Accelerating BT's migration from on-prem to cloud with HashiCorp
See how BT Group turned a 1-3 day deployment process into a 10 minute process with Nomad, Terraform, Consul, and Vault.
»Transcript
My name's Tom; I'm a principal engineer at BT. I started my career at BT, spent around six years there, and then left to go and work at some smaller — probably not small anymore —companies to get more of a startup-type experience. Then around about a year ago, for some reason, I thoughtI'll go back to giant enterprise; that seems like a good idea.
»BT Group
We’re based in London, I think I probably don't need to introduce us too much. But we're a multinational telco. We employ over 100,000 people worldwide. Probably best known here in the UK for our consumer brands , BT, EE, Plusnet, and Openreach, with Openreach doing the last mile connectivity for the majority of the UK's big ISPs.
»BTTV
A lot of people don't know that BT has a TV service, but we do. It started in 2006, and it's delivered over your broadband lines. Instead of cable or satellite, you get your extra channels and your extra content over the internet.
We have around 1.9 million customers on the platform today, and our strategy these days is aggregating together all your content from places like Netflix, NowTV, Prime Video and grouping that together with all the usual stuff you get from a TV service. You get a box; you can watch all your free-to-air channels and record stuff and all that stuff.
»How did this project come about?
About two months after rejoining BT, our engineers got this ask from our team: We're closing our primary TV datacenter at the end of the year. So, we need to move everything that's there and put it somewhere else within a year — which is a nice fun challenge. But it also gives us a good opportunity to look at how we're doing those deployments and see if there are any improvements we can make to that process as part of this task.
»Where were our applications located?
Let's look at where applications are pre-closure — so where they are all the way back in time a year ago. The majority of our stuff is running on-prem — probably no surprise, large enterprise, especially back in 2006. Putting stuff in our own datacenters makes perfect sense. We've got a lot of applications running in VMware, on-prem — and today we still do. We still have a lot of Java applications and a lot of compute-heavy things like databases and message queues. They're all still running on-prem.
We started to move a little bit into containerization. We had an on-prem Docker Swarm cluster. It was on-prem, soe didn't have any fancy autoscale or anything like that; still quite a bit of manual process involved to get something on there. But it was definitely a step in the right direction. Our teams were enjoying this a lot more than the old-fashioned wait a long time to get to the end result, but we definitely saw what to do.
In TV, we have some applications running in AWS — actually not that many. They tend to be AWS-native services — a lot of serverless, a lot of Lambda and DynamoDB, things like that. Which is great for those teams, but a lot of our existing applications are big enterprise-type apps. They don't translate very nicely to running in that sort of environment — so there's not that much adoption.
We don't have a super specific thing from 1994, but I wanted to stress that because this is the datacenter migration, we had to move absolutely everything. That includes all the stuff that was put there 15 years ago as a temporary fix and is now still there 20 years later.
»Pre-closure deployment requirements
Well, unsurprisingly, it's a lot of Jira tickets — a lot of different teams involved. So, if we walk through the different stages that would be involved for them to migrate their app to another VM running on-prem somewhere.
»Create a VM
First, they need to get that VM created. They're asking our infrastructure team, please, can you provision this server? I want this much hard disk space, this much RAM — all that stuff. They raise a ticket for that, it gets picked up, and then some number of days later, a VM appears.
»Configure the VM
If it needs Java installing that needs to be done. That will most likely be another ticket out to that team to go and configure it.
»Create Firewall Rules
Then our service is going to want to talk to other stuff. It'd be very rare that we deploy a server and have it nice, isolated on its own. So we need to create some firewall rules. The complexity here is that our engineering teams are thinking in terms of service A, talking to service B. But when they request our networking team to do this work, they need to translate that into 10.101 dot whatever the IP address is.
Because they're not provisioning the infrastructure, a lot of the time they don't know those IP addresses. They have to go find them out from some wiki somewhere or some central system. So,there's a lot of opportunity for this to go wrong or not include all the rules they need.
