A Tale of Application Development for the HashiCorp Stack
Learn how a non-developer was able to write a Ruby app using a tool built with the HashiCorp stack.
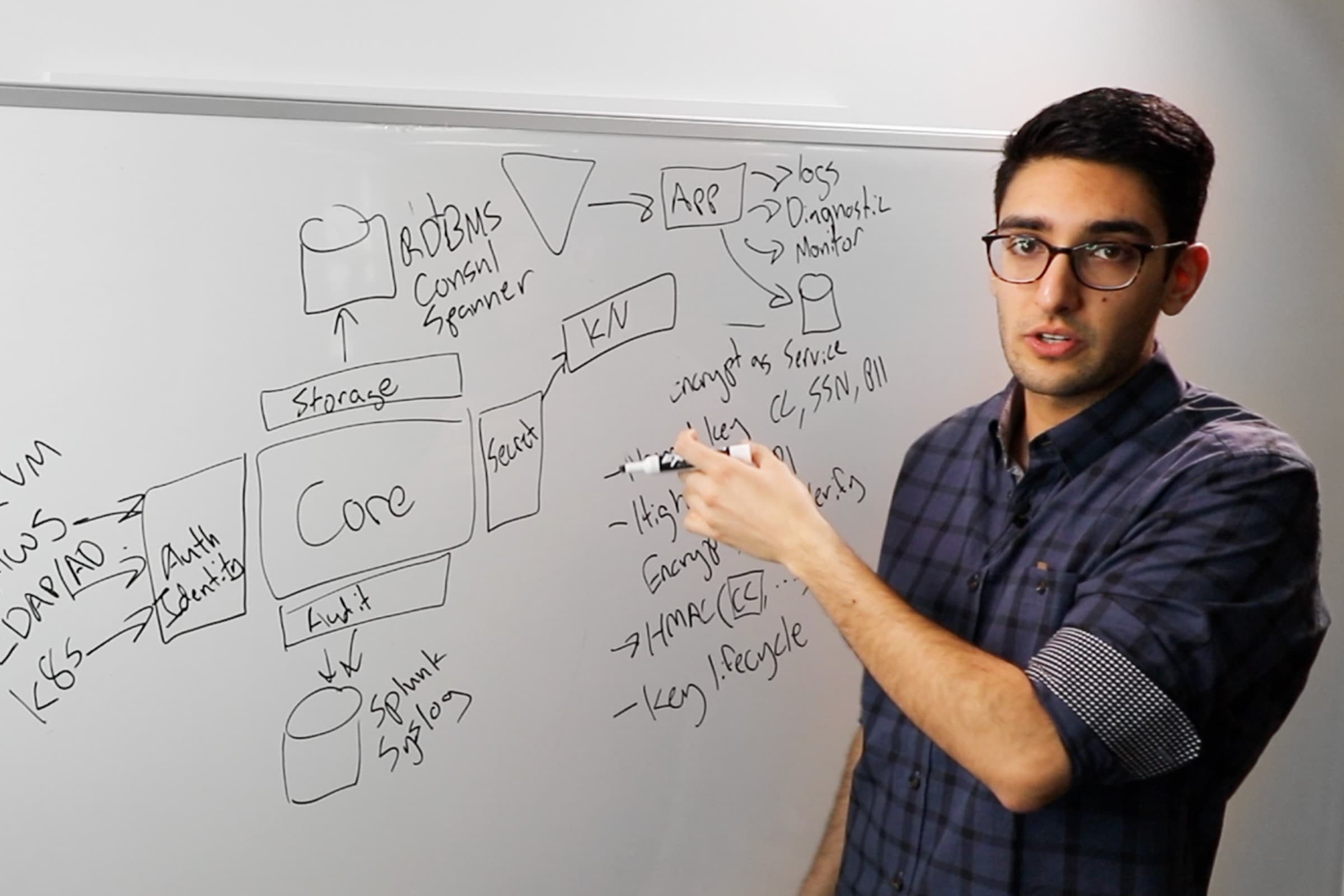
A year ago, Nicolas Corrarello set out on the journey of building an internal application for his team that was cloud agnostic, secure, low-maintenance, and portable.
