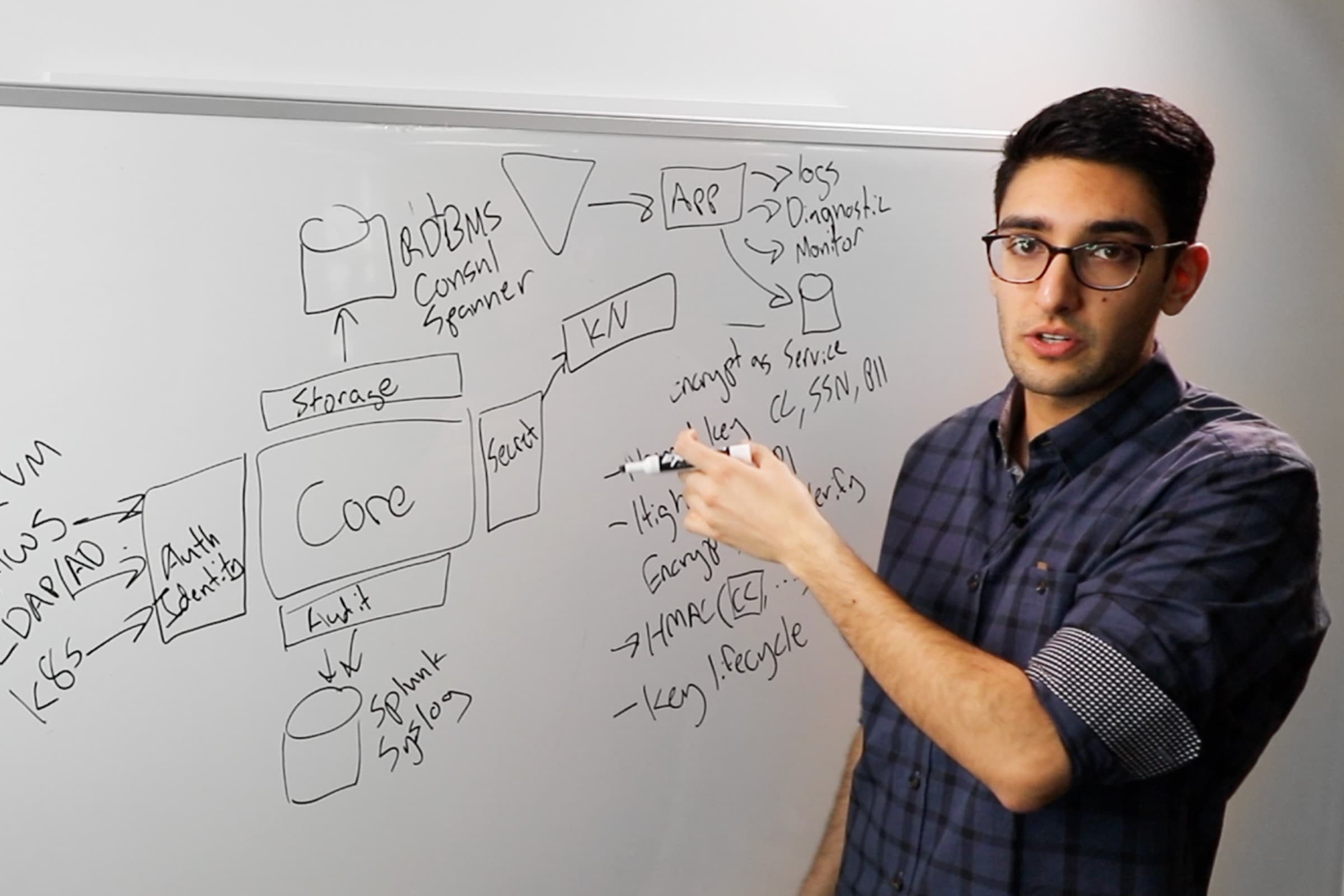
A few of those things include: 1. actively doing secret management: How do we move from having secrets in plaintext, littered and sprawled across our infrastructure, to being centrally managed and controlled? 2. We do service-based segmentation: How do we restrict which services are allowed to talk to which services? It's not enough just to be on our high-trust network, because an insider who might be attacking us could be on that network, or our network could be breached. 3. Lastly, how do we encrypt data in transit and at rest? Historically we said, "By virtue of our database being inside of our network, we don't need to encrypt data that we're storing, because we trust everyone who's able to talk to the database."
It turns out, when you look at these very public breaches, what you see is both of these things are about assumptions. Your perimeter can and will be breached, and insiders will be threats. So, once we think about those things, if we implement these other controls, we can dramatically mitigate the impact of a breach.
If someone, for example, is able to get onto our network, but we're doing these other things—we're doing service segmentation, we're doing secret management, we're encrypting our data at rest—then an attacker can't actually even connect to any of our systems. They're not authorized to connect to the database, and even if they could connect to the database, they don't have the database username and password, so they can't authenticate or authorize their access.
Now let's go even further and suppose that through a leak of credentials, or through an insider attack, they are able to get those credentials, they can connect to our database and they can read data out of it. If we're actually doing data encryption and protecting our data at rest, then what an attacker now has is a bunch of encrypted data. So now they have to go even further and compromise our key management systems or be able to do an online attack to decrypt that data, which is much more obvious to us that this is taking place.
How we start to minimize our exposure and risk is to change our assumption. We have to assume that we will be compromised, and then what are the controls we would implement in that situation, as opposed to designing an architecture that's designed to never be breached?
Because when it's breached we've violated the assumption that we built everything around.