»Create DNS records and configure load balancers
Once they've been provisioned, we're onto DNS records. Another request out to our infrastructure team to provision those. Very similar with load balancing. Maybe we've got someone on the team that can handle our load balancing for us, but we need to wait for them to be available. Or if there's some complex rule — or maybe multi-site load balancing — we might have to wait for our infrastructure team to be free to provision that for us.
»Create application config
Then it comes to stuff our teams can control — so, that's application configuration. This is a lot better experience for the teams. They can maybe do this with Ansible; they can write a config file or some other solution. However, there's still a lot of boilerplate stuff they need to think about. If they've got secrets they need to get onto that VM, they need to think about how they're going to do that.
If they need AWS credentials, they need those to be rotated. Maybe they run a Cron Job, or they have some Ansible script that does it for them. But they need to think about all the low-level details of how they do that as opposed to writing stuff for their application that solves the problem they're actually thinking about.
»Arrange a change slot
With all that in place, it comes to the time to arrange a change slot. We need to go to our operations team and say we've got this new production system we're going to deploy. Please, can we deploy it?
But because of all that previous complexity, they're really risk averse. There's quite a lot of chance we've made an error there. Especially because the team that provisioned our test infrastructure might be completely different to the team provisioning production. So, a lot of hesitancy around allowing us to do this, which means we end up with scheduled deployments that are out of hours, batching up a lot of work. It's not a nice experience for anyone to go through.
»Deploy
Once we have all that, we can do a deployment and get our application out there. As you can see, this maybe works day-to-day if we're not shipping that much stuff/ But taking a hundred different applications and trying to run through this process is not something that is going to scale for us.
There were some attempts to try and automate this Jira workflow. I suggest we don't do this, though. As you can see, you get a nice little picture out of it. But underneath it all, the complexity's still there, and there's still a lot of handovers and a lot of risk for things to go wrong.
»The Solution
So what did we do then? Well, we decided to build a new platform to abstract away a lot of the complexity for our engineering teams. We didn't have a mandate to say, you must use this new platform. So, we had to think about it a bit differently.
We're treating our platform as a product — as though it was any other consumer product for our engineers. And we're trying to make it the best place for them to choose to move their app to. If they wanted to, they could still go on-prem, but we want this platform to be clearly the best thing — it's going to save me a bunch of time and make it easy for me to work with.