Using just Packer, Terraform, Consul, Vault, and Nomad, a non-developer was able to write a Ruby application without any operational expertise. This app is maintained by a globally distributed team.
This talk will give you several best patterns with which to deploy Vault, Consul, and Nomad, and it will also help you handle:
- Secrets management
- Encryption in transit
- Complexity around immutable infrastructure and state
- Patterns for abstracting from databases
- Reusing existing elements to save time
Speakers
 Nicolas CorrarelloRegional Director, Solutions Engineering, HashiCorp
Nicolas CorrarelloRegional Director, Solutions Engineering, HashiCorp

Transcript
Everyone slept well? I'm seriously asking. See, I have a four-year-old son and a six-year-old startup I need to worry about so there is not much sleep going on for me. Anyway, this is me. I really don't quite get why people put pictures of themselves in their slides. This is me, 365 days ago and ten kilos ago, quite proud of that.
The gentleman on the left actually, funny enough is called Dan Brown. If you see him with the same shirt, just so you know he has like three of them. Don't worry. I know he consistently washes them.
Getting a little bit serious: I've been working at HashiCorp for about two years, though you may not see me a lot because I'm actually on the other side of the ocean. I'm here, can you see Wally? That's basically where I am, a little bit zoom there. That's actually where I live.
Now in a world of privacy and so on, not a lot of people would feel comfortable doing that. I actually do, and here's why. I don't live in ten acres, as you can see all the gray. I actually live in a new neighborhood. No one can find my address because neither Google or Apple have updated their maps, so let me know if ... if Amazon Prime can't find me, I'm pretty sure you guys can't. The whole excuse of this talk, to be absolutely serious is there anyone from Google or Apple in the room? Can you please, please draw my street. I want to get mail. It's fine.
All right, a little bit of a disclaimer: I'm Argentinian by birth and Italian by blood so you will see me do a lot of this. We kind of talk with hands. It's pretty common, that's why they gave me the big room. They don't want me hitting anyone. English is not my first language, so if there is anything you don't understand I'll do my best to repeat myself. If you look puzzled I know that I switched languages. I am not a developer at all. I actually come from an Ops background—you know, worked at Red Hat, IBM—so I don't do coding for a living. I mostly do coding to annoy people. Mostly our Vault developers.
If you see Chris, one of our Vault developers, hell explain what I'm talking about. This morning he told me, stop sending commits.
Please don't criticize my language choices on some of the examples I'm going to show you, I had basically a week in Christmas to do this. I didn't finish. We have new people still asking, "Wouldn't it be cool to have an app that does this," and everyone laughs. I go like, "Well we're like three months away from Christmas so who knows, I might finish it." The same thing I'm going to show you, you can do in a plethora of languages. We have libraries for almost any common languages, even ones I haven't heard about.
What's the story?
Lets talk about the story. My organization is called Solutions Engineering, and we sometimes have to prepare these special documents for customers, which is pretty much a copy and paste process. For the longest time we were like, "Wouldn't it be cool to actually have a tool that does that for us?" That basically takes the template, rendering values and then creates a neat PDF that we can send to customers so we can explain what we are doing with them.
As usual, we're not a team of developers. We don't have time to write this. We don't have time to maintain this, so lets make a tool that does it, and make it as zero-touch as possible, but at the same time we want to use all the new and funky development practices. We actually want to make an app that is based on microservices that talk to each other or is containerized. All the neat, little buzzwords that you hear day in and day out.
When I set myself to start this project, I started thinking about the advice I generally give to people using HashiCorp tools and see how that actually applied to me. To start I'm going to talk about two things that are not development specific, or not even HashiCorp specific, but are really important.
