

As the adoption of your HashiCorp Vault cluster grows in scope and complexity, it's natural to adapt and plan to support multiple tenants so you can centralize, scale, and standardize your organization's secrets lifecycle. To address this requirement, several years ago Vault 0.11 introduced the concept of namespaces, which has continued to evolve over time.
However, the benefits of using namespaces are not always clear, and it may not be obvious how namespaces should be used in various situations.
This blog post draws on our practical solutions engineering experience to explore what works and what doesn't when using namespaces for multi-tenant deployments. We’ll explain when we think namespaces are appropriate vs. inappropriate to use. Then we'll dive into real-world examples and share insights gained from tackling multiple use cases.
»What namespaces are not
Vault namespaces have a clear definition, but we’ve seen many examples of their misuse among customers. These are the use cases where you shouldn’t employ namespaces:
»A security boundary
By default, policies in Vault deny access, so an empty policy results in no permission within the system. Vault's access control list (ACL) policies uphold the principle of least privilege, including the deny-by-default posture, so namespaces do not need to be used to handle these controls.
Another area to focus on as a security boundary is your infrastructure as code (IaC) workflow, which is crucial for preventing unauthorized lateral movement within your systems.
»An onboarding strategy
Vault namespaces should be not treated as a consumption model, where users can utilize them without any kind of control. To ensure secure self-service usage of Vault, it’s essential to have a well-designed IaC pipeline and API-based onboarding process along with thoughtful Day 2+ management strategies.
One symptom of an inadequate consumption model is having empty namespaces or KV mounts. This should be avoided since they serve no purpose and reduce the space available to other tenants. To avoid this, configure the secrets engine in the same provisioning process as the resource it provides access to. This creates a more seamless lifecycle management process.
Vending namespaces is not an end goal, but merely one tool in an effective multi-tenancy solution.
»When should namespaces be used?
Here are some typical use cases for namespaces.
»Tenant segregation
Vault namespaces help you organize secrets engines, authentication mounts, policies, entities, and groups in a structured manner.
When a client authenticates at the namespace level, by default, their token can have only policies that are specified in that namespace. This behavior is particularly useful with dynamic or templated policies, ensuring that a path will never match an incorrect namespace path by mistake.
For cross-namespace access, you can add an entity from a different namespace to a group or move the authentication backend to a higher level. This requires a setting change in /sys/config/group-policy-application. However, it’s rare to have applications that need cross-namespace access. If applications are being given cross-namespace access, it may mean that the namespace strategy (or consumption) needs to be reviewed.
»Granular break-glass workflows
Administrators can leverage the namespace API to lock a specific namespace. This is similar to the process of sealing Vault, but eliminates the risk of break-glass workflows affecting multiple tenants or geographies hosted on other namespaces. This granular approach allows for more targeted and controlled access management, reducing the risk of unintended consequences.
»Setting lease limits
Lease count quotas can help ensure cluster stability by protecting the cluster against unchecked lease generation that could overwhelm the system. This setting can be set on a path, such as an auth mount or applicable to a whole namespace.
»Setting rate limits
Vault lets operators set resource quotas and apply rate limits to prevent system overloads and ensure consistent performance. This setting can be applied to any path, such as a mount or a namespace.
While rate limits manage the frequency of API requests, lease count quotas control the number of active resource permissions. Both are necessary for efficient resource management and system reliability
»Scoping performance replication
When using performance replication, namespaces can be used to scope what gets replicated to which cluster by configuring a paths-filter with an allow filter.
The following example shows a primary cluster with namespaces defined by region. Each namespace is replicated to its own individual secondary cluster. Changes in a secondary cluster are also replicated back to the primary cluster unless a mount is created as local.