As a quick shout-out, there's a good Spotify podcast episode on how they did this. They had their own internal marketing team market their own engineers to say please use our platform. That's well worth a listen if you get a chance afterward.
»Assembling the platform
Let's go back to BT, and think about how we address all those needs we just walked through. We'll go through the same stages and see how we can map that to pieces of our platform that can help solve those issues.
»Create and configure the VM
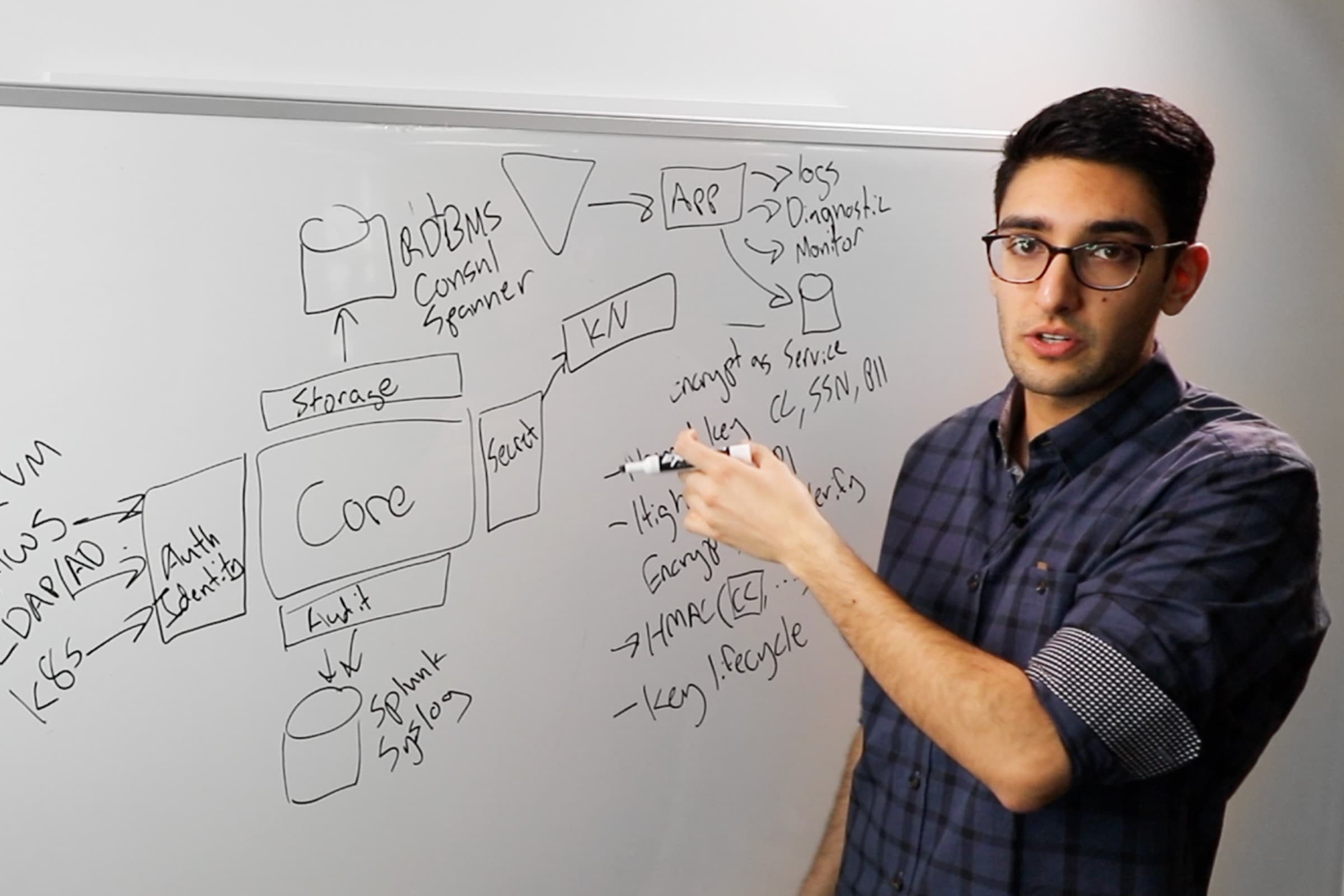
First is creating and configuring that VM. Containerization solves a part of that problem for us, but we still need somewhere to put those containers once we've got them. We selected HashiCorp Nomad to do that for us.
We went with Nomad as we only had a year to do this in. We wanted something that was super straightforward and simple for us to get up and running. With Nomad, we can take one binary, put it on a bunch of servers, and we have a cluster up and running pretty quickly.
We could have gone with Kubernetes, but we didn't have any Kubernetes experts in the team. We weren't planning on hiring someone in less than a year to do that for us, so Nomad is a great alternative. As a migration, we had some things that maybe wouldn't necessarily fit into a container. So, having Nomad with the ability to run things that aren't containers — maybe IS services or a raw JAR file or something — gave us that flexibility to fall back on if we needed to.
»Create firewall rules.
The underlying need here is I want my application to talk to another application securely. We went with Consul here. We can register all our services in Consul, have them discoverable. But also, we can use Consul service mesh to abstract away all that firewall complexity.
Our teams can define those relationships in a language they're used to. They can say service A should talk to service B, and we can have Consul intentions provisioned in the cluster that make that work for us.
»Create DNS records and provision load balancers
Similar with DNS records, this is a day-to-day infrastructure provisioning task. We shouldn't have to think about this. We can get Terraform to abstract a lot of this away for us, and we can use a convention. But maybe we say your service is name.bt.com by default, then you don't even have to know this is happening.
Very similar with load balancing. We can make a lot of this go away. We have all our services registered in Consul. We can use a Consul-aware load balancer like Traefik to discover all these services. If I have some metadata that says this should be accessible on the internet — or this should be accessible to our internal tools — Traefik can discover that and expose it as it needs to. No configuration of the load balancer needed. This helps if things are auto-scaling, moving around; that's all taken care of for us.