Contracts
The first one is contracts, and it's not the ones that the suits prepare. It's the internal contracts you have in your own organization.
When you're about to consume a service from your organization, you need to at least understand where do you start. With our tools in particular it's quite important because for example if you're consuming a secret from Vault, you need to understand where is my starting point? Do I have a Vault token available in my EC2 instance, or my VM? Do I need to do that log in process? Those kind of contracts need to be set in advance. Whoever is running the capability for you, and even if you're running it small in your own team, you need to set a starting point in terms of from where am I going to start to continue this workflow?
First thing, read carefully, agree your contract within your organization. Understand this is what I expect. When I get a resource, when I get a VM, when I deploy a pod, I am going to have these things available to me to actually go ahead and consume anything further. Now it might be the case if you're a small enough organization or you're lean enough that you actually have your vault ready, and we're ten so this is not a problem. This will become a problem in the future when you're over ten, so start thinking about these things now. We're going to go back to these contracts a couple of times during this presentation to talk about a couple of things you need to be aware before you start any kind of development process.
Abstractions
The second important thing I want to talk about is abstractions, which is one of the coolest things that you can have when you develop. I'm serious. I'm not particularly a Java guy, but this is seriously the best thing to come out of Java. The fact that you can use in-language abstractions in code. Even when you write your own abstractions, the first thing you want is you want your code to be readable, you want other people to be able to use it. And particularly in my case, I was writing an application that people in my team were potentially going to maintain, but I need to make it really easy for them. Abstract your code from locking every single time you can, because these are the things that come back to bite you.
Use existing libraries whenever possible. Just be aware that some libraries may be a little bit opinionated in the way you do things. I actually had this discussion in HashiCorp a couple of times. Particularly about Rails. Rails is great to develop a web app, but ultimately it kind of locks you into a particular pattern. It makes assumptions. If you're using Rails, and if you're using for example Session Management, we assume that we have a SQL persistence, right? If you're using Rails, you must have a Pulse or SQL, or a MySQL, or whatever. Honestly, my application wasn't that complex. I didn't want to do that.
Even then, I wanted to abstract from the storage layer so actually I wrote ten lines of code that does that for me. I basically created a persistence abstraction that in this case is just storing stuff in a tree. I created three functions. I created a store-retrieval list because that's all I need from my storage backend, and I'm going to be writing JSON documents and in the future this might be big enough where I need to move it to Mongo, for example. I don't want to go back to my code and review every single part of my code to see where I'm doing it right, so basically I just invest 15 minutes in writing a library that does that for me. Which is quite specific to my application but ultimately if I want to migrate my application from, in this case S3 to any other object store, I can just modify those ten lines and that's it. My application keeps working, I don't have to change any more code.
Talking about this application, let me tell you a little bit about the assumptions I had. My team maintains the Vault and Consul capability because we use it for demos and we use it to try things. I had basically everything that was available in an AWS so I knew I could persist up in S3, and I also have Nomad as a scheduler so basically I had almost all the underpinnings I need in terms of infrastructure, so the only thing I needed to write, and the only thing I actually wanted to write is a little bit of business logic that did whatever I needed.
Secrets
From there on I started looking at basically how am I actually going to code this. As you can imagine, the first problem that I got through is basically secrets. Ironically, secrets management seems to be the thing on everyone's mouth. We keep talking about secrets, and in my case I had to manage a considerable number of secrets. So I had AWS credentials to actually deploy this. I had AWS credentials to access the S3 bucket. I had JWT signer and issuer. I had the Google API credentials because honestly the most common login method we have is Google, so ultimately I need to store some way to talk to the Google API in terms of doing logins and so on, and I needed crypto. I might be storing some sensitive data, and even if I'm not I actually want my information to be encrypted.
When I talk about crypto, and I know I'm in Silicon Valley, I want to clarify what I mean by crypto. I mean the art of writing or solving codes. This has nothing to do with crypto-currency. I need the capability to actually encrypt information in transit. Traditionally in the data center crypto has been limited to this. Look, if you have storage you go, you tick your box, and all your information is just encrypted at rest. This is what regulatory requirements ask us. Your information must be encrypted at rest.