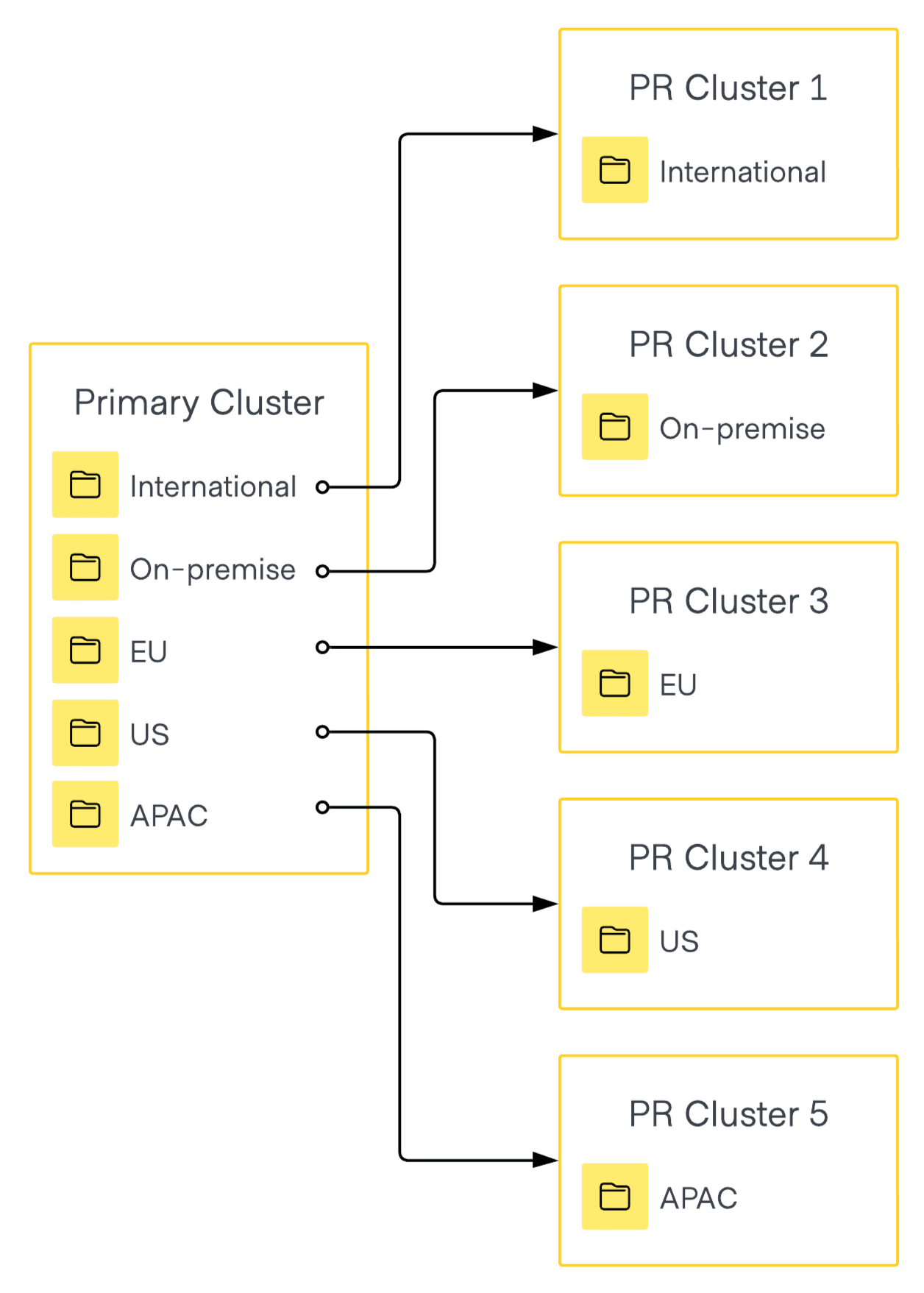
To ensure clients connect to the correct namespace on each cluster, consider using chroot in the TLS listener configuration.
»Usage cross-charging
Implementing cross-charging of the Vault license helps distribute costs fairly by allocating expenses based on actual usage. This promotes accountability and encourages resource optimization. It also contributes to better budget management and financial reporting, helping to identify and control costs.
This can be achieved by exporting the exact consumption per namespace and mount. This information, coupled with namespace metadata and mount descriptions, can be used to generate a detailed usage report to improve financial management and strategic planning.
»Exploring Vault namespace structures
There are several possible approaches to structuring Vault namespaces. The one you choose will depend on your business requirements. For example, let's look at the pros and cons of organizing namespaces by geographical region, data sensitivity levels, business unit, and application ID.
Please keep in mind the following assumptions:
- All human authentication happens at the root level
- All applications authenticate in one sub-namespace
- Applications are not expected to require cross-namespace access
»Geographical region

Organizing your namespaces by geographical region involves creating separate namespaces for each region, such as International, EU, US, APAC, and on-premises.