»Create application config
When it comes to application configuration, this is something we can't make go away. We need this to be as flexible as possible. Because we're doing this migration, we don't want teams to have to change the code of their applications. We want them to do whatever they were doing before just somewhere else.
Using Nomad here means we can render things in a number of ways. It could be environmental variables, a template that gets rendered, a volume that gets mounted. The team can take whatever they're doing on-prem and do it on Nomad.
But we can also automate away some of that boilerplate stuff they were previously doing. If they've got credentials, let's lean on Vault to handle those, pull them in, rotate them — pull in secrets we've got, and if they need to discover where other applications are running, let's lean on Consul to do that for them. They can really focus on just their application’s configuration and not — where's this thing? How do I get this secret? And we can use Terraform to glue all that together and make it nice and seamless for them.
»Arrange a change slot
This is still very people-and-process-driven, but we can say to our operations team, we've got this standardized platform now. We've got test. It's pretty much identical to production, our configuration's the same between all the environments, and if anything goes wrong, Nomad's going to roll that back for us. We can do canary deploys; the whole thing is automated.
As a result, there's much less risk that what we're doing is going to break production. We can have that conversation with them and say we have all this in place now. We are going to deploy as soon as we're done. If there's an issue, we'll roll back. You can see we've done it 10, 20, 100 times now. It's always going to be the same.
»Deploy
With that in place, everything else becomes a lot easier. We can do our deployments now; we can do all the good stuff we tell our engineers to be doing, like smaller deployments, more frequent deployments. That all becomes a lot easier because we have this automated process in place.
»Demonstration
This all sounds great, in theory. I'm now going to do a quick demo of how this works for our engineers. For this demo, we're going to pretend we are part of the Hello World engineering team. If you can't quite see the code, don't worry, you can get the gist of it.
We've got a service here that basically says hello to people. It talks to another API that we've got to pull in a greeting like Hello or Hi. We pass in a name — in this case, HashiDays — and the app returns Hello HashiDays.
It's also got a health check endpoint — just so we can verify everything's healthy and running. But let's say we've got this on-prem at the moment, and we want to migrate it to our new platform.
»Engineer documentation
Because we're treating this like any other consumer app, we've got some nice documentation that our engineers can go over to. There we go. They can look through our documentation, can see why they should use this new platform, and once they're convinced, they can click in and get an easy, quick start to how to onboard themselves.
There are only two things they're going to need to set up. One is a GitLab CI file. We use GitLab for our code repository and for build. They can pull in a pre-built pipeline into their project. This means they don't need to write any of that build code themselves, and they're always going to get the latest version of whatever our current best practice is.
Next, they’ll want to add a file called app.Waze. This is a bunch of HCL that describes their application. We're not going to writeany Terraform. We're going to describe how we want our app to work, and the platform is going to take care of setting all the stuff up we need.
We can come to our documentation. We can see all the different available options — and we've picked sensible, secure defaults for all the values. If you wanted to, you could deploy an app with an empty file, and you'd get a default app.
»Customization
But most likely, you’d want some level of customization, even if it's just environment variables or something like that. What’s nice about having all these defaulted values is if we decide to change them in the future, we can just update this. The next time a team deploys, they get the new secure default value.
But let's switch back to our application, and we'll set this up. We're going to add a count of one — we just want one HashiDays app. We're going to set our access type to public, which is going to add all the necessary metadata for Consul to say, yes, this should be public. Our load balancer will pick that up and expose it to the internet.
»Greeting service
We need to talk to this other service — this greeting service. We don't want to find out where that greeting service is running. We don't want to find the IP address available, the host name, or anything. We can use the service mesh to do that for us. But as an engineer, if I'm just migrating my application, I don't need to know about that service mesh. I don't need to know that internal stuff is happening.
In my app files here, I say, I want to connect to this upstream service. It's going to say ENV.base, which means we get the same config throughout each environment. In test, that'll be test, in production will be production. This file stays exactly the same. We've defined that now. When we do the deployment, which you'll see in a sec, all the Consul, behind-the-scenes stuff will get set up for us.