Now, I tend to say the same thing. Do you know what protects your information at rest better than cryptography? Take a guess. It's actually this guy. He looks really tough. Lets say a curious individual that Hollywood has portrayed as a hacker, wants to take your data. He's not going to go and your physical security to try to get it. This is stock photo by the way, I don't know this guy. He's not going to try to go to a data center and steal a hard drive. What he's actually going to try to do is most likely either try to find a way to the logic of her application, or if it is a disgruntled employee, an internal attacker, before they leave they are going to just do a SQL dump and just take it with you.
The most common scenario is you end up in something like this, which is pretty common. You got a SQL injection, you have an unescaped string in your code and basically someone puts ; SELECT * FROM table and boom, all your data is out. The clear way to address this is actually not having some sort of transparent encryption; it's actually do an encryption in your application, which has other kinds of complexities. For example, where am I going to put my crypto material? If you read, there is a blog in the UK called The Register, which is basically IT news. Basically, they have a posting every week for some encryption keys that were leaked because someone left an S3 bucket open.
People don't know and have a problem actually managing that crypto material, and that's problem #1. Problem #2 is that probably your cryptographic functions need to be audited to ensure you're doing it right. Now, funny enough Vault actually provides you with a capability to do this and it's pretty easy to set up. As I suck at doing live demos, I actually did a GIF. You can actually send this to whoever manages your vault, but ultimately Vault has this thing called the transit engine where you just provision encryption keys, and what you're going to do is quite simple. It brings you two end points, an encrypt and decrypt endpoint.
Basically, the standard of security is already set by someone managing your Vault. Your keys are stored in Vault. They never need to go there. What you just do is through the API send a value, and get an encrypted value back. That's basically all you need. In my application as you can imagine, I just do that. I basically, before writing something, I just translate it to Vault. And this is the way I should do it, right?
Yes? Why are you not paying attention? Abstractions! I don't want to lock myself into Vault, so basically I created a function in my application for my code, so if tomorrow I want to go from Vault ... Well, I work for HashiCorp, so please don't go away from Vault. But if you want to go away from Vault and go into KMS or KeyVault, or maybe you are using KMS and you actually don't want to lock yourself into AWS, well this is what you do. Just put a little bit of code that abstracts you.
Basically, if you change crypto capability, you change one bit of your code, not your whole code. I did a lot of those, so basically this is my Vault object in code, and when I need basically to encrypt or decrypt values, I just call vault.encrypt or vault.dencrypt. Easy to read, easy to maintain, easy to move away from Vault. If I need my Google credentials, I use a specific path. If I need my JWT secrets, I use a specific path, and so on.
The next aspect—lets go back to the contract for a second—is how is this application getting access to Vault? If you have used Vault or you have used Consul you know that we need to identify whatever is consuming that capability in order to basically give them access to crypto, give them access to secrets and so on. Before I give you a secret I have to know who you are. In my case, my runtime was Nomad so in Nomad it's actually pretty simple. You just tell it what secret it needs or under what policy it's going to be.
In my case, I'm consuming a couple of things from the application. For example, a memcache layer. The beauty about Consul and service discovery is that we even had the indecency of putting a DNS interface into it. I don't need to even go to the Consul API and check where is this service, I can just pass a DNS name, which is basically what your application is doing right now.
What if I'm using K8s?
I understand that not everyone is using Nomad. I know there is another popular kid on the block, whatever my personal opinion is on that. What if I'm using Kubernetes? Well, I know if you heard Armon yesterday but we solved 40 script problems, so we don't care how you solve maybe the other three. If you're using Kubernetes, a good option is just using the Kubernetes self indication method. When your container comes up, you just go and do a secure introduction of that container via a method that is already available, and that container gets a token.