Pros
- Strong enforcement of data localization
- Clear communication between developers and the platform team about where data is being hosted or managed
- Customization of rate limits, policies, etc. by region
- Settings in a namespace will affect a whole cluster and not just that namespace inside a cluster
Cons
- The onboarding process and ongoing configuration management require strict oversight
- Cross-charging can be more challenging, as it needs to be processed per mount
- Changes will affect all tenants (teams and apps) in a namespace/cluster
»Data sensitivity
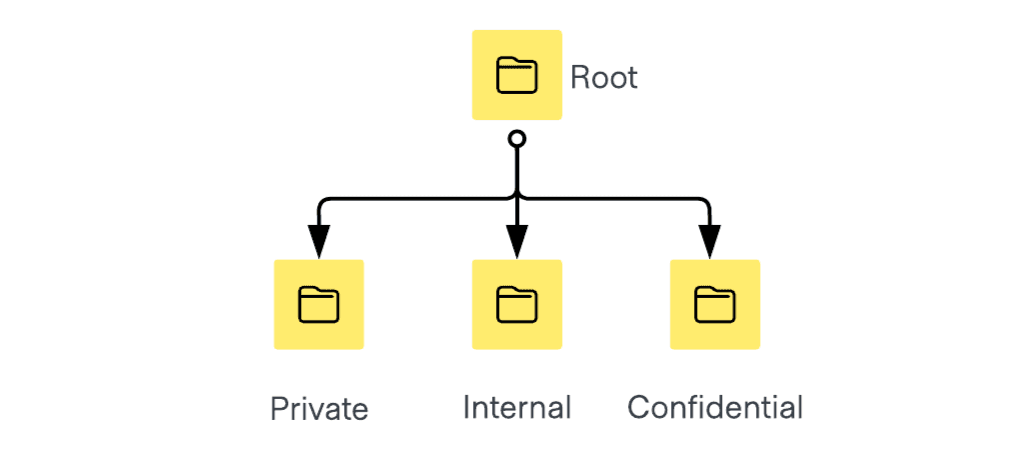
Organizing your namespaces is by data sensitivity levels involves creating separate namespaces for each level of data sensitivity, such as Private, Internal, and Confidential.
Pros
- Aligns with common regulatory data-sensitivity classifications
- Can leverage replication path filters to link data sensitivity classification with geographical localization
- Allows for easier enforcement of MFA per namespace path
- Simplifies the process of limiting or disabling human access based on the level of sensitive data they should or shouldn't have access to
Cons
- Demands tight management during onboarding and configuration
- Cross-charging remains complex, requiring processing per mount
- Changes can affect multiple tenants
»Business unit
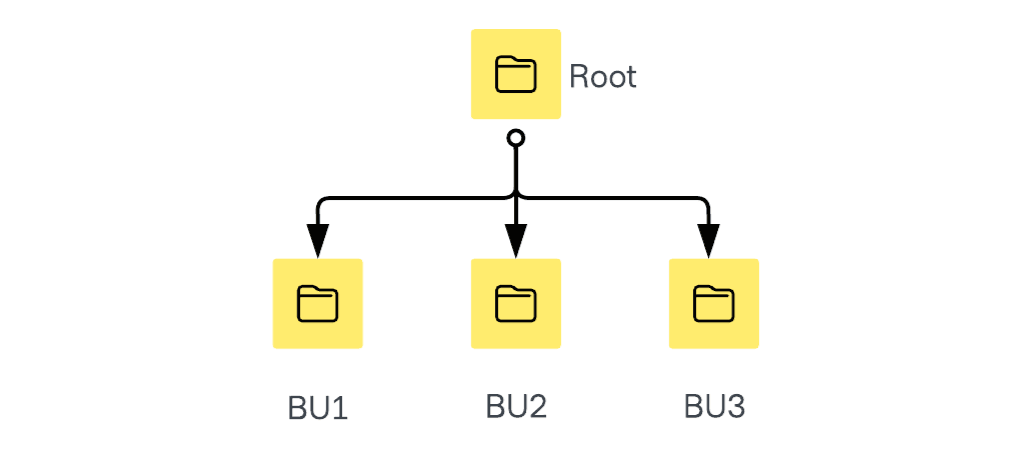
Organizing your namespaces by business unit involves creating separate namespaces for each business unit, such as BU1, BU2, and BU3.
To define what constitutes a business unit, one strategy is to count four or five levels down the org chart, starting with the CEO, and then make those teams the business units. Many other strategies could work. When adopting this structure, be mindful of mount table limits and potential future mergers and acquisitions that may lead to an increase in namespaces.