»Environmental variables
Finally, we need to add our environment variables so that our application knows that exists. Here you can see all we're saying is a reference to the upstream service. It pulls in the information. T
That could be Consul service mesh or something running on-prem. As a software engineer in this team, I don't need to know. All I'm defining is, talk to this service, and the platform is handling the rest for me.
Once I'm happy with this, I can do a commit, and we'll raise a merge request, and see how this gets deployed. Notice how we've not written any Terraform. We've not written any Nomad job specs. That's all going to be taken care of for us.
»The mail merge
Let's open this merge request. Once we open this, that GitLab CI template we pulled in is going to do all of the work for us. That includes onboarding us to the platform. There's no need for us to go to a central team and say, "Can I please deploy my application?"
We've spent all this time automating this away; we don't want to then put a manual gate in front of that and say you can't use this unless Tom approves it. That's what this first job is doing here.
The first time you deploy an application to this platform, we run a one-time bootstrap job. That's going to provision all the infrastructure we need for the rest of the pipeline to run. So, if you don't know GitLab, or the jobs in there, get a token that identifies which project they're running for.
In this case, it'll say, I'm the HashiDays project. That means we can authenticate with Vault. We can pull in credentials from Vault that allow us to deploy to Nomad, fetch secrets out of Vault, read Consul key-value storage — all that stuff.
»The bootstrap job
This bootstrap job here is going to say you’re running a project. I need to provision all the policies that support that in the various different tools we're using. That means we don't need to have GitLab open and able to deploy whatever it wants; you can only deploy your project. You can't accidentally deploy over the top of someone else by picking the same name; you can't read someone else's secrets by mistake; that's all handled and nice and secure for us.
If we ever update those policies in the future, this bootstrap job will rerun and apply the new policies, which means we don't need to ask teams to constantly update things themselves or switch to a newer version of a thing. The pipeline will take care of that for us. Additionally, this is nice because our teams are not having to wait at any point. If they want to onboard or off-board, they can do so.
Once this is run, we can switch back to our main pipeline, and we will see that the rest of the pipeline now has permission to carry on and do the deployment of the application.
»Pipeline overview
The rest of the pipeline looks fairly similar to what you are probably used to seeing. We've got a configure stage that sets a bunch of environment variables based on our conventions. All that’s saying you get a domain name; that's yourservice.bt.com. That'll all get set up for us there. Then we run our usual test and build stages. Here we're doing a security scan, but could be unit tests, integration tests, whatever we want to run.
But the most interesting stage here is this Nomad create default job stage. This is pulling in all of those variables we added to our Waze file and putting them into a templated Nomad job spec.
That's got all of our best practices baked into it; it's been approved by our security teams as a secure way to deploy your apps to Nomad. For me as a software engineer, I don't need to know how that works. I trust that I'm getting the latest secure version of that. If we ever upgrade it, the next deploy will use the newest, latest version.
»Infrastructure provisioning
Then we do some infrastructure provisioning. Terraform will provision all the infrastructure that individual deploy needs. Usually, this is just a domain name in Route 53, but because this is Terraform, we can actually use any Terraform provider at this stage. This big long lump of JSON that you can see here is a dashboard.
We use Dynatrace for observability. Whenever we do a deployment now, we can auto-provision a dashboard. If this is the first time you've ever deployed a service, you've instantly got some visibility into how that's working. Obviously, most likely, you’ll want to add or update your monitoring, but you get a default set level to go and look at for your service — and there you can see our Route 53 records getting provisioned as well.
»Deployment stage
With this in place, I can come over to my deployment stage, my final stage. Here we're going to apply that Terraform. It's going to provision all the infrastructure that the application needs, and then it’ll run a Nomad job. This is going to take our templated jobs spec, push it up to Nomad, and start running our application. Even though it's prerecorded, I always get slightly nervous that it’s not going to work, so let's see if it has. I think I'll refresh it. There we go, look, it's running. What a surprise.