If you want something a little bit less invasive, maybe what you can do is basically use something that we have called Consul Template, which I'm going to go in depth a little bit later, to deploy helm chart with secrets. Or there is another option which actually Nick, who I think you all saw, he basically has this pattern where he has this helm chart that basically runs the container as a sidecar with Consul Template, and then mounts the following secrets. So basically the secrets are given into the pod without the need of modifying anything in your pod so it's quite a cool pattern.
It varies in something like AWS you can also have that AWS EC2 instance do login, same with Asher, same with Google, same with Ali Cloud, ultimately. We have multiple authentication methods in order to find out who you are and what kind of secret I can get you. The beauty of this is if you're using Vault, once I identify you I can get you all kinds of secrets. I can get you your Consul Token, I can to get your Nomad Token, I can get to Database Credentials. That's it, secret problem over.
Perfect > good enough
There is one interesting engineering point that I want to make. The thing about vault is that it gives you credentials and you can have a very short TTL, lets say eight hours. You fall very quickly in the trap of saying, "I'm going to just every eight hours ask for new credentials." It requires a lot of logic that I'm not sure I actually want to make the investment in your application to go and say, "I'm going to go and rotate my secrets every eight hours", because every time I do a presentation on Vault I ask people to raise hands; How many rotate their machine credentials every year? Maybe 10% raise their hand. If you want to go from like every n to eight hours, I think that's too steep. It will add a considerable amount of effort in your application development.
Just to show you an example, this is what I'm doing in my application basically. I'm just checking if my credentials work, and if they don't work I just get a new set of credentials and try to connect again. It's pretty simple. And the second pattern you see on your right: I actually wrote that for my HashiCorp job interview a while ago. Its still a lot of code that you actually have to maintain. The most I would say amicable pattern I've been suggesting is like if you deploy your application every 30 days, just make your vault tokens last 45. By the time you reemploy, you get new credentials and the old credentials just expire. Just make it easy on you to maintain moving forwards.
Another interesting aspect of this is for people that are not developers, like myself. There are a lot of organizations that still work—I'm not going to say a full waterfall model, but basically they have a team that write an application and they chuck it over the fence to Ops, and then Ops has to go and deploy it and handle configuration, and handle secrets, and so on. They don't actually have access to modify the application, to have it consume credentials from Vault. A good example of something you can do is use Consul-template which is this binary that takes configuration from Consul and takes secrets from Vault and just renders a configuration file template, which is basically what your application has been doing so far. There is an excellent guide that a member of my team wrote who is in Paris about how to do that with PKI.
Basically Apache or NGINX is a great example of things that you cannot modify to load certificates. Basically what he does with Consul Template is he renders the key, the certificate, and the CA on predictable patterns and as Consul Template is talking to Vault, every time that certificate expires it's going to render a new set of certificates and restart Apache or NGINX. That is completely friction-less. The other alternative generally when you're using applications is that you pass secrets or configurations through environment variables. We have Envconsul which is a similar pattern but basically uses environment variables.
Enough with secrets, please.
Locking
Some more interesting aspects is for example locking. These are locks in France actually. There is a large canal where you actually have to go through locks to get to a canal. In this case locks are very important to avoid ships crashing into each other. In application development it's actually quite similar.
In my case remember, in my application we were writing documents and those documents take a bit of time and you may need to collaborate. I need to find a way to—if someone was writing or modifying a document for someone else not to go put a quick change, save it and then get overwritten and so on. And Consul is actually perfect for doing that.
Quick example here, you can basically set a lock in Consul. Diplomat is the name of the Ruby gem that interfaces with Consul. Again, there are others. Basically you can put a lock in Consul, and in my case I patch when someone opened a document for updating, I basically added a line in the code that said just go and lock this registry. When someone goes to do another update, it's basically going to do the same thing. It's going to basically wait for a lock.
So basically the browser is going to go wait until it times out because the web service is not going to respond. It's not a great pattern, but then again I had a week to write it. Ultimately you can use these locks, and if someone forgets this, these locks expire every once in a while. Ultimately you can do a finer-grained management of those locks.