One common criticism of this approach is the fleeting nature of business unit names. However, this issue can be mitigated by treating namespace IDs as unique identifiers for each business unit, while associating metadata values such as the unit’s name, description, and cost code with the corresponding namespace. This way, even if business unit names change or are reorganized, the underlying namespace structure remains intact.
Pros
- Clearer cross-charging
- Data residency issues can be addressed per business unit needs
- Simpler to set up a self-service onboarding process because issues or outages with one team’s namespace will not affect other teams.
Cons
- It’s not trivial to decide how big business unit namespaces should be, taking into account namespace and mount limits
- Business unit names and organizational structure can change, which can confuse teams and introduce technical debt
- Relying on a namespace ID instead of a name requires some documentation overhead for developers to understand the Vault path
»Application ID
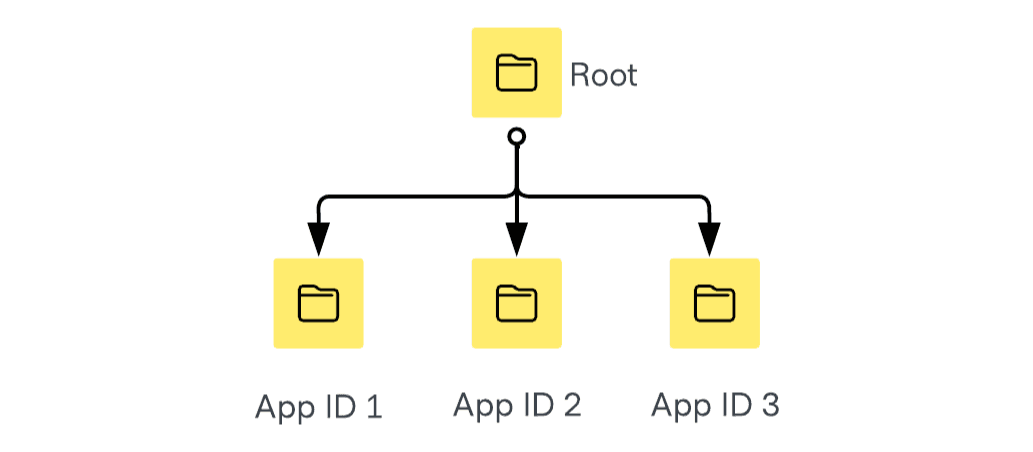
Assigning a unique namespace to each application (e.g., App ID 1, App ID 2, App ID 3) is also a popular choice. However, this approach requires several considerations to be scalable.
Pros
- Clearly defines cross-charging and responsibility for each application
- Prevents accidental access between applications due to ACL policy errors
- Changes affect only a very small number of services/applications
Cons
- Due to namespace and mount limits, managing a large number of App IDs may require sharding across multiple clusters
- Managing a large number of namespaces across multiple IaC pipelines can be complex
»What’s next?
Carefully considering these factors and selecting the most suitable structure for your needs can help you optimize your Vault usage for efficiency, security, and scalability. No matter what approach you choose, however, there are some key considerations to take into account:
»Moving to a new structure
When moving to a new structure, you have two options:
- Re-mount it all with the mount migration API.
- Set up a whole new structure, migrate applications to the new paths, and decommission the previous structure.
Either way, the migration operations will generate new clients because entities are namespaced and cannot be moved, so please reach out to your account team for help planning this work and mitigate its impact.
»Addressing the limits
There is an estimated default limit of 7,000 namespaces and approximately 14,000 mounts. These limits depend on the storage backend used, which is why it's crucial to monitor the number of mount points and size of each mount table using the vault.core.mount_table.num_entries and vault.core.mount_table.size telemetry metrics.
If your Vault cluster is deployed with a raft/integrated storage backend, it’s possible to change the table entry size for mounts and namespaces. However, before changing this, please read the Running Vault Enterprise with many namespaces guide to understand the performance considerations.
As explained earlier, creating “empty” placeholder namespaces or mounts will negatively impact the management of these limits.
»How to test different options
To experiment with different namespace approaches, start a development Vault cluster in the HashiCorp Cloud Platform (HCP) or reach out to your account team for a non-production license to use Vault Enterprise locally. This will let you test and optimize your strategies before implementing them in production environments.
For more in-depth information, check out the namespaces documentation on the HashiCorp Developer website.
Special thanks to Russ Parsloe, Lucy Davinhart, and Guy Barros for their contributions to this blog post!