It's running now. We can click into here, and we can see our one copy of our HashiDays application. We can go over to Consul. We can see we've got a HashiDays service that's healthy. If we click in there, we can see all the service mesh intentions have been provisioned for us. We've got our Traefik load balancer with an intention to talk to the review HashiDays app. We have our HashiDays app, and that has permission to talk to our greeting service. The nice thing about Consul is that we can also see all that connectivity; if there are any issues, we can debug from there.
If we switch over to Dynatrace, we should see there's a dashboard provisioned for our service; there it is. It won't have any data in at the moment because obviously, no requests have been made. But you can see instantly we've got the default monitoring that we'd want to see for that application.
With all of those things in place, we can go back to our merge request, and we've got a review deployment of our application in place. You can see everything's working. We've got our Hello HashiDays back, it's talked to that upstream service, fetched a greeting, and displaying it to our teams.
The nice thing about this is if you look at the URL, this is a review deployment. They haven't needed to deploy over the top of a test environment, deploy to production, or anything. They've just instantly got a one-time, unique, flat merge request deployment, and we can do that because it's all automated now. Cool.
»How did we get on?
This is running right now in production and has been since February this year. So, if you're a BTTV customer, it's very likely you've hit one or many of these services as a result of just browsing around the interface. It's a bit Apple-esque, this graph because I appreciate it doesn't have an access on the one side. But this is millions of requests we're handling through this new platform — and largely without any major incidents.
If I look at the statistics for the platform, we've got 279 services registered in Consul. We actually include our on-prem services in there. You get that same experience of defining your application regardless of if you're talking to something else in Nomad, something on-prem, or something in AWS. As an engineer, I get that same experience, and everything works together nicely.
We've got 179 Nomad jobs running across our test and production environments and we have successfully closed that primary datacenter. Thanks — I want to say not only to this platform — but a huge number of teams involved in that migration effort, so that was really good.
»Reduced time to deploy
If we look at the reductions we've made, that deployment process outlined at the start is quite easily over two days to get all that provisioned if you need that VM. A lot of waiting around, a lot of handovers — especially if other teams are busy, you can see that maybe slipping even beyond those two days. Now as we've seen, you can take your application, migrate it, and have it up and running in around 10 minutes.
»Fewer teams involved
In terms of team complexity and process reductions, in that previous deployment process, we're looking at at least three teams involved. I've got my own software engineering team, an infrastructure team, a networks team, and maybe change management involved. Now, if I'm suitably empowered to do so as one person, I can take my application, deploy it all the way through to production. Most likely, I'm going to have a review process in there, I would hope. But you can do that if you have all the approvals in place.
»Why has this worked for us?
»Developer experience
Is there anything you take away if you're planning on doing something similar? I think the focus on developer experience has helped to onboard teams as they're migrating and give this platform longevity.
A lot of the time, you see new platforms come along — especially in a time crunch — people onboard there, and then it's instantly a legacy platform that you want to get rid of. With this platform, we've seen that the migration is completed, and still, more teams are wanting to onboard because they want that nice experience. They don't want to worry about all the infrastructure side of things. They just want to focus on shipping their application. It’s nice to see that the platform continues to be a good investment for us over time.
»Secure and sensible defaults.
Our teams don't need to worry about all that boilerplate stuff; they can focus on, this is my application, this is the problem we're trying to solve, how do I solve that in the best way?
»Focus on majority use cases first
We have a lot of Java applications, a lot of HTTP APIs in those Java applications. When we're building this, we focused first on onboarding those applications. That meant we could continue to treat it like a consumer app. We could say to all these teams, please try and use this platform as early as possible. If they have any issues, we can tweak that and refine it rather than waiting a long time.
Sometimes you see platforms. They come along; they cater for every possible imaginable use case. Then teams try it and start to use them and actually, oh, this is awkward, or this doesn't work for us. Focusing on that majority use case first, we could get stuff tested, refine it, and end up with a much nicer platform as a result.
That's it from me. Thank you very much for listening. If you have any questions, please come and find me afterwards. I'm happy to chat more. But if not, enjoy the rest of the day.