Load balancing
Another interesting pattern is about load balancing. I have to load balance multiple instances of my application which are coming out in multiple systems.
If you haven't heard about Favio, Favio is just awesome. It's this binary. It's being used by eBay that I know of. The guy that wrote it is actually in the Netherlands. He's German. He's a fantastic guy. Basically it takes whatever you have in Consul in terms of service registration, and load balances. It's absolutely fantastic. It's not the only great pattern. Armon in particularly is in love with this pattern. That went up for the European banks is doing, but they are doing basically the same thing with NGINX.
They have NGINX but basically every time there is a new service, Consul-template just re-renders the NGINX configuration file and does a restart. It's actually pretty cool. Consul on its own is like a great Swiss Army knife tool of things you can use. You may have heard of Consul at Service Discovery, or the Key-Value, or you're seeing Connect now which is awesome but it has some things that not all people are aware of.
Not used in this project but really cool
The K/V store, or doing block inquiries. Basically I have my application, I read a value, and Consul is going to leave the connection open until that value changes and then it's going to drop the connection. So basically by … generating a new connection I get a new value. Really cool stuff. Prepare queries which is basically, you can use it for great patterns like geo failover. You can do leader election with Consul. There are lots of things in Consul that you can use to make your life easier when developing an application.
Don't do this at home
About halfway to writing this we had RCI, but we didn't have an artifact registry so we were using the Docker hub to build the container. Please, really don't do this at home, but within the application what I basically did is whenever you see a web hook from the Docker hub, basically I'm going to redeploy the whole thing. I'm going to render the template of a Nomad job. Cool thing is the application actually can get Nomad credentials through its own deployment. It's not a great pattern—don't do this at home.
What was accomplished?
Where I got after 15 days of coding is that basically I had 100% of code that was business code. I wasn't trusting that anything would provide me any kind of resiliency or any kind of security.
The data's encrypted—at rest and in transit—in JSON documents that I just load and decrypt when I need to. If someone for some reason made my history bucket public, they will just see gibberish because the data is decrypted by the application through Vault.
All credentials are ephemeral or short-lived, so even if I disclosed an error on a log or an error message, basically I can go on and just revoke them.
I had microservices that are loosely coupled and they can talk to each other via Consul.
I could run this wherever. Which was one of the main things, because right now I had an AWS account but tomorrow, we may want to focus on doing stuff on Azure. I can just move it around.
What's next?
Some more interesting stuff that I've been thinking before next Christmas so that I can start writing, is that I already have a scheduler running, which is Nomad. There are certain processes that I'm doing kind of interactively in the code, like generating a PDF. That takes a long time and it's a dreadful experience and it's worth noting—did I mention that I have a scheduler? Basically, that PDF process, I can just throw a task to the scheduler to generate it offline, and leave it somewhere predictable when it's done. That's the beauty of using a scheduler in general. There are a lot of things that generally in your application you're doing in an interactive way and you can start thinking about splitting those because access to the scheduler is via API. Ultimately if there are certain tasks that are not worth doing interactively, don't do them interactively. Just throw another job to the scheduler, get it to run and then load it either asynchronously or in a predictable manner.
The other aspect was just the sheer amount of configuration that I had to do in terms of doing mutual TLS, and even for kind of commercial off-the-shelf services like Memcache. Even if most of my data was encrypted in transit, I still wanted to use TLS. So I have Vault generating all these certificates, and I seriously want to stop that nightmare. You know, again we launch Connect in May in Amsterdam, and I already have Consul there so basically he only thing I need to do is start using the proxies, and hopefully that will make my life better and I don't have to maintain so many certificates.
I really, really hope these patterns were useful to you. I'm going to be roaming around the conference if you have any questions. I honestly want to help.
Thank you for listening to me ramble for about 40 minutes, and with that, thank you very much.